Author: Denis Avetisyan
A new benchmark and multi-agent system approach demonstrate promising advances in artificial intelligence’s ability to tackle complex scientific reasoning challenges in heliophysics.

Researchers introduce Reasoning With a Star, a dataset for evaluating and improving AI’s capacity for scientific discovery in the field of solar physics.
While large language models show promise in scientific domains, true reasoning requires more than recall-demanding physical understanding, consistent units, and structured outputs. To address this, we present ‘Reasoning With a Star: A Heliophysics Dataset and Benchmark for Agentic Scientific Reasoning’, introducing a new heliophysics dataset and evaluation framework designed to rigorously test agentic scientific reasoning. Our results demonstrate that decomposing complex problems with multi-agent systems outperforms direct prompting, though no single coordination strategy consistently excels. Can these findings inform the development of more robust and reliable LLM-based tools for scientific discovery?
The Challenge of Complex Reasoning
Large Language Models demonstrate remarkable proficiency in identifying and replicating patterns within data, a capability that underpins their success in tasks like text completion and translation. However, this strength often plateaus when confronted with problems demanding sustained logical inference – tasks that require chaining together multiple reasoning steps to arrive at a solution. Unlike pattern recognition, which relies on identifying existing relationships, multi-step reasoning necessitates the creation of new logical connections. The models frequently falter not because they lack information, but because they struggle to maintain a coherent line of thought across several interconnected deductions. This limitation highlights a fundamental difference between statistical learning and genuine reasoning, suggesting that current architectures may require significant advancements to achieve robust performance in complex, multi-step problem-solving scenarios, particularly those found in fields like mathematics and scientific inquiry.
Current evaluations of Large Language Models (LLMs), notably through benchmarks like GSM8K and MATH, consistently reveal limitations in their ability to solve complex, multi-step problems-particularly those rooted in scientific or mathematical reasoning. GSM8K, focused on grade school math, and MATH, encompassing high school level problems, don’t merely test recall; they demand a sustained chain of logical inference to arrive at correct solutions. LLMs frequently falter not because they lack relevant knowledge, but because they struggle to maintain coherence and accuracy across multiple reasoning steps. These benchmarks highlight a crucial gap: while LLMs demonstrate proficiency in identifying patterns and generating plausible text, they often fail when confronted with problems requiring deliberate, structured thought-underscoring the need for advancements beyond simple pattern completion towards genuine reasoning capabilities.
