Author: Denis Avetisyan
A new framework leverages eye-tracking to improve the accuracy and reliability of assistive robotic arms in everyday tasks.
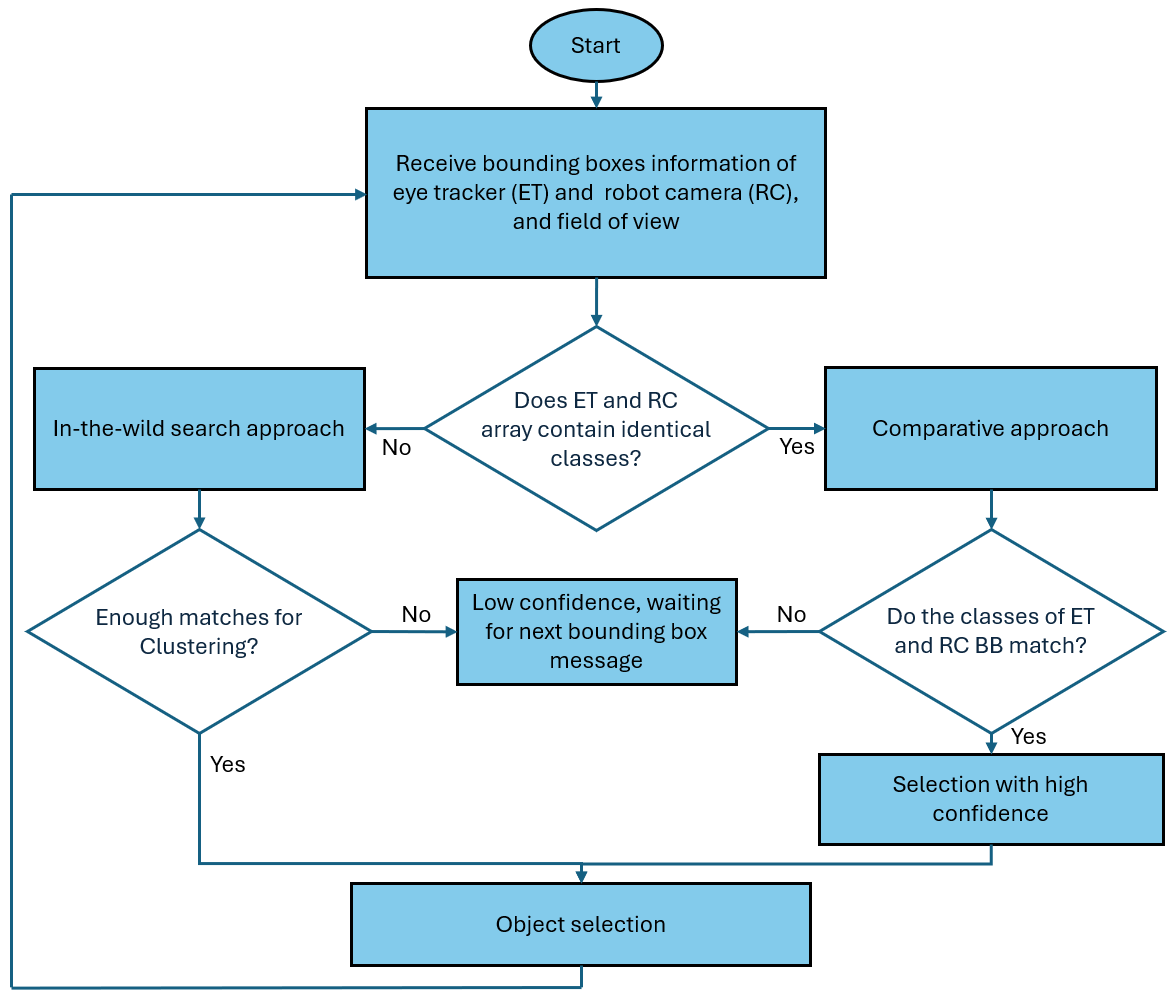
This review details an eye-tracking-driven shared control system integrating task pictograms, feature matching, and an eye-in-hand camera for robust daily task assistance.
