Author: Denis Avetisyan
A new approach integrates semantic concepts into robotic imitation learning, dramatically improving sample efficiency and accelerating the learning process.

ConceptACT leverages transformer networks and human-provided concepts to enhance robotic manipulation skills with fewer training examples.
Despite advances in robotic imitation learning, current methods often struggle with data efficiency, failing to leverage the rich semantic understanding humans possess about task execution. This work introduces ‘ConceptACT: Episode-Level Concepts for Sample-Efficient Robotic Imitation Learning’, a novel approach that integrates human-provided, episode-level semantic concepts directly into a transformer-based architecture. By employing concept-aware cross-attention, ConceptACT demonstrably improves sample efficiency and convergence speed on robotic manipulation tasks with logical constraints. Could this form of semantic supervision offer a crucial pathway towards more robust and generalizable robot learning systems?
The Inevitable Bottleneck: Data and the Illusion of Robotic Learning
Robotic systems trained through traditional imitation learning frequently encounter a significant hurdle: the need for extensive demonstration data. These methods, while conceptually straightforward, demand a robot observe countless examples of a desired behavior before it can reliably replicate it. This reliance on large datasets presents practical challenges, as acquiring such data can be time-consuming, expensive, and even impossible in certain real-world scenarios. Consider tasks requiring nuanced manipulation or navigation in complex environments; collecting enough examples for a robot to learn effectively often proves prohibitive. Consequently, the deployment of robots trained via conventional imitation learning is often limited to highly constrained settings, hindering their broader application in dynamic and unpredictable situations.
Sustained progress in robotics hinges on the development of systems capable of learning complex tasks with minimal data and swiftly adjusting to unforeseen circumstances. Traditional robotic learning often requires extensive trial-and-error, or massive datasets of expert demonstrations – a significant limitation in real-world scenarios where data acquisition is costly or impractical. The pursuit of sample efficiency-achieving robust performance with fewer examples-is therefore paramount. This necessitates algorithms that can effectively generalize from limited experience, perhaps by incorporating prior knowledge or leveraging simulation. Faster adaptation, meanwhile, requires mechanisms for continuous learning, allowing robots to refine their skills as they interact with dynamic and unpredictable environments, ultimately enabling deployment in a wider range of applications and enhancing their resilience to change.
Robotic systems often falter when confronted with even slight variations in their operational environment, a consequence of their limited ability to understand what they are doing, not just how. Current learning approaches largely focus on mapping sensory inputs to motor commands, effectively treating tasks as black boxes rather than leveraging the underlying semantic meaning. This means a robot trained to pick up a red block may struggle with a blue one, despite the task remaining fundamentally the same. The inability to generalize from known tasks to novel, yet semantically similar, scenarios drastically limits a robot’s adaptability and necessitates extensive retraining for each new situation. Researchers are actively exploring methods to imbue robots with a richer understanding of task goals and object properties, hoping to bridge this semantic gap and unlock truly versatile robotic intelligence.
The practical deployment of robots consistently faces limitations due to a critical need for extensive training data; this data inefficiency represents a significant bottleneck when transitioning robots to novel environments or tasks. Unlike humans who can often generalize from a few examples, robots typically require hundreds or even thousands of demonstrations to achieve reliable performance, a demand that is both time-consuming and costly to fulfill. This reliance on large datasets hinders adaptability – a robot trained in one setting may struggle significantly when confronted with even minor variations, such as altered lighting, unexpected obstacles, or slight changes in the task parameters. Consequently, the inability to learn efficiently restricts robotic applications to highly structured and predictable scenarios, impeding progress towards truly versatile and autonomous systems capable of operating effectively in the real world.
ConceptACT: Injecting Meaning into the Mimicry
ConceptACT is an advancement of the Action Chunking Transformer (ACT) architecture designed to enhance imitation learning through the incorporation of episode-level semantic concepts. This integration allows the agent to process and utilize high-level task understanding during the learning process. Unlike standard ACT, which relies solely on sequential action data, ConceptACT explicitly represents contextual information relevant to each episode, providing the agent with additional input features. These semantic concepts are incorporated into the transformer network, enabling it to learn more efficiently from limited data and generalize more effectively to new situations. The resulting model aims to improve performance by grounding action selection in a broader understanding of the task context.
ConceptACT incorporates a ConceptTransformer layer which modifies standard transformer architectures to integrate semantic concepts into the attention mechanism. This is achieved by conditioning attention weights on learned embeddings representing episode-level concepts. Specifically, the ConceptTransformer layer introduces concept-aware attention biases, allowing the model to dynamically prioritize information relevant to the identified concepts during sequence processing. This modification enables the agent to focus on semantically meaningful features, improving the efficiency and effectiveness of the imitation learning process by directing attention towards crucial aspects of the observed behavior.