The limitations of current Large Language Models in complex reasoning necessitate a shift towards fundamentally new architectural designs. Existing models, proficient in identifying correlations within data, often falter when presented with problems demanding sequential inference and sustained logical steps – a clear indication that simple pattern completion is insufficient for genuine problem-solving. Researchers are actively exploring alternatives, including systems that incorporate explicit memory components, symbolic reasoning engines, or modular networks capable of breaking down complex tasks into manageable sub-problems. These emerging architectures aim to move beyond statistical prediction and towards a more robust and interpretable form of artificial intelligence, one capable of not just recognizing patterns, but truly understanding and solving challenging problems that require deeper cognitive abilities.
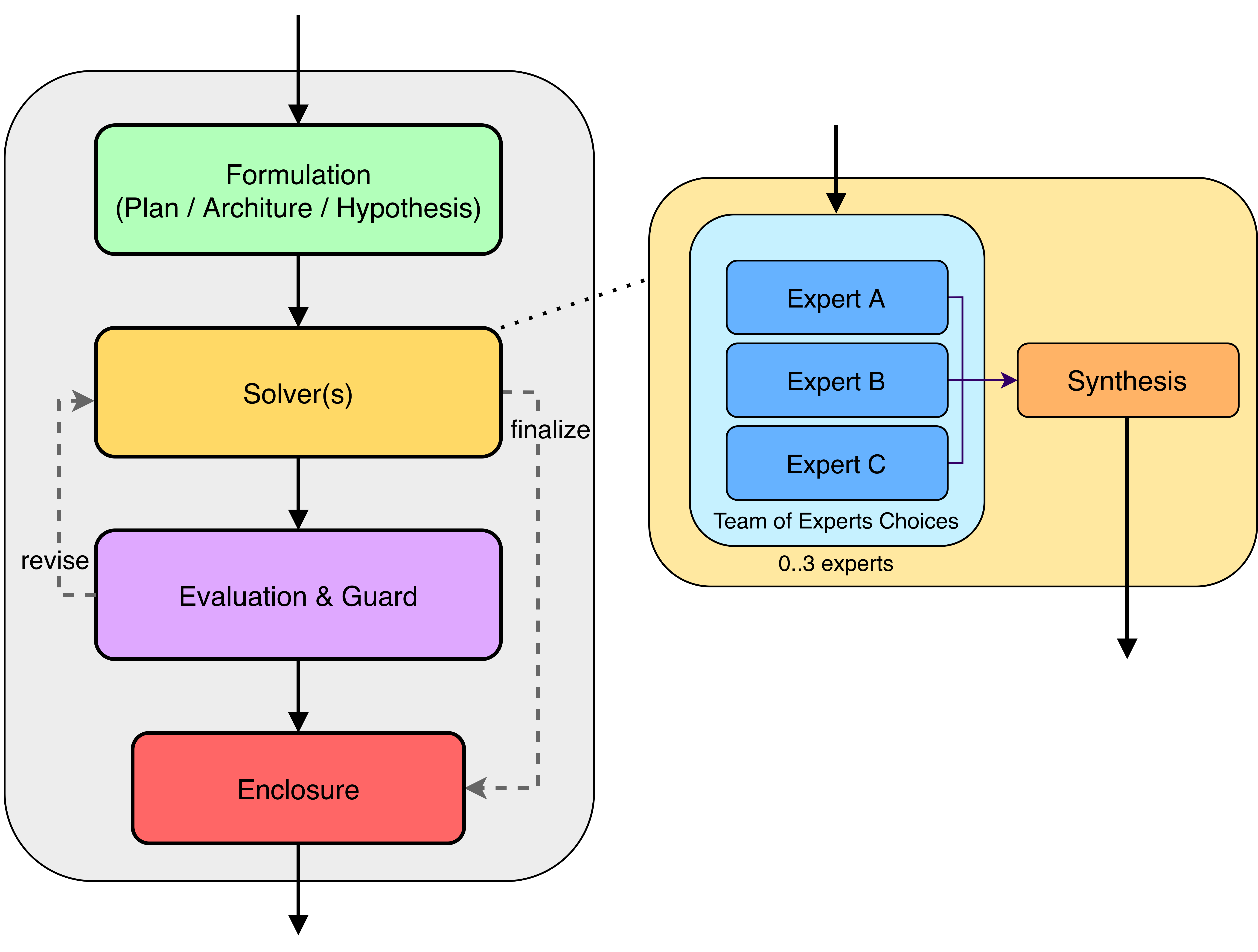
Decomposing Complexity: An Agent-Based Approach
Agent-based reasoning represents a departure from large, monolithic language models (LLMs) by addressing complex tasks through decomposition. Instead of a single model attempting to solve an entire problem, this paradigm utilizes multiple specialized agents, each responsible for a specific sub-task. These agents operate autonomously, communicating and coordinating to achieve a common goal. This modular approach allows for increased flexibility, scalability, and interpretability, as each agent’s function is clearly defined. Furthermore, it facilitates the application of targeted expertise; an agent designed for data analysis, for example, can leverage specific tools and algorithms optimized for that task, potentially exceeding the performance of a general-purpose LLM attempting the same operation. This decomposition also enables easier debugging and refinement of the overall system.
The Reasoning With a Star (RWS) benchmark is designed to assess agent-based reasoning systems within the domain of heliophysics – the study of the Sun and its influence on the solar system. Unlike typical question answering datasets, RWS presents scenarios requiring multi-step reasoning to solve complex, open-ended problems related to solar flares, coronal mass ejections, and space weather prediction. The benchmark utilizes a knowledge base derived from scientific literature and observational data, demanding that agents not only retrieve information but also synthesize it to formulate hypotheses, analyze data from virtual instruments, and iteratively refine their understanding of dynamic solar events. RWS tasks specifically require agents to perform tasks such as identifying the source region of a solar event, predicting its trajectory, and assessing its potential impact on Earth, thereby simulating the workflow of a heliophysicist.
The Reasoning With a Star (RWS) benchmark presents a significant challenge to current AI systems by requiring capabilities exceeding those of typical question-answering models. Successful performance on RWS tasks necessitates a multi-step approach where agents must first develop a plan to address the given heliophysics problem. This involves not only identifying relevant data sources, but also analyzing complex, time-series datasets to extract meaningful features. Critically, RWS demands iterative refinement of solutions; agents must evaluate the results of initial steps, adjust their plans based on observed outcomes, and repeat the process until a satisfactory answer is achieved. This cycle of planning, data analysis, and refinement distinguishes RWS from tasks solvable by simple information retrieval or pattern matching.