While assistive robotic arms hold immense potential for enhancing independence, reliable and intuitive control remains a significant challenge, particularly for individuals with severe physical limitations. This is addressed in ‘Eye-Tracking-Driven Control in Daily Task Assistance for Assistive Robotic Arms’, which presents a novel framework leveraging eye-tracking for robust task selection and execution. By integrating task pictograms, feature matching, and an eye-in-hand camera configuration, the system achieves up to 97.9% accuracy in identifying desired objects and tasks without requiring prior knowledge of the user’s position. Could this approach pave the way for more adaptable and user-friendly assistive robotic systems capable of seamlessly integrating into daily life?
Restoring Agency: The Promise of Intuitive Robotic Assistance
The simple acts of daily living – preparing a meal, grooming, or even reaching for an object – present substantial challenges for individuals facing motor impairments. These limitations extend beyond mere physical difficulty; they often erode independence and diminish overall quality of life. Consequently, there’s a growing demand for assistive technologies that transcend traditional, cumbersome devices. Effective solutions require a nuanced understanding of the user’s intent, coupled with robotic systems capable of responding with speed and precision. The core principle driving innovation in this field isn’t simply automation, but rather the restoration of agency – empowering individuals to perform tasks with minimal effort and maximum control, thereby fostering a greater sense of self-reliance and participation in everyday activities.
Conventional robotic interfaces often necessitate a level of fine motor control that presents substantial challenges for individuals with physical limitations. These systems typically rely on joysticks, buttons, or direct manipulation, demanding precise movements and sustained physical effort. For those with conditions like spinal cord injuries, cerebral palsy, or advanced arthritis, executing these precise controls can be exceedingly difficult, if not impossible, effectively excluding them from benefiting from robotic assistance. The inherent need for physical dexterity creates a significant barrier to usability, limiting the potential of robotics to truly enhance independence and quality of life for a broad spectrum of users; consequently, research is increasingly focused on alternative control methods that bypass these physical demands.
