Author: Denis Avetisyan
A new approach to eligibility propagation allows recurrent spiking neural networks to learn efficiently by focusing on meaningful events, mimicking the brain’s natural processing.
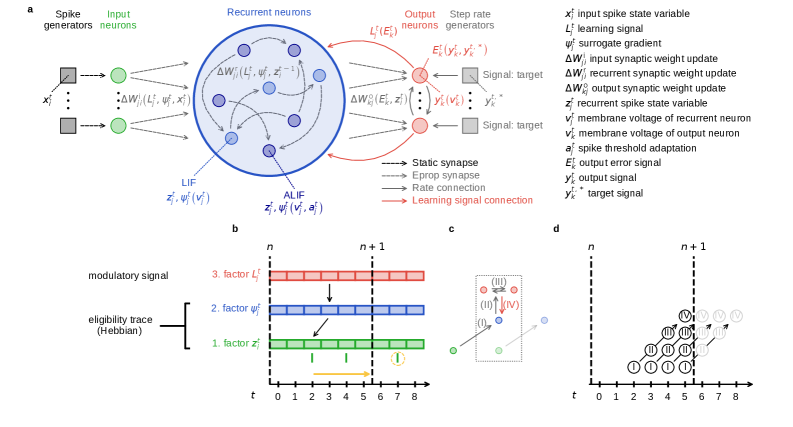
This work presents a scalable and biologically plausible event-driven extension of eligibility propagation for recurrent spiking neural networks, achieving comparable performance with improved efficiency.
Despite advances in artificial intelligence, achieving scalability and energy efficiency remains a significant challenge, particularly in complex recurrent networks. This is addressed in ‘Event-driven eligibility propagation in large sparse networks: efficiency shaped by biological realism’, which introduces a biologically plausible extension of the eligibility propagation learning rule for spiking neural networks. By shifting to an event-driven update scheme and incorporating features like sparse connectivity, the authors demonstrate comparable learning performance with improved computational efficiency across millions of neurons. Could this biologically-inspired approach pave the way for truly sustainable and scalable AI systems that more closely mirror the brain’s learning mechanisms?
Beyond the Synchronous: Embracing Event-Driven Intelligence
Contemporary deep learning models, despite achieving remarkable success in areas like image recognition and natural language processing, operate on principles fundamentally different from those governing biological brains. These artificial neural networks typically require constant, synchronous computation – every neuron potentially updating its state with every input – resulting in significant energy demands and computational overhead. This continuous processing stands in stark contrast to the brain, where neurons communicate sparsely through discrete events – spikes – and only update when triggered by relevant stimuli. The disparity highlights a critical inefficiency in current approaches; while effective, they lack the inherent energy efficiency and event-driven responsiveness that characterize biological intelligence, prompting researchers to explore radically different architectures inspired by the brain’s asynchronous, spike-based communication.
Unlike conventional artificial neural networks that operate on a principle of constant activity, biological systems exhibit remarkable efficiency through sparse processing. Neurons in the brain don’t continuously transmit signals; instead, they primarily react to meaningful events – changes in stimuli that deviate from the baseline. This event-driven approach dramatically reduces energy consumption, as computations are only performed when necessary, mirroring how the brain achieves complex tasks with minimal power. Furthermore, this asynchronous, reactive style facilitates potentially faster learning; by focusing on salient changes, the network can rapidly adapt to new information without being overwhelmed by constant, redundant updates, offering a compelling blueprint for the next generation of intelligent systems.
The shift toward event-driven computation demands a fundamental rethinking of how artificial neural networks learn. Unlike traditional methods that rely on synchronized, continuous signals, biological systems communicate through asynchronous spikes – brief electrical pulses triggered by specific events. Consequently, learning rules must evolve to accommodate this irregular timing and sparse communication. Standard gradient descent, the workhorse of deep learning, struggles with the inherent noise and lack of a clear temporal order in spike-based data. Researchers are therefore exploring novel algorithms, such as Spike-Timing-Dependent Plasticity (STDP) – a biologically plausible rule where the strength of a connection is modified based on the precise timing of pre- and post-synaptic spikes – and variations of reinforcement learning adapted for sparse rewards. These approaches aim to enable networks to learn from the when of a signal, not just the what, ultimately paving the way for more energy-efficient and adaptable artificial intelligence systems capable of processing information in a manner more akin to the brain.