Architectures for Collaborative Reasoning
Hierarchical Multi-Agent Workflow (HMAW) establishes a basic structure for collaborative reasoning by dividing complex tasks into sub-tasks assigned to individual agents within a defined hierarchy. Subsequent architectures build upon this foundation; PHASE (Planning, Hypothesis, Analysis, Synthesis, Evaluation) explicitly incorporates a cyclical process focused on hypothesis generation and refinement, allowing agents to iteratively develop and test potential solutions. PACE (Plan, Act, Critique, Evaluate) further emphasizes self-assessment, integrating a dedicated critique stage where agents analyze their own reasoning and outputs to identify and correct errors, thereby improving overall performance and reliability. These patterns move beyond simple task division to actively foster a more dynamic and self-improving collaborative process.
The Systems-engineering-of-Thoughts (STAR) architecture applies principles from Model-Based Systems Engineering (MBSE) to multi-agent reasoning. This approach defines agents as components within a larger system, emphasizing explicit modeling of requirements, interfaces, and dependencies between agents. By formalizing the reasoning process as a system, STAR facilitates rigorous verification and validation of conclusions, improves traceability of information flow, and enables more effective coordination and error detection compared to less structured architectures. The resulting framework is designed to be particularly resilient and scalable for complex reasoning tasks requiring contributions from multiple agents.
The Systems-engineering-of-Thoughts (STAR) architecture incorporates the SCHEMA expert system as a core component for managing the complexities of multi-agent reasoning. SCHEMA facilitates requirement tracking by formally representing and linking reasoning objectives, intermediate conclusions, and supporting evidence. This ensures consistency throughout the reasoning process by enforcing adherence to pre-defined constraints and detecting potential conflicts between different agent contributions. Specifically, SCHEMA maintains a knowledge graph of requirements and their relationships, enabling agents to verify that each step in the reasoning process directly addresses established needs and avoids logical fallacies. The system’s ability to trace the provenance of information is crucial for debugging and validating the final outcome.

Validating Agentic Reasoning with RWS
Current benchmarks for evaluating artificial intelligence, such as HumanEval, GPQA, and SWE-bench, often fail to distinguish between systems that genuinely reason and those that simply mimic reasoning through pattern recognition – a limitation readily exploited by large language models. The recently developed Reasoning with Symbols (RWS) benchmark addresses this shortcoming by specifically testing an agent’s ability to manipulate symbolic representations and apply logical deduction to solve complex problems. Unlike prior evaluations, RWS necessitates a deeper understanding of underlying principles rather than statistical correlations within training data, thereby exposing the limitations of LLMs when confronted with tasks requiring true agentic reasoning and highlighting the unique capabilities of systems designed with explicit reasoning mechanisms.
The Reliable Workspace (RWS) benchmark incorporates a programmatic grader that moves beyond simple test-case pass/fail metrics, instead evaluating solutions based on symbolic equivalence. This approach ensures that an answer isn’t merely coincidentally correct for a given input, but fundamentally represents the same mathematical or logical operation as the expected solution. By rigorously verifying the underlying reasoning, rather than surface-level output, the grader delivers objective and reproducible results, mitigating the influence of subtle variations in formatting or wording. This method is crucial for accurately assessing the true capabilities of agent-based systems and distinguishing genuine reasoning ability from pattern-matching tendencies often exhibited by large language models, offering a far more robust evaluation framework than traditional benchmarks.
Recent validation using the RWS benchmark demonstrates a significant capability of agent-based systems in addressing complex reasoning challenges, particularly within the field of heliophysics. These systems consistently outperform standard large language models (LLMs) when tackling problems requiring multi-step inference and symbolic manipulation-tasks currently beyond the reach of most single-shot LLM approaches. The success isn’t limited to a single architecture; diverse multi-agent strategies, each employing different coordination patterns, all exhibit superior performance. This finding suggests that the decomposition of complex problems into smaller, manageable steps, facilitated by the interactions between specialized agents, is a crucial factor in achieving robust and accurate reasoning, opening new avenues for tackling previously intractable scientific questions.
Evaluations reveal a nuanced landscape of performance, where distinct coordination patterns excel on specific reasoning tasks. PACE consistently achieves state-of-the-art accuracy on the GSM8K and MATH benchmarks, both demanding complex mathematical problem-solving; conversely, HMAW demonstrates superior capabilities in the realm of general problem-solving as evidenced by its leading performance on GPQA. Notably, SCHEMA emerges as the most versatile strategy, consistently outperforming alternatives on HumanEval, SWE-bench Verified, and the challenging heliophysics benchmark, RWS. These results underscore that the effectiveness of multi-agent systems isn’t solely determined by their architecture, but critically by how agents coordinate; different coordination patterns unlock varying strengths, highlighting the importance of task-specific optimization in agent-based reasoning.