The pursuit of truly effective assistive robotics centers on developing control systems that transcend the limitations of physical dexterity. Current technologies often require users to possess a degree of motor control that is, by definition, absent in those who need assistance most. Consequently, research is increasingly focused on hands-free paradigms, leveraging alternative input methods such as gaze tracking, voice commands, or even neural interfaces to interpret user intent. This shift promises to restore a sense of agency and independence, allowing individuals to perform everyday tasks – from preparing a meal to communicating with loved ones – without relying on constant external support. By prioritizing intuitive control and minimizing physical demand, these advancements aim not simply to aid individuals with motor impairments, but to empower them to live fuller, more self-directed lives and dramatically improve their overall quality of life.
Gaze-Based Control: An Intuitive Interface for Robotic Interaction
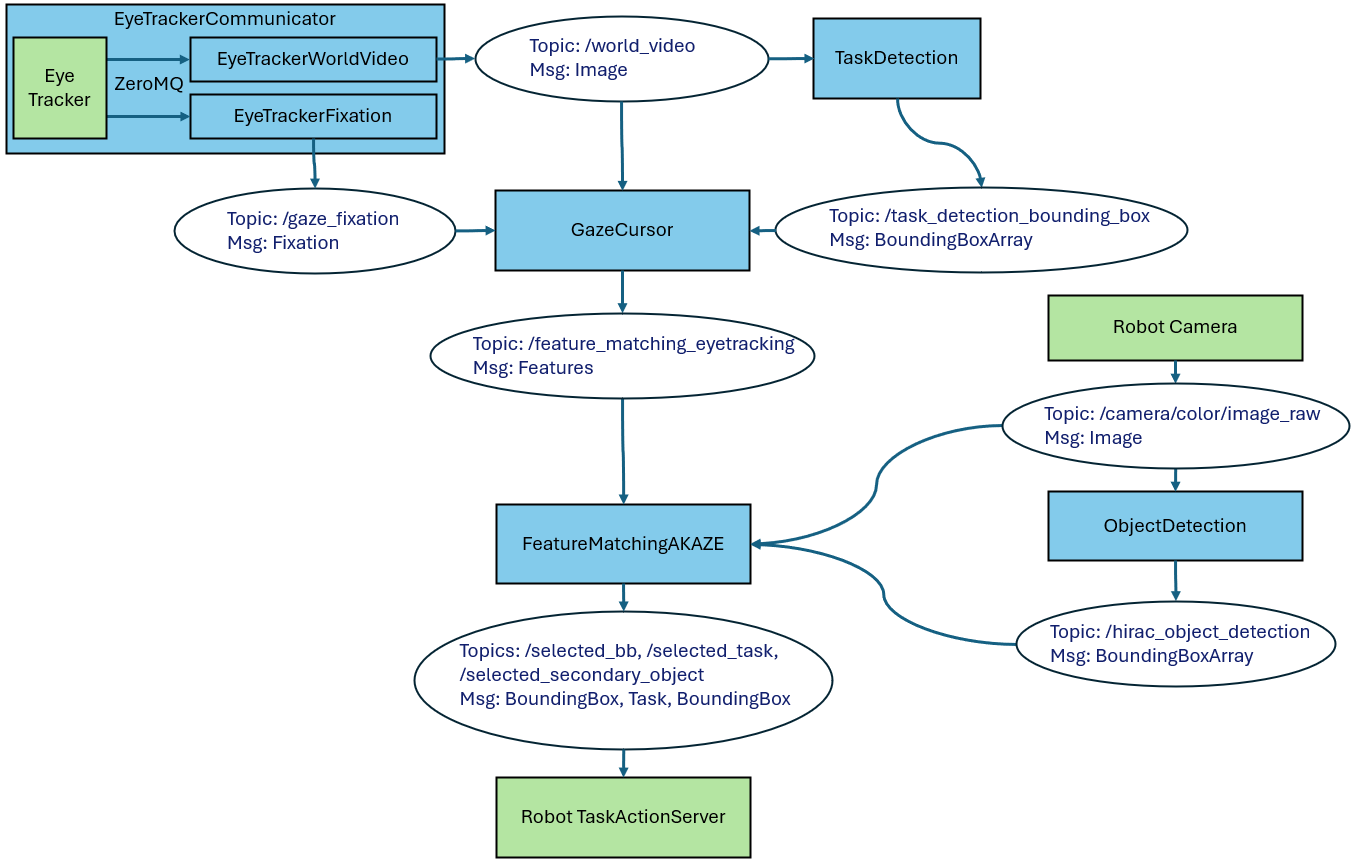
EyeTrackingControl is a control system designed to enable command of an assistive robotic arm through the analysis of user gaze. The system utilizes gaze estimation techniques to determine the point of regard, translating this visual focus into robotic arm movements and actions. This approach offers a hands-free control method, allowing users to interact with and manipulate objects in their environment without requiring traditional input devices such as joysticks, switches, or voice commands. The core functionality revolves around accurately mapping gaze direction to desired robotic actions, facilitating a more intuitive and accessible interface for individuals with limited mobility or other physical impairments.
The EyeTrackingControl system enables hands-free operation of an assistive robotic arm through gaze-based input. Users initiate tasks and manipulate virtual or physical objects by directing their gaze to corresponding targets displayed on a screen or within the robot’s workspace. This bypasses the requirement for traditional input methods such as joysticks, switches, or voice commands, offering a control solution for individuals with limited or no physical mobility. The system interprets gaze position as a command, translating eye movements into robotic arm actions for object selection, positioning, and manipulation, thereby providing an alternative user interface for robotic assistance.
The ‘EyeInHandConfiguration’ utilizes a ‘RobotMountedCamera’ to provide the visual data required for precise object localization within the robotic arm’s workspace. This configuration places the camera directly on the end-effector of the robot, ensuring a consistent perspective relative to the objects being manipulated. The resulting visual information, processed through established computer vision algorithms, enables the system to determine object position and orientation in real-time, independent of external tracking systems. This approach minimizes the impact of calibration errors and external disturbances, contributing to the accuracy and reliability of gaze-based object selection and manipulation.