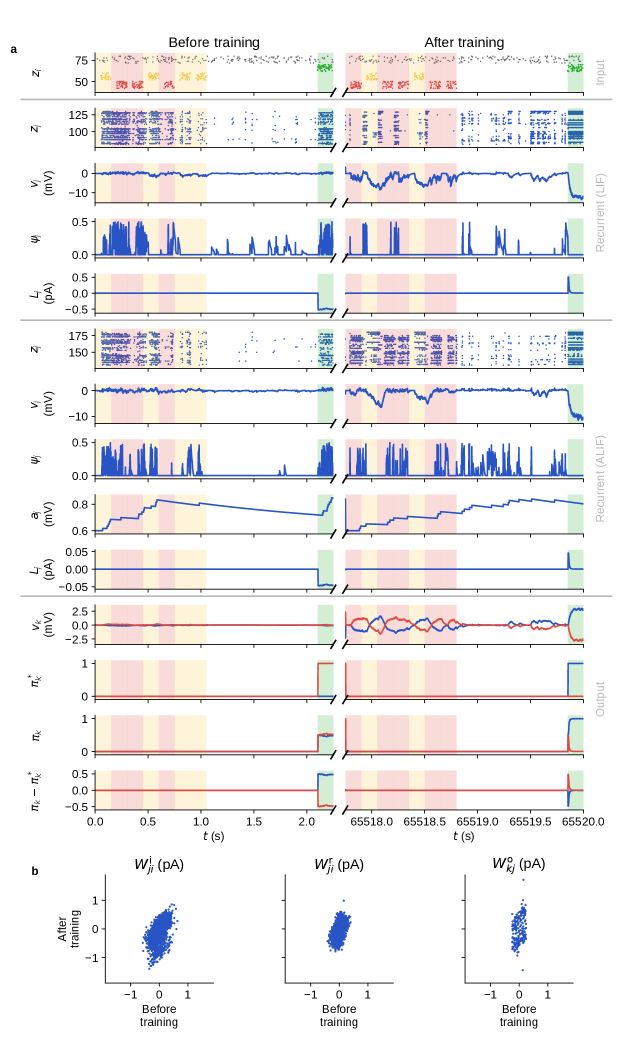
E-prop: A Local and Causal Learning Rule
The E-prop algorithm operates on an event-driven principle, updating synaptic weights strictly when both the pre- and post-synaptic neurons exhibit activity – that is, fire a spike. This contrasts with batch-based learning methods that require processing across the entire network, or time-driven methods that update weights at fixed intervals, regardless of neural activity. By selectively updating weights only upon coincident pre- and post-synaptic firing, E-prop minimizes computational cost and power consumption. This approach ensures efficient resource allocation, as only synapses involved in relevant neural computations are modified, reducing unnecessary updates and promoting faster learning in sparse spiking neural networks. The event-driven nature also allows for asynchronous updates, potentially enabling implementation on neuromorphic hardware.
Eligibility traces in the E-prop algorithm function as a short-term memory of recent neuronal activity, quantifying the contribution of each pre-synaptic neuron to post-synaptic firing. Specifically, when a pre-synaptic neuron activates, its eligibility trace is set to 1; otherwise, it decays towards 0. During post-synaptic firing, the accumulated eligibility traces of all active pre-synaptic neurons are used to scale the synaptic weights, effectively reinforcing connections deemed causally responsible for the output. This mechanism allows for credit assignment in spike-based neural networks without requiring backpropagation of gradients through time, as the trace acts as a localized record of past influence on current activity. The magnitude of the weight update is proportional to both the post-synaptic event and the accumulated pre-synaptic eligibility traces, enabling efficient and localized learning based on temporal relationships.
The local nature of the E-prop learning rule significantly streamlines implementation and enhances scalability compared to global gradient descent methods. Traditional backpropagation requires the calculation and propagation of gradients across the entire network for each weight update, creating a computational bottleneck. E-prop, however, restricts synaptic weight modifications to instances of coincident pre- and post-synaptic activity. This localized update process eliminates the need for global gradient calculations, reducing computational complexity from $O(N)$ to $O(S)$, where N is the number of connections and S is the number of spikes. Consequently, E-prop is particularly well-suited for large-scale spiking neural networks and hardware implementations where global communication and computation are limited.
