Author: Denis Avetisyan
A new framework integrates intelligent software agents with field-programmable gate arrays to deliver substantial gains in speed and efficiency for deep learning applications.
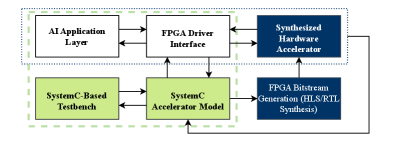
This review details AI-FPGA Agent, a hardware-software co-design that leverages agent-based scheduling and quantization for low-latency inference and improved adaptability.
Despite increasing demands for real-time, energy-efficient artificial intelligence, conventional CPUs and GPUs often fall short in delivering optimal performance for complex deep learning workloads. This paper introduces ‘A Reconfigurable Framework for AI-FPGA Agent Integration and Acceleration’, presenting AI FPGA Agent-an agent-driven framework that dynamically maps and accelerates deep neural network inference onto reconfigurable Field-Programmable Gate Arrays (FPGAs). Experimental results demonstrate over 10x latency reduction and 2-3x improved energy efficiency compared to CPU and GPU baselines, all while maintaining high classification accuracy. Could this approach unlock a new era of scalable, power-efficient AI deployment across a broader range of edge and embedded applications?
Beyond Fixed Architectures: The Limits of Conventional Computing
Despite their widespread use and general-purpose capabilities, conventional central processing units (CPUs) and graphics processing units (GPUs) increasingly face limitations when handling the massively parallel computations inherent in modern artificial intelligence workloads. These architectures, designed with a focus on sequential task execution, struggle to efficiently distribute and process the vast amounts of data required for training and deploying complex AI models. While GPUs offer some parallelism, their architecture still relies on a relatively small number of cores, creating a bottleneck when dealing with the millions of simultaneous operations characteristic of deep learning. This inherent architectural constraint results in both performance limitations and substantial energy consumption, prompting researchers to explore alternative computing paradigms better suited to the demands of contemporary AI.
The fundamental constraint on modern computing performance in deep learning arises from the sequential processing inherent in conventional architectures. While CPUs and GPUs excel at general-purpose tasks, they operate by executing instructions one after another, creating a bottleneck when handling the massive parallelism demanded by neural networks. Each layer in a deep learning model requires numerous matrix multiplications and additions, operations ideally suited for simultaneous execution. However, the von Neumann architecture, separating memory and processing, forces data to travel back and forth, consuming significant energy and limiting speed. This constant data movement, known as the “memory wall,” drastically reduces efficiency, especially as model sizes and complexity increase. Consequently, despite advancements in silicon fabrication, the performance gains from simply increasing clock speeds are diminishing, highlighting the urgent need for architectures designed to overcome these sequential processing limitations and unlock the full potential of deep learning.
The relentless growth in the size and intricacy of modern machine learning models, especially deep neural networks, is pushing the boundaries of conventional computing hardware. These networks, often comprising billions of parameters, demand immense computational power and memory bandwidth-resources that general-purpose processors struggle to provide efficiently. This escalating demand isn’t simply about faster clock speeds; it’s a fundamental limitation of the von Neumann architecture, where data and instructions are processed sequentially. Consequently, researchers are increasingly focused on developing specialized hardware accelerators-such as tensor processing units (TPUs) and neuromorphic chips-designed to handle the unique computational patterns of deep learning. These architectures prioritize parallel processing and in-memory computation, offering significant improvements in both performance and energy efficiency for increasingly complex AI tasks and paving the way for future innovations in artificial intelligence.