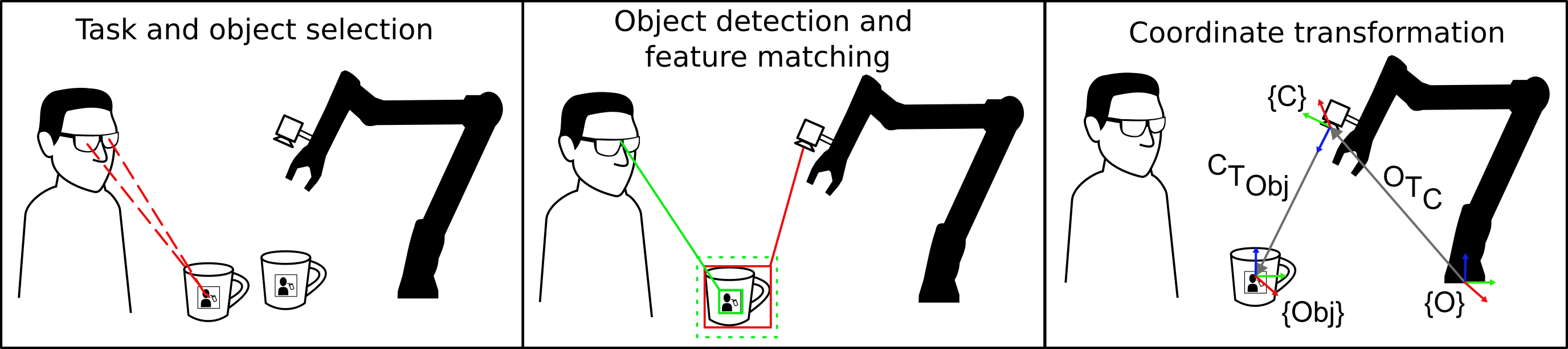
Precise Perception: Object Recognition and Feature Alignment
Object detection accuracy is achieved through supervised learning utilizing the MSCOCO dataset, a large-scale dataset containing over 330,000 images with over 1.5 million object instances annotated with bounding boxes and object categories. Training on MSCOCO allows the robot’s vision system to generalize to novel scenes and reliably identify a diverse range of objects, even in cluttered environments. The dataset’s scale and variety are critical for building a robust object detection model capable of operating effectively in complex, real-world scenarios. The model learns to differentiate between objects and background elements, and to localize objects within the image frame with sufficient precision for subsequent manipulation.
Feature matching establishes the spatial relationship between the eye-tracker and the robot’s camera to facilitate gaze-based object manipulation. This is achieved by identifying and comparing distinctive features in the images captured by both systems. The system employs the Accelerated-KAZE (AKAZE) algorithm for robust and efficient feature description, generating a set of keypoint descriptors. Fast Library for Approximate Nearest Neighbors (FLANN) is then used to perform a rapid search for corresponding features between the eye-tracker and robot camera images. By identifying these matching features, the system computes a homography that maps points from the eye-tracker view to the robot camera view, enabling accurate gaze-to-object correspondence.
The established correspondence between the eye-tracker and the robot camera enables real-time user gaze tracking, allowing the system to determine the object currently fixated by the user. This spatial alignment facilitates accurate object manipulation; the robot utilizes the gaze position as a direct indicator of the target object for interaction. By precisely linking gaze data to the robot’s visual perception, the system can execute commands related to the identified object, effectively translating user intent – indicated by their gaze – into physical action. This capability is fundamental to the system’s ability to function as an assistive or collaborative robotic interface.
The system employs ‘DwellTime’ as a user selection method, quantifying the amount of time a user’s gaze remains fixed on a specific target object. This fixation duration serves as an indicator of intent; after a pre-defined dwell time threshold is met – typically measured in milliseconds – the system interprets this as a selection signal. This allows for hands-free interaction, where the user simply looks at the desired object to initiate manipulation or task execution, eliminating the need for physical buttons or other input devices. The dwell time parameter is adjustable to optimize the balance between responsiveness and prevention of accidental selections.
Controlled experimentation demonstrated a task selection success rate of up to 97.1% using the developed system. This metric was achieved through rigorous testing under defined conditions, indicating a high degree of reliability in the robot’s ability to correctly identify and initiate user-selected tasks. The success rate reflects the effectiveness of the integrated object recognition, feature matching, and dwell-time selection mechanisms in facilitating intuitive human-robot interaction. The consistently high performance suggests the system is robust and minimizes errors in interpreting user intent during task selection.
Towards Collaborative Assistance: Intelligence and Adaptability
The architecture prioritizes a ‘SharedControl’ paradigm, moving beyond fully autonomous operation or simple teleoperation to foster genuine collaboration between a user and the robotic system. This approach allows the robot to anticipate user needs and offer assistance, but crucially, maintains user oversight and the ability to easily intervene or redirect the robot’s actions. By dynamically balancing robotic autonomy with direct user input, the system achieves a more natural and efficient interaction, reducing the cognitive burden on the user and promoting a sense of partnership. This isn’t about the robot doing for the user, but with the user, creating a workflow where each agent complements the other’s strengths – the robot handling repetitive tasks and the user providing high-level direction and nuanced judgment.