The ConceptACT architecture enhances information processing by enabling the agent to prioritize relevant inputs during sequence modeling. This prioritization is achieved through the ConceptTransformer layer, which modifies attention mechanisms to weigh inputs based on their semantic relationship to high-level task concepts. By focusing on conceptually important information, the agent reduces the computational burden of attending to irrelevant details, leading to faster convergence during imitation learning and demonstrably improved performance across various benchmark tasks. This selective attention mechanism allows ConceptACT to achieve comparable or superior results with significantly less training data than traditional transformer-based architectures.
Traditional imitation learning methods often require extensive datasets to achieve proficient performance due to their reliance on implicitly learning task structure from raw observations. ConceptACT mitigates this limitation by explicitly incorporating task knowledge in the form of semantic concepts. This explicit representation allows the agent to generalize more effectively from limited data, as it can leverage pre-defined concepts to understand and predict optimal actions. By reducing the need to infer task structure solely from data, ConceptACT demonstrably improves sample efficiency and accelerates the learning process, particularly in scenarios where data acquisition is costly or time-consuming.
Evidence of Efficiency: Performance in Complex Manipulation
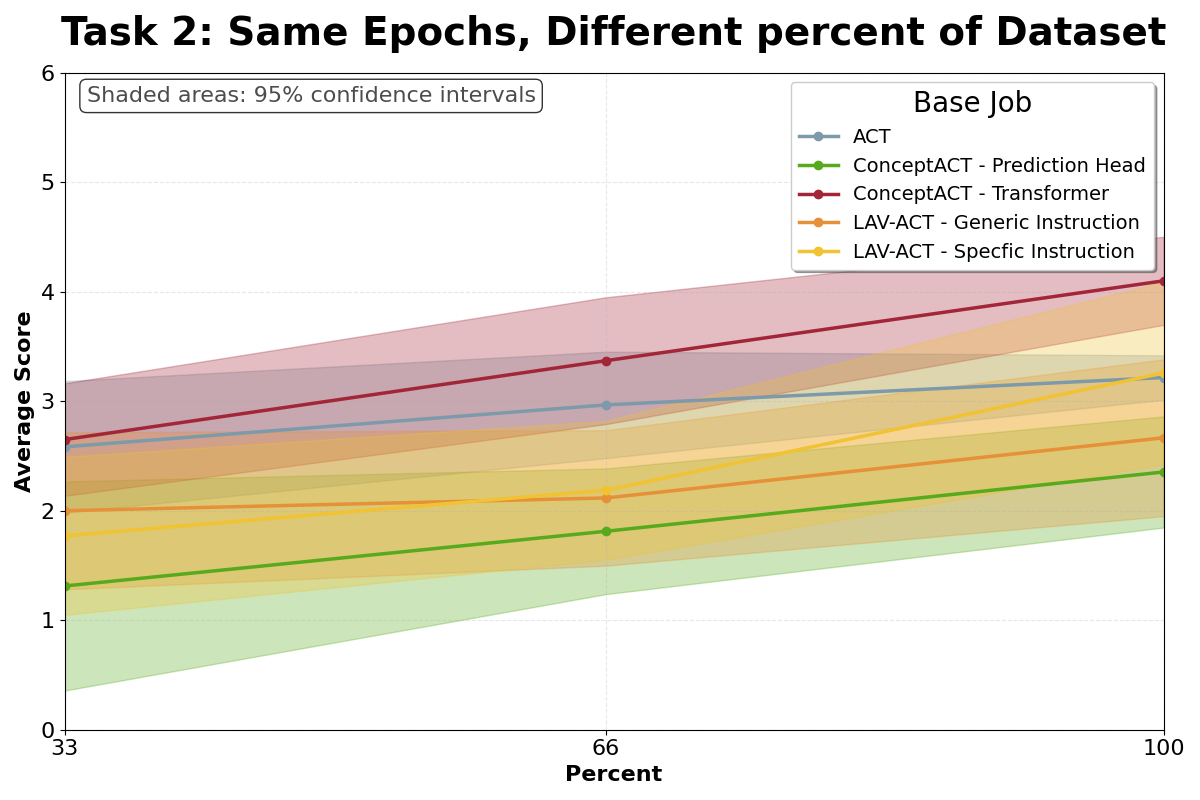
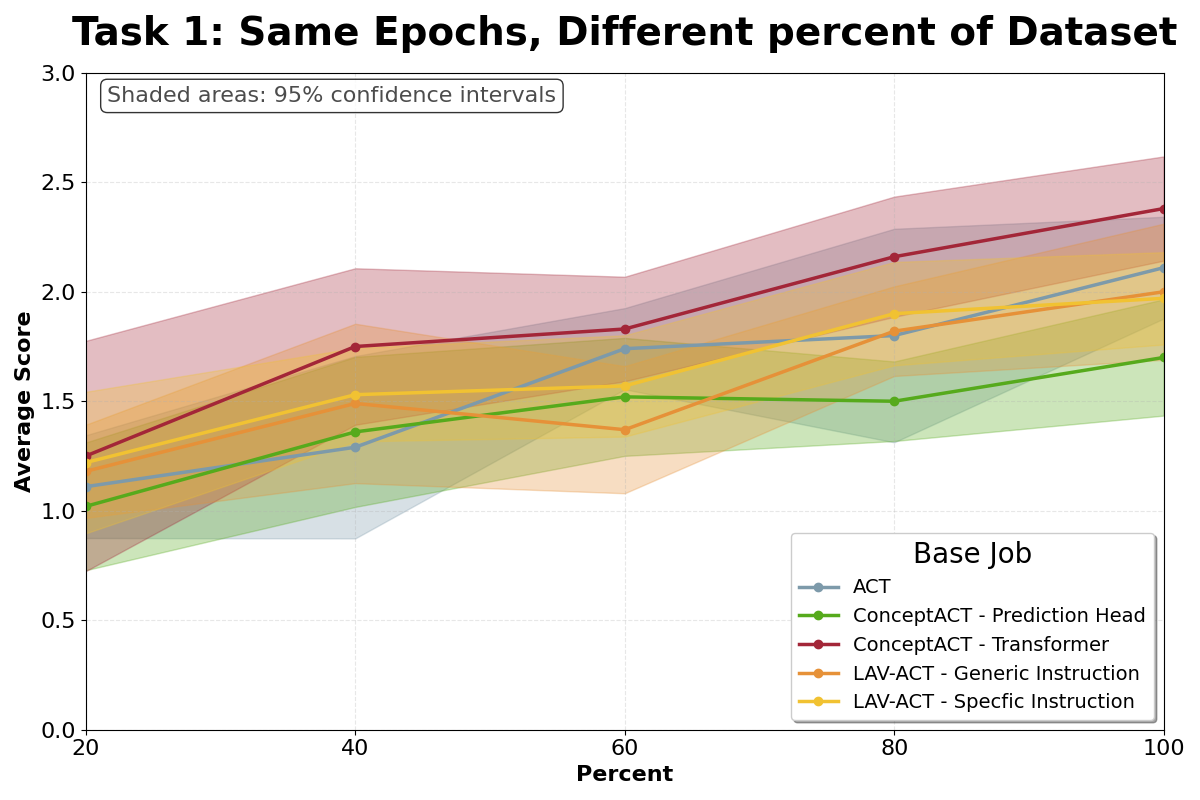
ConceptACT demonstrates enhanced learning efficiency by requiring a 40% reduction in training time to achieve performance comparable to, and often exceeding, that of standard approaches. This improvement is quantified by a decrease in the number of demonstrations needed for a robot to learn complex tasks; ConceptACT achieves near-optimal performance with half the demonstrations required by standard ACT. The reduction in training time translates directly to faster deployment and reduced resource consumption in robotic applications requiring learned behavior.