![This LLM inference pipeline, implemented on a Xilinx KV260, achieves 85% DDR4 bandwidth utilization by offloading quantized [latex]LLaMA2-7B[/latex] layers-including RoPE, RMSNorm, Softmax, and SiLU-to programmable logic and streaming data via a 64-bit AXI bus at 2400 Mbps, orchestrated by a bare-metal host application.](https://arxiv.org/html/2601.19263v1/x3.png)
Reconfigurable Hardware: Beyond the Fixed Logic Gate
Field-Programmable Gate Arrays (FPGAs) represent a departure from the architecture of central processing units (CPUs) and graphics processing units (GPUs), which are defined by fixed logic gates. FPGAs consist of configurable logic blocks, interconnected through programmable routing resources. This allows designers to instantiate custom data paths and state machines directly in hardware, creating circuits tailored to specific algorithms. Consequently, FPGAs excel at parallel processing and can achieve significant performance gains and power efficiency improvements over software-based implementations on general-purpose processors, particularly for computationally intensive tasks such as signal processing, image processing, and machine learning inference. The ability to reconfigure the hardware post-manufacturing also provides adaptability to evolving algorithmic requirements and standards.
Field-Programmable Gate Arrays (FPGAs) enable the creation of custom data paths and computational units tailored to specific Artificial Intelligence (AI) algorithms. This architectural flexibility allows for parallelization and optimization beyond what is achievable with general-purpose processors. By implementing only the necessary logic for a given AI task – such as convolutional neural networks or recurrent neural networks – FPGAs minimize latency and reduce power consumption compared to executing the same workload on CPUs or GPUs. The ability to customize the hardware directly translates to increased throughput for inference and training, and a significant reduction in energy expenditure per operation, making FPGAs particularly well-suited for edge computing and power-constrained applications.
Historically, configuring Field-Programmable Gate Arrays (FPGAs) has necessitated proficiency in Hardware Description Languages (HDLs) such as VHDL and Verilog. These languages demand a significant investment in learning and a deep understanding of digital logic design, representing a substantial barrier to entry for software developers and data scientists unfamiliar with hardware-level programming. The complexity of HDLs extends development cycles and requires specialized engineers for design, verification, and debugging, limiting the broader application of FPGAs despite their potential benefits in acceleration and customization. This reliance on HDLs has hindered the accessibility of FPGA technology and slowed its adoption in fields increasingly focused on software-defined solutions.
![This Q-learning agent leverages temporal difference learning and an [latex]\epsilon\epsilon[/latex]-greedy policy to dynamically schedule FPGA offload actions based on observed environment states and rewards, utilizing synchronized Q-tables [latex]Q_A[/latex] and [latex]Q_B[/latex] to ensure learning stability.](https://arxiv.org/html/2601.19263v1/x1.png)
AI FPGA Agent: Automating Hardware-Software Co-Design
The AI FPGA Agent framework addresses the complexities of deploying AI applications on Field Programmable Gate Arrays (FPGAs) through automated hardware-software co-design. This is achieved by integrating a reinforcement learning agent – specifically utilizing algorithms like Q-Learning – to manage the process of mapping computational graphs onto the FPGA fabric. The agent dynamically explores different hardware configurations and task scheduling options, optimizing for metrics such as latency, throughput, and power consumption. This automation reduces the need for manual intervention in the design flow, enabling rapid prototyping and deployment of AI workloads on FPGAs without requiring extensive hardware expertise. The framework aims to abstract the underlying hardware complexities, allowing developers to focus on algorithm development and performance tuning.
The AI FPGA Agent utilizes Q-Learning, a model-free reinforcement learning technique, to dynamically adjust task execution schedules on the FPGA. This involves the agent learning an optimal policy by estimating the quality (Q-value) of performing specific actions – such as task allocation or dataflow configuration – in given system states, which are defined by resource utilization, data dependencies, and workload characteristics. The agent continuously updates these Q-values based on observed rewards – typically metrics like throughput, latency, or energy consumption – allowing it to adapt to fluctuating system conditions and resource availability without requiring pre-defined rules or explicit programming. This adaptive capability ensures optimized performance even under variable workloads and resource constraints, improving overall system efficiency.