The capacity for a robotic assistant to truly understand and anticipate human needs hinges on sophisticated natural language processing, and recent advancements leverage the power of Large Language Models (LLMs) to achieve this. These LLMs aren’t simply recognizing keywords; they are parsing the intent behind user requests, even those expressed vaguely or indirectly. This allows the robot to move beyond reactive responses and offer proactive assistance – suggesting a tool before it’s asked for, preparing materials for an anticipated task, or even identifying potential problems before the user does. By analyzing language patterns and contextual cues, the system builds a dynamic model of the user’s goals, enabling a more fluid and intuitive collaboration that feels less like issuing commands and more like working with a helpful partner. The integration of LLMs, therefore, represents a crucial step towards creating robotic assistants that are genuinely intelligent and capable of adapting to the nuanced demands of real-world situations.
To rigorously test and improve the robot’s assistive capabilities, a high-fidelity simulation environment, termed ‘AssistiveGym’, was developed. This virtual world replicates the complexities of real-world domestic settings, allowing for extensive evaluation of the system’s performance and, crucially, its safety without physical risk. AssistiveGym facilitates the generation of diverse scenarios – from cluttered kitchens to dynamic living rooms – enabling researchers to systematically assess the robot’s ability to understand user needs, navigate obstacles, and provide effective assistance. The platform’s realistic physics engine and sensor modeling capabilities ensure that the simulation closely mirrors real-world conditions, providing a reliable means of refining algorithms and validating the system’s robustness before deployment in human-populated environments. This iterative process of simulation-based testing and refinement is central to building a trustworthy and effective robotic assistant.
To streamline interaction, the robotic assistance system employs a visually-driven interface utilizing intuitive task pictograms. Rather than relying on textual commands or complex menus, users are presented with a series of easily recognizable icons representing available actions, such as fetching an object or initiating a cleaning cycle. This approach significantly reduces cognitive load by bypassing the need for extensive language processing or memorization, enabling quicker and more natural task selection. By leveraging visual cues, the system aims to make robotic assistance accessible to a wider range of users, including those with limited technical expertise or cognitive impairments, fostering a more seamless and efficient human-robot collaboration.
A critical element of effective human-robot collaboration lies in minimizing delays during task selection, and this system demonstrably excels in this area. Evaluations reveal a mean task selection response time of just 260.3 milliseconds, a figure indicative of near-instantaneous reactivity to user input. This swift response is achieved through optimized algorithms and efficient data processing, allowing the robot to quickly interpret user requests and initiate the corresponding action. Such a rapid interaction pace is crucial for maintaining a natural and fluid collaborative experience, preventing frustration and fostering a sense of seamless partnership between the user and the robotic assistant. The quickness of the system significantly reduces cognitive load and allows users to maintain focus on the task at hand, rather than being hindered by sluggish response times.
The presented framework prioritizes efficient communication between human and machine, distilling complex actions into readily identifiable task pictograms. This echoes Bertrand Russell’s sentiment: “The point of education is not to increase the amount of information, but to create the capacity for critical thought.” The system, by minimizing cognitive load through clear visual cues and robust feature matching, facilitates a more intuitive and effective shared control experience. It isn’t merely about automating tasks; it’s about augmenting human capability by removing unnecessary friction, aligning with a principle of minimalist interaction-density of meaning achieved through elegant reduction.
What Remains?
The presented framework, while demonstrating improved task selection, ultimately highlights the enduring challenge of translating intent into action. The reliance on pre-defined pictograms, however elegant, introduces a necessary discreteness. True assistance demands a system capable of interpreting not just what is desired, but how it is desired – a nuance lost in the binary choice of iconographic representation. Future work must address this, perhaps by incorporating predictive models of user behavior, allowing the system to anticipate needs before they are explicitly signaled.
The eye-in-hand camera configuration, though effective, also reveals a fundamental constraint. Vision, even when precisely targeted, is still external to the user’s internal model of the world. The next iteration of this technology should explore methods of integrating neurophysiological signals, however imperfectly, to create a more direct channel for intent. This is not to suggest a telepathic interface, but rather a system capable of disambiguating ambiguity by referencing the user’s inherent understanding of the task.
Ultimately, the pursuit of assistive robotics is a study in managed complexity. Each added feature, each refined algorithm, risks obscuring the core principle: to simplify, not to replicate. The true measure of success will not be in the sophistication of the technology, but in its ability to vanish from conscious attention, becoming a seamless extension of the user’s own agency.
Original article: https://arxiv.org/pdf/2601.17404.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-01-27 21:15