Author: Denis Avetisyan
New research reveals that physician trust in AI-assisted diagnosis hinges on more than just getting the right answer.
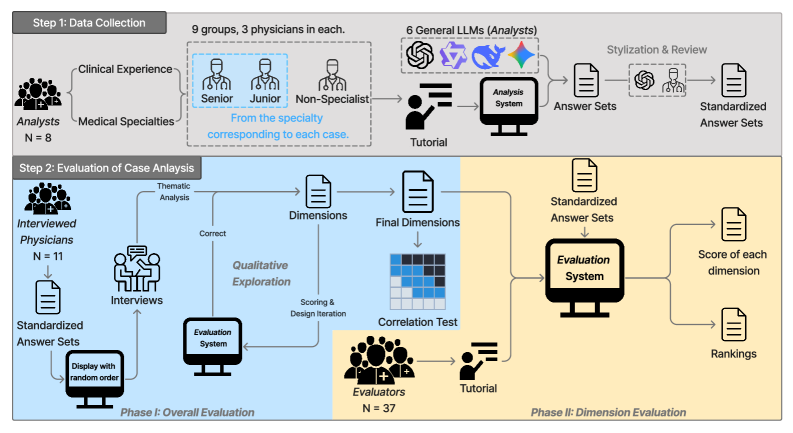
A study examining the influence of logical coherence, clinical feasibility, and perceived capability on trust calibration in Large Language Model-supported clinical reasoning.
While large language models (LLMs) demonstrate promise in medical diagnosis, their successful clinical integration hinges on physician trust-a factor often miscalibrated due to discrepancies between benchmark performance and perceived capability. This research, presented in “Do I Trust the AI?” Towards Trustworthy AI-Assisted Diagnosis: Understanding User Perception in LLM-Supported Reasoning, investigates how physicians evaluate LLMs’ clinical reasoning, revealing that factors beyond diagnostic accuracy-such as logical coherence and clinical feasibility-significantly influence their perceptions. Analyzing evaluations from [latex]\mathcal{N}=37[/latex] physicians, our study highlights the limitations of current benchmark-based evaluations and identifies key dimensions for fostering trustworthy human-AI collaboration. How can we better align LLM development with the nuanced reasoning processes valued by clinicians to unlock the full potential of AI-assisted diagnosis?
The Illusion of Diagnostic Reasoning
Large Language Models demonstrate an impressive capacity for absorbing and processing vast quantities of medical data, excelling at tasks like identifying correlations between symptoms and potential diagnoses. However, this proficiency shouldn’t be mistaken for genuine clinical reasoning. True diagnostic skill involves constructing a cohesive and logically sound investigative pathway – a process of hypothesis generation, targeted questioning, and iterative refinement based on evolving evidence. LLMs, currently reliant on statistical pattern matching within their training data, often lack this crucial ability to understand the underlying pathophysiology or to justify their conclusions beyond simply identifying frequent co-occurrences. While they can suggest possibilities, they struggle with the nuanced, contextual judgment necessary to prioritize investigations, account for individual patient factors, or recognize the limitations of available information – elements central to safe and effective clinical practice.
The process of accurate diagnosis extends beyond simply identifying patterns; it demands a structured, logical progression of thought – a coherent line of inquiry that justifies each step towards a conclusion. Current Large Language Models, while adept at recognizing correlations within vast datasets, lack this inherent capability. These models operate primarily through statistical association, predicting likely diagnoses based on input data without necessarily understanding why a particular conclusion is warranted. This contrasts sharply with clinical reasoning, where physicians formulate hypotheses, actively seek evidence to support or refute them, and revise their thinking based on new information – a dynamic process of justification that is not automatically replicated by LLM architectures. Consequently, while LLMs can assist in diagnosis, they currently struggle to provide the transparent, explainable reasoning essential for building clinician trust and ensuring patient safety.
The implementation of Large Language Models in clinical settings demands meticulous scrutiny, as their potential for flawed or opaque reasoning presents tangible risks to patient well-being and erodes confidence in medical practice. While capable of processing vast amounts of data, these models can arrive at diagnoses or treatment recommendations without a transparent or justifiable rationale, hindering a physician’s ability to validate the logic behind the suggestion. This lack of explainability isn’t merely an inconvenience; it introduces the possibility of undetected errors stemming from biased data, algorithmic limitations, or spurious correlations, potentially leading to misdiagnosis or inappropriate care. Consequently, robust evaluation frameworks – assessing not only accuracy but also the coherence and defensibility of the reasoning process – are paramount to ensure responsible integration and maintain the crucial trust patients place in healthcare professionals.