Spike-based neural networks utilize discrete, non-differentiable step functions to model neuronal firing; however, standard backpropagation requires gradients. To address this, E-prop employs a surrogate gradient, replacing the step function with a differentiable approximation during gradient calculation. This allows for the propagation of error signals through the network despite the inherent non-differentiability of spiking neurons. Common surrogate gradients include the sigmoid function or a fast sigmoid, providing a smooth, differentiable substitute that maintains a similar shape to the step function, thereby enabling efficient weight updates based on downstream error signals. The surrogate gradient does not alter the forward pass of the network; it is solely used during the backward pass for gradient estimation.
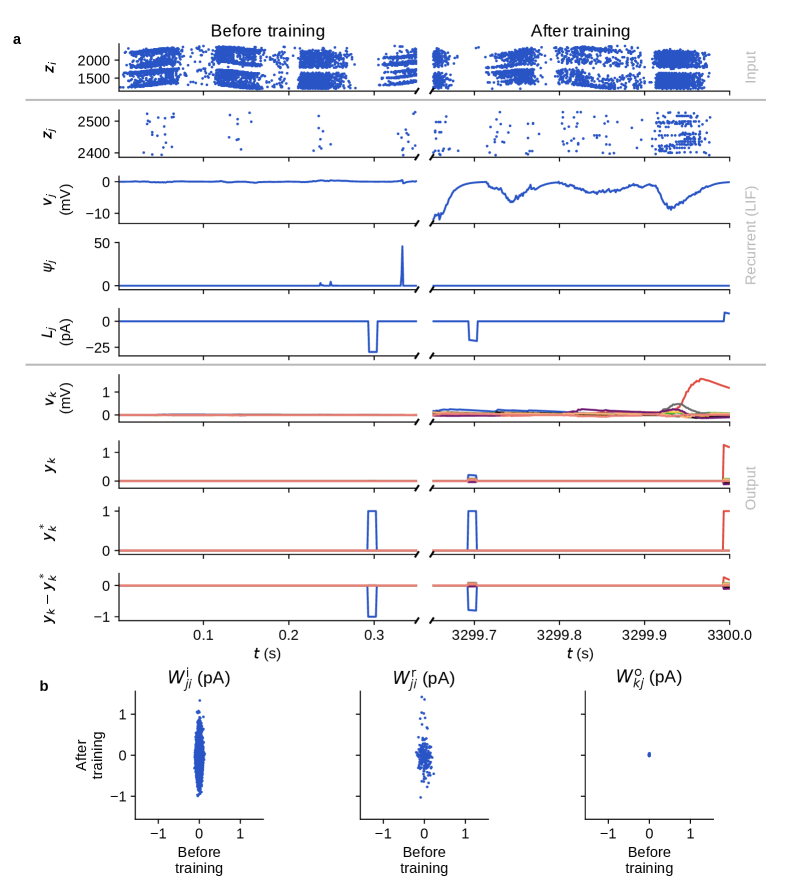
Implementing E-prop: Event-Driven Components
The E-prop algorithm’s functionality is realized through the EpropNeuron and EpropSynapse components, designed to process and update weights only upon the occurrence of spikes. Traditional backpropagation requires forward and backward passes through the network for each input; in contrast, these event-driven components enable weight updates to be triggered solely by the timing of neuronal events. The EpropNeuron component calculates and propagates postsynaptic potentials, while the EpropSynapse component manages the synaptic weights and implements the learning rule. This event-driven approach significantly reduces computational cost and power consumption by eliminating the need for continuous, synchronous updates across the entire network, aligning with the inherent efficiency of spiking neural networks.
The EpropNeuron component features an adaptive threshold that modulates neuronal firing sensitivity based on incoming input statistics. This mechanism dynamically adjusts the threshold value; increased input activity leads to a higher threshold, requiring stronger input to trigger a spike, while decreased activity lowers the threshold, increasing sensitivity. This adjustment is calculated locally within each neuron, enabling it to normalize its response to varying input rates and maintain a relatively stable output firing rate. The adaptive threshold is crucial for preventing saturation or inactivity in the network, contributing to efficient learning and robust performance in asynchronous, event-driven environments.