ConceptACT was evaluated on robot manipulation tasks specifically involving the sorting and ordering of objects. These tasks necessitated the robot’s application of conditional logic based on discernible object properties – such as color, shape, or size – to correctly execute the required manipulation. Successful completion of these tasks demonstrates ConceptACT’s ability to move beyond simple imitation and perform actions based on learned relationships between object characteristics and desired outcomes, effectively showcasing its generalization capabilities in a practical robotic context.
The robot manipulation tasks employed to evaluate ConceptACT necessitate the application of conditional logic based on discernible object properties – specifically, size, color, and shape – to successfully sort and order items. This requirement moves beyond rote imitation learning, as the robot cannot simply replicate observed actions; instead, it must infer rules regarding how to manipulate objects based on their characteristics. Consequently, the robot demonstrates an ability to generalize learned behaviors to novel object arrangements and types, effectively performing tasks not explicitly included in the initial demonstration set. This capacity for generalization is crucial for real-world applicability, where perfect replication of training scenarios is improbable.
Quantitative results demonstrate ConceptACT’s enhanced data efficiency. The system achieves performance levels approaching optimality using 50% fewer demonstration examples than standard ACT implementations. Statistical analysis confirms a significant improvement over a reduced ConceptACT architecture (ConceptACT-Heads), indicating the value of the full model. Furthermore, ConceptACT reduces the optimality gap – the difference between achieved performance and the theoretical best – by 42%, representing a substantial gain in task performance relative to the amount of training data required.
