Author: Denis Avetisyan
Researchers have released a comprehensive dataset to rigorously test the reasoning and decision-making capabilities of AI systems designed for self-driving vehicles.
![The AgentDrive benchmark suite establishes a comprehensive evaluation framework-encompassing generative scenario creation ([latex]AgentDrive-Gen[/latex]), simulated outcome labeling ([latex]AgentDrive-Sim[/latex]), and rigorous reasoning assessment ([latex]AgentDrive-MCQ[/latex])-to measure the capacity of autonomous agents navigating complex driving environments.](https://arxiv.org/html/2601.16964v1/x1.png)
AgentDrive is an open benchmark featuring LLM-generated scenarios to evaluate agentic AI in autonomous systems, focusing on simulation and complex reasoning tasks.
Evaluating and training large language model-driven agents for autonomous systems remains challenging due to a scarcity of comprehensive, safety-focused benchmarks. To address this, we introduce AgentDrive: An Open Benchmark Dataset for Agentic AI Reasoning with LLM-Generated Scenarios in Autonomous Systems, a resource comprising 300,000 LLM-generated driving scenarios and a 100,000-question multiple-choice benchmark designed to assess both simulated performance and reasoning capabilities across diverse conditions. Our results, derived from evaluating fifty leading LLMs, reveal a performance gap between proprietary and open models in contextual reasoning, though open models are rapidly improving in physics-grounded tasks. Will this increased accessibility of robust benchmarks accelerate the development of truly reliable and intelligent autonomous agents?
The Inevitable Complexity of Autonomous Reasoning
Autonomous vehicles currently face significant hurdles when navigating scenarios demanding more than simple object recognition. These systems often struggle with ambiguity, requiring an ability to infer intent and anticipate the actions of other road users – a level of nuanced interpretation that remains elusive. Existing algorithms frequently exhibit limitations in proactive decision-making, reacting to immediate stimuli rather than formulating plans based on predicted outcomes. This deficiency becomes critically apparent in complex interactions – merging onto busy highways, negotiating unprotected left turns, or responding to unpredictable pedestrian behavior – where a system’s capacity for reasoned judgment directly impacts safety and efficiency. The challenge lies not merely in seeing the environment, but in understanding it and formulating appropriate, forward-looking responses.
Conventional autonomous vehicle systems often rely on meticulously crafted rule-based frameworks, but these approaches demonstrate a critical fragility when confronted with the inherent variability of real-world driving. These systems, while effective in narrowly defined scenarios, struggle with even slight deviations from expected conditions – a misplaced traffic cone, an unusual pedestrian action, or inclement weather can all trigger failures. The core limitation lies in their inability to generalize beyond explicitly programmed instructions; each novel situation demands a pre-defined rule, an impossibility given the infinite complexity of the environment. This inflexibility not only compromises safety but also hinders the development of truly autonomous vehicles capable of navigating unpredictable conditions with the same fluidity and adaptability as a human driver. Consequently, research is shifting towards more robust reasoning methods that can learn and adapt to unforeseen circumstances, rather than simply reacting to pre-programmed rules.
Truly intelligent autonomous driving demands more than simply seeing the world; it requires a sophisticated integration of perception, prediction, and planning. Current systems often excel at individual tasks – identifying objects, or charting a basic course – but struggle with the seamless choreography these demand. A vehicle must not only perceive a pedestrian stepping onto the road, but also predict their likely trajectory and then plan a safe, preemptive maneuver. This holistic approach, however, presents a significant computational challenge; the exponential growth of possibilities in complex, dynamic environments quickly overwhelms many existing algorithms. Consequently, autonomous vehicles frequently exhibit cautious, or even indecisive, behavior in situations requiring rapid, nuanced reasoning, highlighting a critical gap between current capabilities and truly robust autonomous operation.