Future Directions: Scaling and Generalization
Future advancements in agentic systems necessitate a shift towards scalability and broad applicability. Current research indicates that expanding the capacity of these systems to tackle increasingly intricate challenges requires not only computational power but also innovative architectural designs. A key focus lies in developing methods that allow agents to transfer knowledge and skills acquired in one domain to entirely new and unrelated problems – a capability crucial for real-world deployment. This generalization isn’t simply about adapting to new data; it demands a fundamental understanding of underlying principles and the ability to reason abstractly. Consequently, investigations are underway to create agents capable of learning meta-strategies – essentially, learning how to learn – allowing them to rapidly assimilate new information and solve problems without extensive retraining. The ultimate goal is to move beyond narrow, task-specific agents towards systems exhibiting genuine cognitive flexibility and adaptability, capable of autonomous problem-solving across a wide spectrum of scientific and practical domains.
Advancing the capabilities of multi-agent systems necessitates a dedicated exploration of innovative architectures and communication strategies. Current systems often face limitations in both computational efficiency and adaptability when confronted with dynamic or unforeseen circumstances; therefore, research is concentrating on designs that move beyond centralized control and embrace decentralized, asynchronous interactions. Investigations into emergent communication protocols-where agents develop shared languages without explicit programming-hold particular promise for enhancing robustness and enabling effective collaboration in complex environments. These novel approaches aim to reduce reliance on pre-defined knowledge, allowing agents to learn and adapt more effectively, ultimately leading to more scalable and resilient intelligent systems capable of tackling increasingly sophisticated challenges.
Recent work with Recursive Warping Systems (RWS) signifies a paradigm shift in computational problem-solving, illustrating the power of distributing reasoning across multiple autonomous agents. This approach transcends traditional monolithic AI by enabling a system to tackle complex challenges through iterative refinement and collaborative exploration of solution spaces. The demonstrated success in scientific domains – particularly in areas requiring both creativity and precision – suggests that agent-based reasoning isn’t merely a technical advancement, but a fundamental step towards creating genuinely intelligent systems capable of independent thought and adaptation. By mimicking the distributed cognitive processes observed in natural intelligence, RWS offers a promising pathway for building AI that is not only powerful but also robust, flexible, and capable of generalizing knowledge to previously unseen problems, ultimately extending the reach of automated reasoning far beyond its current limitations.
The pursuit of robust scientific reasoning, as demonstrated by the ‘Reasoning With a Star’ benchmark, necessitates a holistic understanding of complex systems. This mirrors a fundamental principle of effective design-that structure dictates behavior. The study highlights how multi-agent systems, while promising, lack a singular superior coordination strategy, suggesting that optimization isn’t about maximizing one element, but understanding the interplay between all components. As Tim Bern-Lee aptly stated, “The Web is more a social creation than a technical one,” underscoring that even technically driven endeavors are inherently shaped by the interactions within their systems – a truth powerfully illustrated by the RWS benchmark and its exploration of agentic collaboration.
Looking Ahead
The introduction of Reasoning With a Star reveals, perhaps predictably, that automated scientific reasoning remains a problem of system architecture, not merely algorithmic cleverness. Demonstrating that multi-agent systems can improve performance with this heliophysics dataset sidesteps the more pressing question: which organizational principle best guides such a system? The lack of a universally superior coordination strategy suggests that optimal performance will likely be context-dependent, necessitating a shift from seeking a ‘best’ agent architecture to understanding the trade-offs inherent in each. Every simplification of the problem space, every shortcut taken in coordination, carries a cost in potential insight.
Future work must therefore focus on the meta-level: designing systems capable of selecting the appropriate coordination strategy based on the characteristics of the scientific problem itself. This necessitates a formalization of ‘problem structure’ – an understanding of how different types of scientific inquiry demand different organizational responses. Such a framework might draw inspiration from systems engineering principles, emphasizing modularity, feedback loops, and the careful management of complexity.
Ultimately, the value of benchmarks like RWS lies not in achieving a single ‘solved’ problem, but in exposing the limitations of current approaches. The field should embrace the inherent messiness of scientific inquiry, recognizing that progress often comes from navigating a landscape of imperfect solutions and carefully considered compromises.
Original article: https://arxiv.org/pdf/2511.20694.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- Mobile Legends January 2026 Leaks: Upcoming new skins, heroes, events and more
- World Eternal Online promo codes and how to use them (September 2025)
- Clash Royale Season 79 “Fire and Ice” January 2026 Update and Balance Changes
- Clash Royale Furnace Evolution best decks guide
- How to find the Roaming Oak Tree in Heartopia
- Best Arena 9 Decks in Clast Royale
- FC Mobile 26: EA opens voting for its official Team of the Year (TOTY)
- Best Hero Card Decks in Clash Royale
2025-11-27 13:59