![This interface supports case analysis by enabling users to gather evidence through dialogue with a virtual patient [latex] (A) [/latex], document diagnostic reasoning [latex] (B) [/latex], and record treatment plans [latex] (C) [/latex].](https://arxiv.org/html/2601.19540v1/x2.png)
Evaluating Diagnostic Accuracy: A Matter of Rigor
Traditional benchmark evaluation of Large Language Models (LLMs) in medical contexts utilizes standardized datasets to establish a baseline for performance assessment. These datasets, comprised of curated patient cases and associated diagnostic information, allow for quantifiable metrics such as accuracy, sensitivity, and specificity to be calculated. Common datasets include those focused on radiology reports, clinical notes, and medical question answering. While providing a readily comparable metric, it’s important to note that benchmark scores represent performance on a specific, pre-defined task and may not fully reflect the model’s capabilities in more complex, ambiguous, or novel clinical situations. The primary function of these benchmarks is to offer a consistent, objective starting point for iterative model improvement and comparative analysis.
Traditional medical benchmark datasets, while providing initial performance indicators, frequently lack the complexity inherent in actual clinical practice. These datasets often present simplified cases with clearly defined parameters, failing to account for the ambiguity, incomplete information, and contextual factors commonly encountered by physicians. Consequently, high performance on benchmarks does not guarantee reliable performance in real-world scenarios where patient histories are nuanced, symptoms are atypical, and diagnostic reasoning requires integration of diverse data sources. More sophisticated testing methods, including case-based evaluations simulating complex clinical presentations and incorporating expert physician review, are therefore necessary to accurately assess the diagnostic capabilities of Large Language Models (LLMs) intended for clinical application.
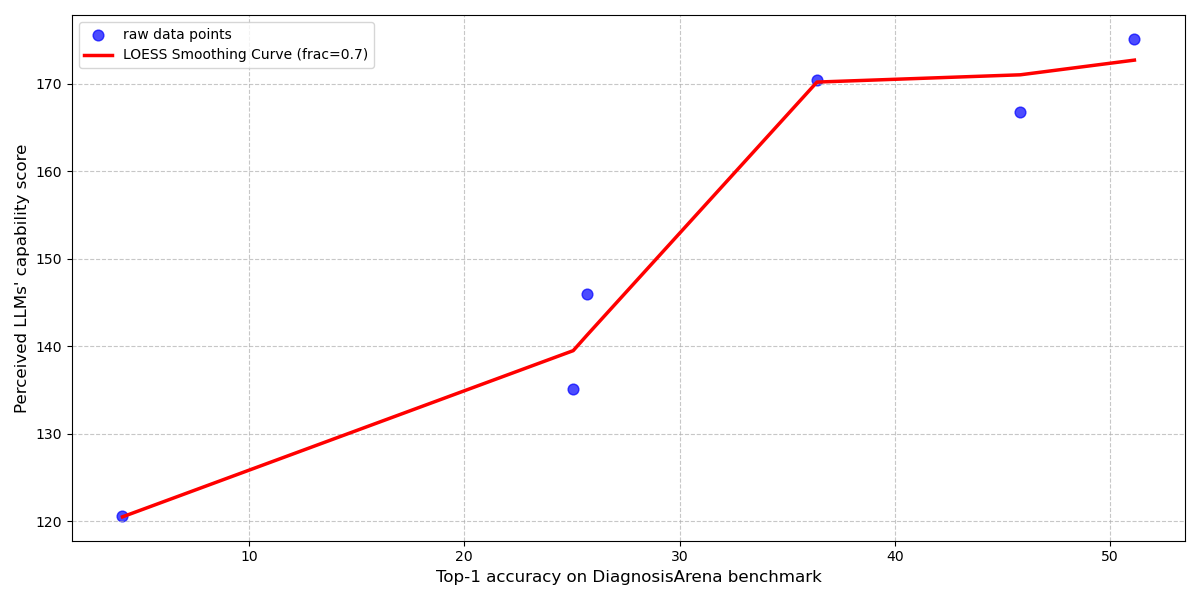
Diagnostic accuracy of Large Language Models (LLMs) in clinical reasoning tasks demonstrates a strong correlation with physician assessment of the model’s capability. Analysis reveals a Pearson R-squared value of 0.97, calculated using a Locally Estimated Scatterplot Smoothing (LOESS) fit, between benchmark diagnostic accuracy scores and physician-perceived capability. This statistically significant relationship indicates that improvements in LLM performance on standardized medical benchmarks are directly reflected in how physicians evaluate the model’s clinical reasoning abilities, underscoring the importance of quantifying this correlation during LLM development and validation.