Spike-Timing Dependent Plasticity (STDP) is implemented to modulate synaptic weights based on the relative timing of pre- and post-synaptic spikes. Specifically, if a pre-synaptic spike consistently precedes a post-synaptic spike within a defined time window, the synapse is strengthened-a process known as Long-Term Potentiation (LTP). Conversely, if the pre-synaptic spike consistently follows the post-synaptic spike, the synapse is weakened, enacting Long-Term Depression (LTD). The magnitude of weight change is dependent on the precise timing difference, with smaller time differences generally resulting in larger weight modifications. This biologically-inspired mechanism allows the network to learn temporal correlations in input patterns, effectively reinforcing pathways associated with causal relationships and suppressing those representing spurious coincidences.
The ArchivingNode component within the E-prop implementation serves as a repository for past neuronal activity, specifically storing pre- and post-synaptic spike timings. This historical data is crucial for calculating the credit assignment signal used in the E-prop algorithm. By retaining these records, the network can effectively learn from previous events and refine synaptic weights based on a broader temporal context than immediate spike correlations. The ArchivingNode facilitates the accumulation of statistical information about spike patterns, allowing for improved performance and adaptation over time, as the algorithm leverages this data to optimize the network’s response to future inputs.
Performance and Future Trajectories
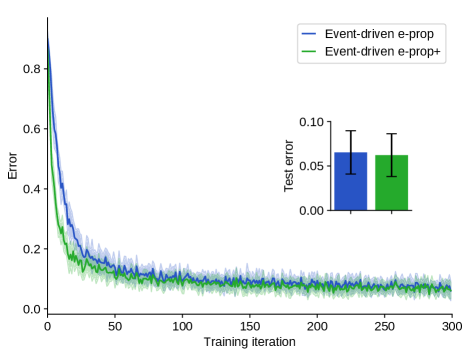
Evaluations employing the N-MNIST dataset – a challenging benchmark mimicking handwritten digit recognition – reveal that E-prop attains performance comparable to that of established deep learning techniques. Critically, this achievement is coupled with substantial energy savings, demonstrating a pathway towards more efficient artificial intelligence systems. The N-MNIST tests, designed to emulate the scale and complexity of biological neural networks, showed E-prop’s ability to accurately classify digits while consuming significantly less power than traditional approaches. This efficiency stems from the algorithm’s unique approach to synaptic updates, requiring fewer operations and allowing for the exploitation of sparsity in neural connections, ultimately positioning E-prop as a promising candidate for resource-constrained applications and large-scale neural simulations.
E-prop’s design principles align remarkably well with the constraints and capabilities of neuromorphic computing platforms. Unlike traditional deep learning, which demands dense matrix operations and substantial memory access, E-prop leverages inherent sparsity – meaning only a small fraction of connections between neurons are active at any given time – and locality, where computations are restricted to neighboring neurons. This characteristic minimizes data movement and computational demands, crucial factors for energy efficiency. Consequently, E-prop offers a pathway towards realizing ultra-low-power artificial intelligence systems by effectively mapping computations onto the event-driven, parallel architecture of neuromorphic hardware, potentially unlocking AI applications in resource-constrained environments and extending the lifespan of battery-powered devices.
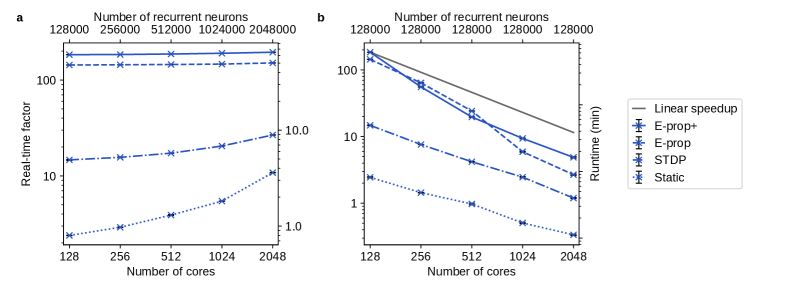
Investigations into the scalability of the E-prop framework reveal its capacity to efficiently manage networks containing millions of neurons. Performance benchmarks demonstrate a compelling trend: the system exhibits super-linear strong scaling, meaning that adding more processing cores not only maintains performance but actually accelerates it beyond what would be expected from a simple linear increase. Complementing this, the framework achieves near-linear weak scaling, indicating that performance remains consistent even as the problem size increases proportionally with the number of cores. These results suggest that E-prop is not merely a proof-of-concept, but a genuinely scalable architecture capable of tackling increasingly complex computational challenges, and establishing a pathway towards large-scale neural network deployments.