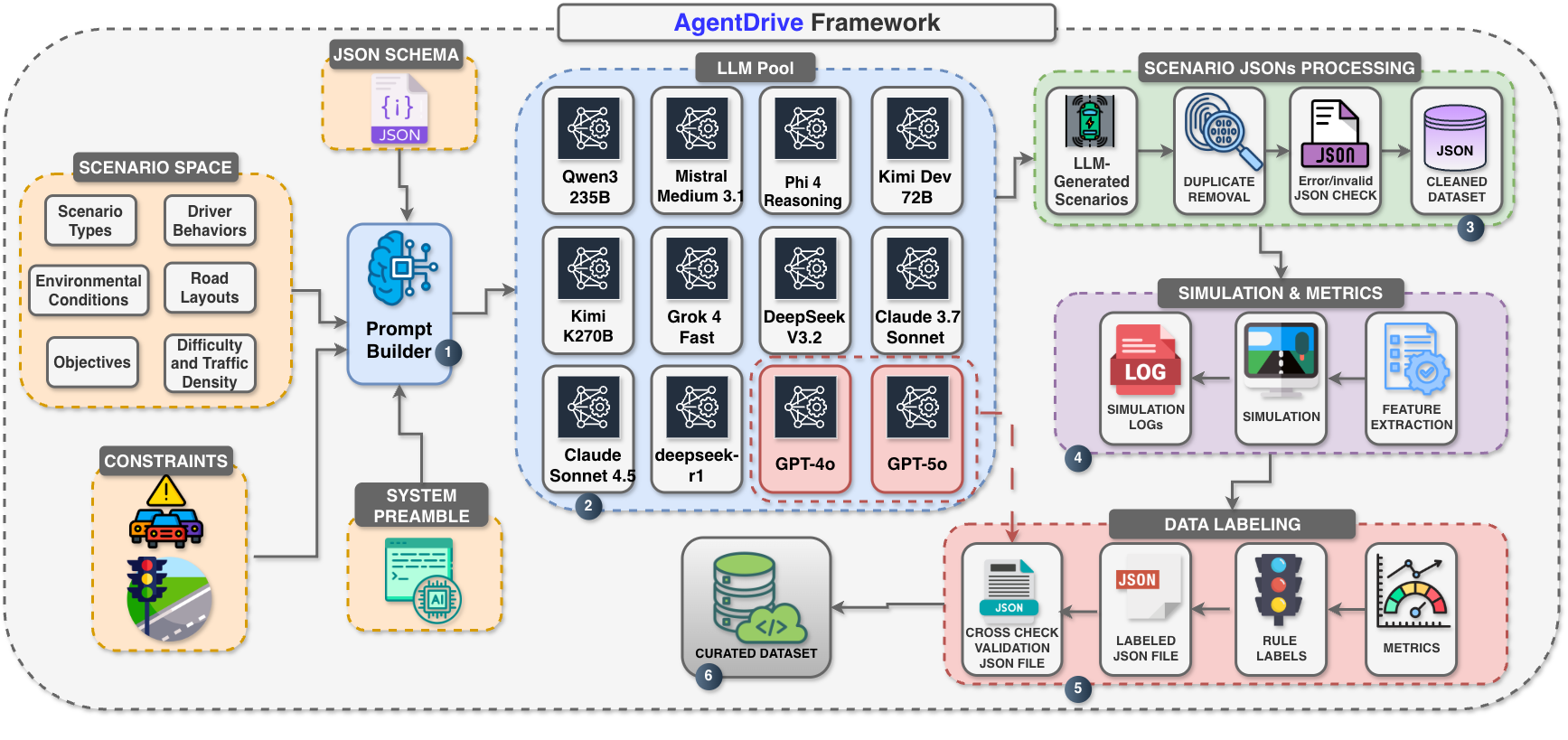
AgentDrive: A Comprehensive Landscape for Reasoning Evaluation
AgentDrive comprises a dataset of 300,000 driving scenarios generated using large language models. This scale of data surpasses existing benchmarks and enables evaluation across a wide range of driving conditions and edge cases. Scenario generation leverages a systematic approach to vary key parameters such as weather, traffic density, road geometry, and the behavior of other agents. The resulting diversity aims to provide more comprehensive testing of autonomous driving systems than previously possible, focusing on situations that require complex reasoning and decision-making beyond simple reactive responses. The dataset is designed to facilitate robust evaluation of perception, prediction, and planning capabilities in autonomous vehicles.