![Analysis of [latex]ARQ_4[/latex] and [latex]ARQ_5[/latex] utilized LOESS fitting to correlate LLM benchmark scores with perceived scores and permutation feature importance to identify discrepancies in emphasized evaluation dimensions between benchmark and perceived capability rankings.](https://arxiv.org/html/2601.19540v1/x9.png)
Seamless Integration: The Path to Clinical Utility
Successful integration of Large Language Models (LLMs) into clinical practice hinges on their ability to complement existing workflows, rather than necessitate substantial alterations to established procedures. Adoption rates will be significantly impacted by the degree to which LLMs can be seamlessly incorporated into tools and processes clinicians already utilize. This requires LLMs to function as assistive technologies, providing readily digestible insights and supporting decision-making without introducing undue cognitive load or disrupting established patterns of patient care. Systems designed to replace current methods are likely to face resistance, while those that enhance efficiency and accuracy within existing frameworks will be more readily accepted and consistently used.
Effective Human-AI collaboration in clinical diagnosis necessitates a synergistic approach where Large Language Models (LLMs) function as assistive tools, rather than independent decision-makers. This involves clinicians leveraging LLM outputs – such as differential diagnoses, relevant literature summaries, or identification of potential anomalies in patient data – to enhance their existing diagnostic process. The benefit lies in augmenting the clinician’s expertise with the LLM’s capacity for rapid information processing and pattern recognition, leading to more comprehensive evaluations and potentially reducing cognitive load. Successful integration requires clinicians to critically assess LLM-generated insights, integrating them with their clinical judgment and patient-specific knowledge to arrive at a final diagnosis and treatment plan.
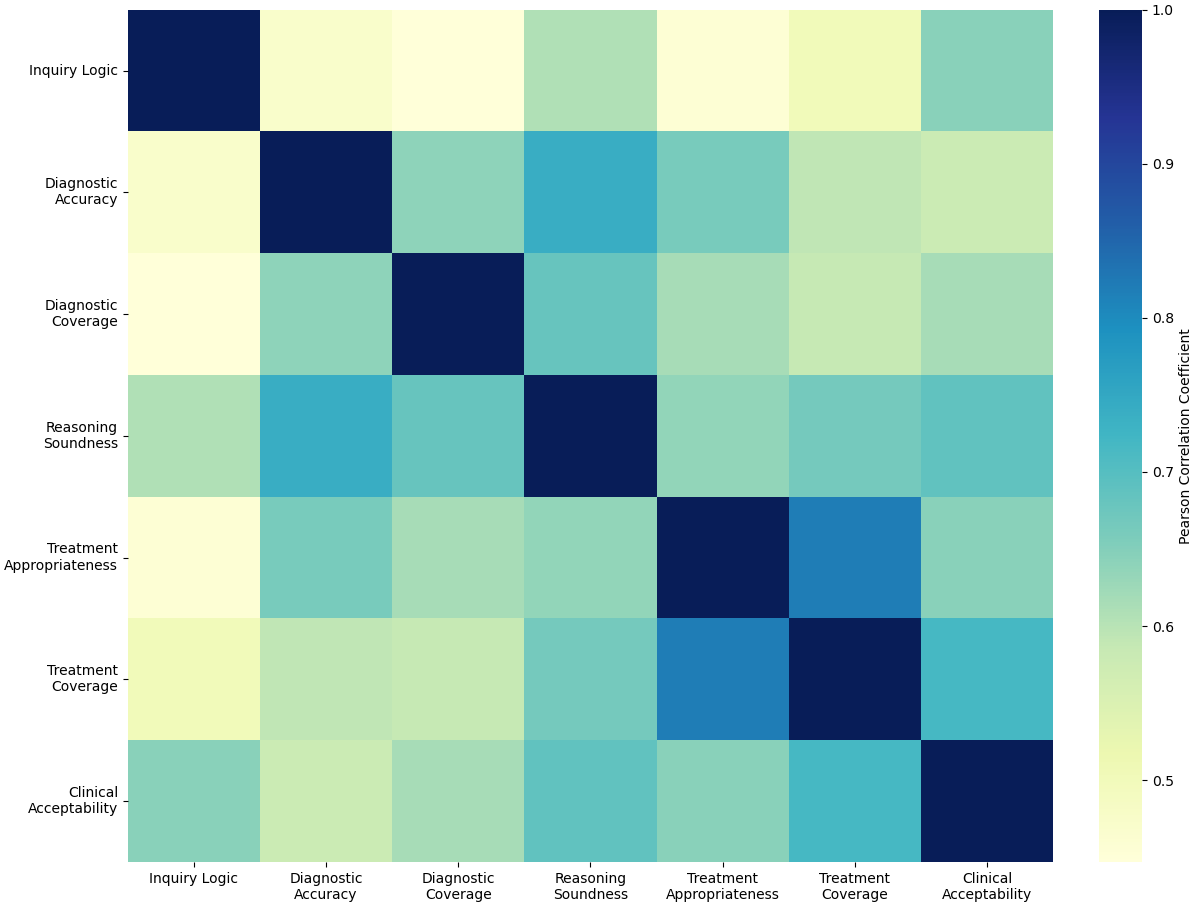
Trust calibration, the appropriate weighting of Large Language Model (LLM) outputs by clinicians, is a crucial element of effective Human-AI collaboration in clinical settings. Studies evaluating physician assessment of LLM analyses reveal moderate to high inter-rater reliability, with evaluator agreement scores ranging from 0.39 to 0.67. This suggests a reasonable degree of consistency in how physicians perceive the quality of LLM-generated insights, though variability exists. Successful integration necessitates clinicians understanding the LLM’s inherent limitations and capabilities to appropriately incorporate its suggestions into their diagnostic and treatment processes.