Future investigations are poised to broaden the applicability of E-prop beyond current feedforward architectures, with planned extensions targeting the complexities of recurrent neural networks. This expansion seeks to equip E-prop with the ability to process sequential data and exhibit temporal dynamics, crucial for tasks like natural language processing and time series analysis. Simultaneously, research will delve into the framework’s potential for lifelong online learning, where the network continuously adapts to new information without catastrophic forgetting. This involves developing mechanisms for incremental weight updates and synaptic plasticity, allowing E-prop to learn and refine its knowledge in a dynamic and unsupervised manner – ultimately moving closer to the adaptability and efficiency observed in biological neural systems.
The efficiency of E-prop is significantly bolstered by its implementation of sparse connectivity, a design choice that drastically reduces the computational demands of synaptic updates. Traditional neural networks often require calculations for every connection between neurons, creating a substantial bottleneck as network size increases. E-prop, however, limits connections to only those that are functionally relevant, meaning that a neuron only receives input from, and sends output to, a select few others. This sparsity not only minimizes the number of computations needed during both forward and backward passes but also contributes to improved scalability; the computational cost grows much more slowly with network size compared to densely connected architectures. Consequently, E-prop achieves comparable performance to conventional deep learning with a reduced energy footprint and the potential to operate effectively on resource-constrained hardware.
The pursuit of efficient computation, as demonstrated in this work on event-driven eligibility propagation, echoes a fundamental tenet of intelligent system design. It prioritizes streamlined processes, mirroring the brain’s inherent economy. As Marvin Minsky observed, “The more general a machine, the less effective it is.” This paper elegantly illustrates that point; by focusing on biologically plausible, sparse event-driven networks, the researchers achieve comparable learning performance to traditional methods with significantly reduced computational cost. The elegance lies not in adding complexity, but in recognizing and removing superfluous operations – a principle of respect for the limited attention of any system, artificial or biological.
The Road Ahead
The pursuit of biologically plausible learning rules often culminates in architectures of impressive, yet fragile, complexity. This work, commendably, resists that urge. It demonstrates that efficiency gains are not solely the domain of increasingly elaborate mechanisms, but can arise from a more honest adherence to the constraints inherent in the biological systems that inspired the model. However, the true test lies beyond performance benchmarks. The elegance of event-driven computation is self-evident, but its robustness in genuinely noisy, unpredictable environments remains an open question.
Future iterations should grapple with the thorny issue of credit assignment in deeper, more recurrent networks. Current approaches, while functional, still lean heavily on global synchrony, a concession that feels increasingly less plausible given the brain’s decentralized architecture. Perhaps the answer doesn’t lie in perfecting eligibility propagation, but in abandoning the notion of a single, unified credit signal altogether.
Ultimately, the value of this work resides not in what it achieves today, but in the questions it forces one to ask. It’s a reminder that simplicity isn’t merely a stylistic preference; it’s a necessary condition for understanding. The field should be wary of frameworks built to obscure fundamental limitations, and instead embrace the clarity that comes from acknowledging them.
Original article: https://arxiv.org/pdf/2511.21674.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- Mobile Legends January 2026 Leaks: Upcoming new skins, heroes, events and more
- World Eternal Online promo codes and how to use them (September 2025)
- How to find the Roaming Oak Tree in Heartopia
- Clash Royale Season 79 “Fire and Ice” January 2026 Update and Balance Changes
- Clash Royale Furnace Evolution best decks guide
- Best Arena 9 Decks in Clast Royale
- Best Hero Card Decks in Clash Royale
- FC Mobile 26: EA opens voting for its official Team of the Year (TOTY)
2025-11-27 19:11