The AI FPGA Agent employs a multi-language hardware description workflow to facilitate the translation of algorithmic specifications into implementable FPGA configurations. High-Level Synthesis (HLS) tools are utilized to initially convert abstract algorithms, often expressed in languages like SystemC, into Register-Transfer Level (RTL) descriptions. These RTL descriptions are then typically refined and finalized using hardware description languages such as Verilog and VHDL. This layered approach-from algorithmic specification through HLS and culminating in detailed RTL code-streamlines the design process by automating much of the traditionally manual coding required to map software algorithms onto FPGA hardware, thereby reducing design time and potential errors.

Scaling AI with LLMs and Dynamic Scheduling: A Paradigm Shift
This innovative framework integrates Large Language Models (LLMs) directly into the hardware design process, moving beyond their typical software-based applications. LLMs are employed to automate crucial, yet traditionally manual, aspects of hardware verification and optimization, effectively acting as an intelligent co-designer. By leveraging the LLM’s ability to understand and generate complex code, the system can explore a vast design space, identify potential bottlenecks, and suggest improvements to hardware architectures far more efficiently than conventional methods. This LLM-guided approach not only accelerates the design cycle but also unlocks the potential for novel hardware configurations tailored to the specific demands of deep learning workloads, ultimately paving the way for more powerful and energy-efficient computing systems.
The system’s efficiency stems from an AI-driven dynamic scheduler that intelligently allocates FPGA resources in response to fluctuating computational demands. Rather than statically partitioning hardware, the agent continuously monitors workload characteristics and reconfigures the FPGA fabric to optimize performance and energy usage. This adaptive approach is crucial for deep learning inference, where batch sizes and model complexities can vary significantly. By proactively adjusting resource allocation, the scheduler minimizes idle hardware and maximizes throughput, leading to substantial gains in both speed and energy efficiency compared to traditional static implementations. This allows the system to maintain high performance across diverse workloads without requiring manual intervention or pre-defined configurations.
The system’s architecture intentionally integrates with OpenCL, a cross-platform framework, to facilitate heterogeneous computing – a powerful approach that strategically assigns tasks to the most suitable processing unit. Rather than relying on a single processor type, the framework intelligently distributes workloads across CPUs, GPUs, and FPGAs, capitalizing on each’s unique strengths. CPUs handle general-purpose tasks and control flow, GPUs accelerate massively parallel computations, and FPGAs provide custom hardware acceleration for specific, performance-critical operations within the deep learning pipeline. This collaborative approach not only boosts overall performance but also enhances energy efficiency by minimizing wasted cycles and maximizing resource utilization, creating a highly adaptable and optimized computing environment.
Deep learning workloads experience a substantial performance boost through this integrated framework, demonstrating over ten times the speed and two to three times the energy efficiency of traditional CPU and GPU implementations. Specifically, inference latency is dramatically reduced to 3.5 milliseconds, a significant improvement over the 40.2 milliseconds required by CPUs. The system achieves a throughput of 284.7 images per second, vastly exceeding the 25.5 images per second of CPUs and the 113.3 images per second of GPUs. This heightened performance translates to an energy efficiency of 10.17 images per second per watt, a considerable leap beyond the 0.29 and 0.90 images/s/W achieved by CPU and GPU baselines, respectively – all while maintaining model accuracy with only a 0.2% deviation from the floating-point reference.
The Future of Adaptive Intelligence: A Self-Evolving System
The AI FPGA Agent framework marks a departure from traditional computing architectures, where software and hardware remain largely fixed after deployment. This innovative system allows an artificial intelligence to not only learn and refine its algorithms, but also to directly reconfigure the underlying field-programmable gate array (FPGA) hardware itself. By dynamically adjusting the hardware’s structure, the agent optimizes computational resources to precisely match the needs of the evolving algorithm – essentially building a customized processor on the fly. This self-modifying capability represents a crucial step towards true adaptive intelligence, enabling systems to overcome the limitations of fixed hardware and achieve unprecedented levels of efficiency and performance as algorithms learn and change over time.