The Foundation of Trust: Physician Perception and Validation
The successful integration of large language model (LLM) based diagnostic tools into clinical practice hinges significantly on physician perception. Beyond simply achieving accurate diagnoses, acceptance relies heavily on how clinicians perceive the capabilities of these systems; a lack of confidence can impede adoption regardless of demonstrated performance. This perception isn’t solely about correctness; clinicians evaluate LLM reasoning, the coherence of explanations, and whether suggestions align with established clinical judgment. Consequently, understanding and quantifying physician perception – often through metrics like a PerceivedCapabilityScore – becomes paramount, as it directly influences whether these powerful tools are embraced as valuable aids or remain underutilized potential.
Clinician confidence in artificial intelligence diagnostic tools isn’t simply assumed; it’s frequently assessed and distilled into a quantifiable metric known as a PerceivedCapabilityScore. This score serves as a crucial barometer, moving beyond subjective impressions to provide a measurable indicator of how effectively a physician believes the technology performs. Researchers utilize this score to understand the degree to which clinicians trust the AI’s assessments, allowing for targeted improvements in both the technology itself and the methods used to present its findings. A higher PerceivedCapabilityScore suggests a greater willingness to integrate the tool into clinical practice, ultimately influencing patient care pathways and the overall success of AI implementation in healthcare settings.
The successful integration of large language models into diagnostic practice hinges on a reciprocal relationship between perceived capability and clinician trust. A high PerceivedCapabilityScore – a quantifiable measure of a physician’s confidence in the tool – directly fosters TrustCalibration, where increased confidence leads to more reliable diagnostic assessments and, subsequently, reinforces that initial confidence. Research, notably demonstrated through the CLMM model, reveals that physician evaluation extends beyond simple diagnostic accuracy; logical coherence of reasoning and overall clinical acceptability are equally critical components. This multi-dimensional assessment suggests that clinicians aren’t merely verifying if an LLM arrives at the correct diagnosis, but how it reaches that conclusion, impacting their willingness to rely on the tool’s insights and ultimately improving diagnostic reliability through a positive feedback loop.
The pursuit of trustworthy AI, as detailed in this research, echoes a fundamental principle of computational elegance. It’s not simply about achieving a correct diagnosis, but about the reasoning that leads to it. Donald Davies aptly stated, “Simplicity is a prerequisite for reliability.” This sentiment perfectly aligns with the study’s findings; physicians don’t solely assess LLMs on diagnostic accuracy. Instead, logical coherence and clinical feasibility-the ‘simplicity’ of the LLM’s thought process-are critical determinants of trust and effective human-AI collaboration. A complex, opaque reasoning chain, even if ultimately correct, will inevitably erode confidence, hindering the potential benefits of AI assistance in clinical settings.
Beyond Confidence Scores
The pursuit of ‘trustworthy’ artificial intelligence in diagnostic reasoning, as illuminated by this work, reveals a discomforting truth: simple accuracy metrics are insufficient. The dimensions of logical coherence and clinical feasibility-elements demanding more than mere statistical correlation-prove decisive in shaping a physician’s calibrated acceptance of an LLM’s output. This suggests the field has been fixated on what an AI predicts, rather than how it arrives at that prediction – a critical oversight. The emphasis on quantifiable performance must yield to a deeper interrogation of the reasoning process itself.
Future investigations should not concern themselves with mimicking human error rates, but with demonstrable, verifiable logical soundness. Provable correctness, not empirical similarity to fallible human judgment, must become the gold standard. The current reliance on black-box LLMs, evaluated solely on output, invites a perpetual cycle of patching and refining, rather than achieving genuine understanding. A system’s internal consistency-its freedom from contradiction-is paramount.
Ultimately, the question is not whether physicians will ‘trust’ AI, but whether AI can earn trust through transparency and provability. Simplification, in this context, does not mean brevity of code, but non-contradiction of logic. Until the field prioritizes demonstrable, mathematically rigorous reasoning, the promise of truly collaborative, trustworthy diagnostic AI will remain tantalizingly out of reach.
Original article: https://arxiv.org/pdf/2601.19540.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-01-29 07:04