Author: Denis Avetisyan
Researchers have developed a novel framework that allows agents to independently generate challenges, learn from experience, and refine their capabilities without constant human oversight.

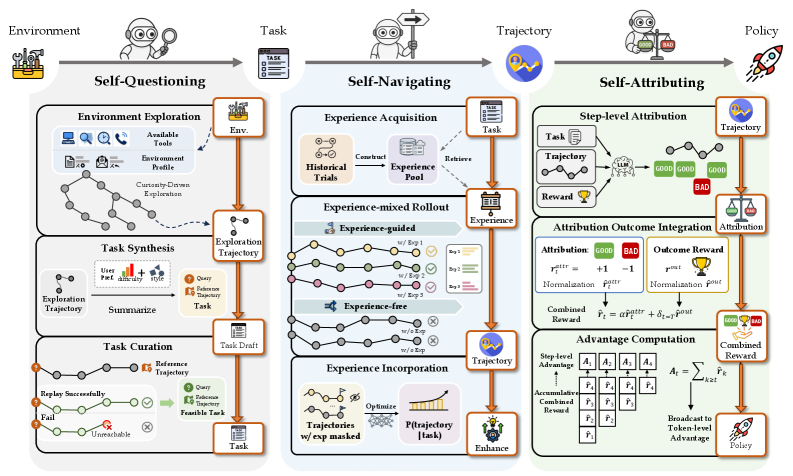
AgentEvolver leverages large language models and reinforcement learning to enable autonomous task generation, exploration, and credit assignment for improved learning efficiency.
Despite the promise of autonomous agents powered by large language models, current development relies on costly, manually-constructed datasets and inefficient reinforcement learning pipelines. This paper introduces AgentEvolver: Towards Efficient Self-Evolving Agent System, a novel framework designed to overcome these limitations through autonomous learning. AgentEvolver achieves improved sample efficiency and adaptability by integrating self-questioning for task generation, self-navigating for efficient exploration, and self-attributing for refined credit assignment. Could this self-evolving approach unlock truly scalable and continual learning for intelligent agents operating in complex environments?
The Imperative of Dynamic Context
Traditional agents falter in complex dialogues due to limited pre-training and contextual awareness, exhibiting rigid behavior and an inability to integrate information. This results in incoherence and diminished engagement. Effective reasoning demands a system capable of dynamically maintaining and evolving its understanding—a ‘Live Context Timeline’—serving as a persistent record to track information, identify key topics, and anticipate future turns. The challenge isn’t merely storage, but discerning signal from noise – a calibration of observation and calculation.

AgentEvolver: A Framework for Autonomous Adaptation
AgentEvolver introduces a self-evolving agent framework enabling autonomous capability evolution through environmental interaction, moving beyond pre-defined reward functions. Central to this is the ‘Context Manager’, leveraging the ‘Live Context Timeline’ and ‘Timeline Snapshot Recorder’ to dynamically track and recall relevant information. This architecture facilitates a rich understanding of the agent’s environment and actions, enabling adaptation based on unfolding dialogues and prior experiences, promoting robust and coherent interactions.
Self-Improvement Through Principled Optimization
AgentEvolver incorporates mechanisms for self-improvement, including ‘Self-Navigating’ for efficient exploration and ‘Self-Attributing’ for reward allocation based on trajectory quality. The ‘Self-Attributing’ mechanism utilizes an ‘LLM Judge’ for nuanced feedback, enabling autonomous learning without external reward functions. Experimental results demonstrate a 29.4% improvement in avg@8 and 36.1% in best@8 for the 7B model, and 27.8% and 30.3% for the 14B model, indicating a 29.4% increase in Task Goal Completion (TGC) and 36.1% in Scenario Goal Completion (SGC) for the 7B model.

Scalable Infrastructure and Future Directions in Autonomous Learning
AgentEvolver’s computational demands are met through a scalable ‘Environment Service’ built on the Ray distributed execution framework, accelerating both training and evaluation. The system prioritizes efficient resource allocation and parallel processing. The agent’s reasoning capabilities are grounded in the Qwen2.5 large language model, fine-tuned during evolution to optimize performance. Future work will refine ‘Self-Questioning’ techniques to enhance the agent’s intrinsic curiosity and learning agility, enabling proactive exploration and independent objective formulation.

In the chaos of data, only mathematical discipline endures.
The pursuit of autonomous systems, as demonstrated by AgentEvolver, necessitates a rigorous approach to problem-solving. The framework’s capacity for self-evolution—generating tasks, guiding exploration, and refining learning—mirrors a dedication to provable correctness. As Alan Turing observed, “Sometimes people who are unhappy tend to look at the world as if there is something wrong with it.” This sentiment extends to the development of AI; imperfections are not inherent flaws in the world, but challenges demanding analytical dissection and refinement. AgentEvolver’s mechanisms, like self-questioning and self-attributing, are not merely heuristics but attempts to establish invariants—to create a system where progress is demonstrable and not simply observed through empirical results. The elegance of the design lies in its systematic approach to minimizing uncertainty and maximizing the likelihood of a demonstrably ‘correct’ outcome, echoing a mathematical ideal.
What’s Next?
The pursuit of self-evolving agents, as demonstrated by AgentEvolver, predictably encounters the familiar specter of practical limitation. While the framework exhibits promise in autonomous task generation and refinement, the underlying reliance on Large Language Models introduces an inherent, and largely unaddressed, fragility. The ‘correctness’ of self-generated tasks remains a statistical likelihood, not a mathematical certainty. A system built on probabilistic foundations, no matter how elegantly constructed, will always be susceptible to cascading errors stemming from initial imperfections in the foundational model.
Future work must therefore shift focus from merely achieving self-evolution to verifying it. The question is not simply whether an agent can learn, but whether its learning process is demonstrably converging towards an optimal, or at least locally stable, solution. Formal methods, perhaps drawing from program verification techniques, should be explored to establish guarantees about the agent’s behavior, independent of empirical performance. The elegance of an algorithm is not measured by its ability to pass a test suite, but by its adherence to logical consistency.
Ultimately, the true challenge lies in decoupling intelligence from brute-force computation. AgentEvolver represents a step towards this goal, but it remains a pragmatic, rather than a purely theoretical, advancement. The next iteration must strive for a system where self-improvement is not simply a matter of trial and error, but a consequence of inherent mathematical properties.
Original article: https://arxiv.org/pdf/2511.10395.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- World Eternal Online promo codes and how to use them (September 2025)
- Best Arena 9 Decks in Clast Royale
- How to find the Roaming Oak Tree in Heartopia
- Country star who vanished from the spotlight 25 years ago resurfaces with viral Jessie James Decker duet
- Mobile Legends January 2026 Leaks: Upcoming new skins, heroes, events and more
- M7 Pass Event Guide: All you need to know
- Solo Leveling Season 3 release date and details: “It may continue or it may not. Personally, I really hope that it does.”
- Kingdoms of Desire turns the Three Kingdoms era into an idle RPG power fantasy, now globally available
2025-11-15 02:02