The potential of dynamically reconfigurable AI extends far beyond theoretical computing, offering tangible benefits across diverse fields. In autonomous vehicles, this technology promises more efficient processing of sensor data, enabling faster reaction times and improved safety in complex driving scenarios. Robotics stands to gain from adaptable hardware that optimizes performance for varying tasks-from delicate manipulation to heavy lifting-without requiring specialized machines for each job. Perhaps most profoundly, personalized medicine could be revolutionized by AI systems capable of tailoring treatment plans based on individual patient data, and even optimizing hardware to accelerate genomic sequencing or drug discovery, all while minimizing energy consumption and maximizing computational throughput.
Current investigations are centering on enhancing the AI FPGA Agent’s capacity for independent learning, moving beyond pre-programmed responses to genuine architectural innovation. Researchers aim to equip the agent with the ability to not only refine existing hardware configurations but to proactively explore and implement entirely new designs tailored to the specific demands of evolving algorithms. This involves developing sophisticated reinforcement learning techniques and search algorithms that allow the agent to navigate the vast landscape of possible FPGA configurations, identifying solutions that maximize performance and minimize energy consumption. Ultimately, the goal is to create an intelligent system capable of self-directed hardware evolution, potentially unlocking unprecedented levels of efficiency and adaptability in artificial intelligence systems.
The melding of artificial intelligence with reconfigurable hardware architectures heralds a new era for intelligent systems, moving beyond simply increased computational power. This convergence allows for dynamic optimization, enabling systems to adjust their very structure to match the needs of the algorithm at hand – a process that dramatically improves energy efficiency and reduces reliance on increasingly strained resources. Such adaptability isn’t merely about performance gains; it signifies a shift toward sustainability, as systems can evolve to minimize their environmental impact. Ultimately, this promises intelligent machines capable of responding to unforeseen challenges and operating effectively in dynamic environments, unlocking potential across diverse fields and fostering a future where intelligence is both potent and responsible.
The pursuit of AI-FPGA Agent exemplifies a willingness to dismantle conventional approaches to deep learning inference. The framework doesn’t simply optimize existing pipelines; it actively reconfigures the hardware itself, embracing a chaotic adaptability that surpasses the limitations of fixed CPU and GPU architectures. This echoes the sentiment of Henri Poincaré: “Mathematics is the art of giving reasons.” The agent-based scheduling, a core concept of this work, isn’t merely applying mathematical principles, but actively seeking the most logical and efficient configuration-a constant process of reasoned experimentation and refinement, effectively ‘giving reasons’ for each hardware adaptation to achieve optimal performance and low-latency inference.
What’s Next?
The presented work, while demonstrating a significant step in AI-FPGA integration, merely scratches the surface of what’s possible when one treats hardware as fluid, adaptable code. The current paradigm still relies on mapping algorithms onto silicon; a truly elegant solution will involve algorithms that emerge from the hardware itself. This framework, by exposing a degree of reconfigurability, hints at that future, but the real challenge lies in automating the discovery of optimal configurations – letting the silicon ‘debug’ the software, as it were.
A critical limitation remains the inherent trade-off between precision and performance. Quantization, while effective, introduces approximation. The question isn’t simply how to minimize the loss of accuracy, but whether accuracy, as currently defined, is even the right metric. Perhaps a degree of controlled ‘noise’-intentional imprecision-could unlock entirely new computational strategies. Reality, after all, isn’t built on perfect numbers.
Ultimately, this line of inquiry reinforces a core tenet: reality is open source – one just hasn’t read the code yet. The true potential of AI-FPGA systems won’t be realized through incremental improvements, but through a fundamental shift in how one conceptualizes computation. It’s not about building faster algorithms; it’s about building systems that learn to become the algorithm.
Original article: https://arxiv.org/pdf/2601.19263.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-01-28 12:32