![The proposed method demonstrates faster convergence, as evidenced by lower test loss on a holdout set [latex]\downarrow[/latex], and superior real-robot performance [latex]\uparrow[/latex] with lower variance across multiple random seeds compared to existing approaches.](https://arxiv.org/html/2601.17135v1/images/robot_eval_epochs.png)
Towards True Autonomy: A Shift in Robotic Intelligence
ConceptACT demonstrates a marked improvement in robotic learning by integrating semantic understanding into its operational framework. Instead of relying on vast datasets and repetitive trials, the system learns from fewer examples – a significant leap in ‘sample efficiency’. This is achieved by enabling the robot to grasp the meaning of actions and objects, rather than simply recognizing visual patterns. Consequently, ConceptACT not only learns tasks faster, but also generalizes its knowledge more effectively; a robot trained with ConceptACT can adapt to new, subtly different situations with minimal additional training. This semantic approach represents a departure from traditional robotic systems that often require extensive retraining when faced with even minor environmental changes, paving the way for more robust and adaptable autonomous agents.
A key innovation lies in the architecture’s ability to extrapolate learned behaviors to entirely new situations without demanding exhaustive retraining protocols. Traditional robotic systems often struggle when confronted with environments or tasks differing even slightly from their training data, necessitating repeated and time-consuming adjustments. However, this system’s design promotes a form of conceptual understanding; rather than simply memorizing specific actions for specific inputs, the robot learns underlying principles. This allows it to effectively ‘reason’ about novel scenarios, adapting previously acquired knowledge to accomplish tasks it has never explicitly been programmed to perform. Consequently, deployment in unpredictable, real-world settings becomes significantly more feasible, reducing the reliance on meticulously curated training environments and accelerating the development of truly autonomous robotic agents.
The capacity for autonomous and reliable operation in real-world settings represents a crucial leap forward for robotics, and recent developments are actively addressing this challenge. Robots equipped with advanced architectures can now navigate and respond to unpredictable environments with greater proficiency. This isn’t simply about executing pre-programmed instructions; instead, it involves a dynamic assessment of surroundings and a flexible adjustment of actions. Consequently, these robots exhibit enhanced resilience to unexpected obstacles, varying lighting conditions, and the general chaos inherent in complex spaces. Such improvements minimize the need for constant human intervention, allowing robots to perform tasks more independently and consistently, ultimately broadening their potential applications in fields like manufacturing, logistics, and even disaster response.
The development of ConceptACT signifies a crucial shift in robotic intelligence, moving beyond systems reliant on rote memorization of specific actions and environments. This architecture doesn’t simply catalogue experiences; instead, it equips robots with the capacity to understand the meaning behind actions and perceive underlying concepts. By associating behaviors with abstract ideas – such as ‘grasping’ or ‘avoiding’ – the robot can then generalize these concepts to novel situations it hasn’t explicitly encountered before. This conceptual understanding allows for true adaptation, enabling the robot to reason about its actions and modify its behavior based on the context, rather than rigidly following pre-programmed responses. Consequently, ConceptACT fosters a level of autonomy and flexibility previously unattainable, bringing researchers closer to creating robots capable of genuine intelligence and problem-solving in complex, unpredictable real-world settings.
The pursuit of robotic imitation learning, as demonstrated by ConceptACT, reveals a fundamental truth about complex systems. The architecture isn’t merely a blueprint, but a prophecy of eventual failure, a temporary deferral of inevitable chaos. The integration of semantic concepts into the transformer network – a deliberate attempt to impose order – is, in effect, a sophisticated caching mechanism. As Vinton Cerf observed, “Any sufficiently advanced technology is indistinguishable from magic.” This ‘magic’-the illusion of seamless robotic action-is sustained only by the constant replenishment of this semantic cache, a fragile balance between imposed structure and the underlying entropy. ConceptACT, therefore, doesn’t build a system so much as cultivate an ecosystem, reliant on continuous learning and adaptation to postpone the inevitable.
What Lies Ahead?
The integration of semantic concepts, as demonstrated by ConceptACT, feels less like a solution and more like a formalization of the inevitable. Every system built to mimic intelligence must, at some point, contend with the ambiguity of the world. The current approach grafts meaning onto the architecture; a clever bandage, certainly. But the underlying fragility remains. The network still learns through concepts, not from understanding. It is a scaffolding erected against the chaos, destined to be outgrown.
Future iterations will undoubtedly explore more nuanced concept representations – dynamic concepts, perhaps, or those learned concurrently with the policy itself. The true challenge, however, isn’t in refining the signal, but in accepting the noise. A robust system won’t seek to eliminate uncertainty, but to navigate it. It will stumble, adapt, and redefine ‘correctness’ with each iteration.
One suspects that the pursuit of ‘sample efficiency’ is itself a symptom. A striving for control in a realm fundamentally resistant to it. The system will not become truly efficient; it will simply become better at predicting its own failures. And in that prediction, perhaps, lies a different kind of intelligence altogether.
Original article: https://arxiv.org/pdf/2601.17135.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-01-28 04:14