AgentDrive employs a ‘factorized scenario space’ to facilitate exhaustive testing of autonomous driving systems by systematically varying key parameters. This approach decomposes complex driving situations into a set of independent factors – including weather conditions, traffic density, pedestrian behavior, road geometry, and vehicle dynamics – allowing for the generation of a large number of unique scenarios through combinatorial variation. By controlling and altering these parameters, AgentDrive ensures comprehensive evaluation across a broad spectrum of conditions, addressing limitations of existing benchmarks which often focus on a narrow range of pre-defined situations and enabling targeted assessment of agent performance in specific edge cases.
AgentDrive-MCQ is a reasoning benchmark designed to evaluate the cognitive abilities of autonomous driving agents and consists of 100,000 multiple-choice questions. These questions are formulated to assess an agent’s understanding of traffic laws, hazard prediction, and decision-making in complex scenarios. The benchmark is directly linked to the AgentDrive simulation environment, allowing for correlation between performance on the multiple-choice questions and actual driving behavior. Question types cover areas such as identifying safe actions, predicting the behavior of other road users, and interpreting ambiguous situations, providing a granular assessment of reasoning capabilities beyond simple action output.
Simulation rollouts within the AgentDrive framework constitute a crucial evaluation component by deploying agents within a physics-based driving simulator. These rollouts allow for the measurement of key performance indicators, including collision rates, average speed, and success/failure rates in completing defined driving tasks. By executing scenarios thousands of times, the framework gathers statistically significant data on agent behavior under varying conditions, facilitating a robust assessment of both safety – minimizing hazardous events – and efficiency, quantified by metrics such as time-to-completion and energy consumption. This process moves beyond static analysis and provides a dynamic, quantifiable evaluation of agent performance in realistic, complex driving situations.

Grounding Intelligence: The Interplay of Perception, Policy, and Physics
Effective autonomous driving requires a reasoning system that integrates multiple information modalities. Specifically, the system must process symbolic knowledge, such as traffic laws and route planning data; numerical data representing physical constraints like vehicle dynamics, speed, and distance; and contextual information derived from sensor input regarding surrounding objects, road conditions, and pedestrian behavior. This hybrid approach is necessary because reliance on a single data type is insufficient for safe and reliable navigation; for example, understanding a traffic signal (symbolic) requires correlating it with the vehicle’s position and velocity (numerical) within the current driving environment (contextual). A robust system dynamically combines these elements to facilitate informed decision-making and appropriate vehicle control.
Policy-based reasoning is a fundamental requirement for autonomous vehicle operation, necessitating the capacity to interpret and adhere to established traffic laws and regulations. This is typically achieved through the implementation of Traffic Regulation Retrieval modules, which function by accessing and processing a database of legal requirements relevant to driving. These modules identify applicable rules based on the vehicle’s location, surrounding environment, and observed traffic conditions. Successful retrieval enables the LLM to reason about permissible actions – such as speed limits, lane restrictions, right-of-way protocols, and signaling requirements – and ensures the vehicle’s behavior remains compliant with legal standards, mitigating potential liabilities and enhancing road safety.
Physics-based reasoning within autonomous driving systems necessitates the modeling of vehicle dynamics and environmental interactions to predict future states and ensure safe operation. This involves calculating parameters such as velocity, acceleration, and trajectory based on physical principles, including [latex]F = ma[/latex] (Newton’s second law of motion) and considerations for friction, gravity, and aerodynamic drag. Accurate prediction of these factors is crucial for collision avoidance, enabling the vehicle to anticipate potential hazards and execute appropriate maneuvers. Furthermore, physics-based reasoning facilitates realistic simulation and validation of autonomous driving algorithms, allowing for robust performance evaluation under diverse and challenging conditions. The system must account for the physical limitations of the vehicle, such as braking distance and turning radius, to generate feasible and safe trajectories.
The fusion of multimodal data through the Multimodal Autoregressive Predictive Language Model (MAPLM) with DETR-based (DEtection TRansformer) perception substantially improves an LLM’s environmental understanding. DETR’s object detection capabilities provide the LLM with precise bounding box coordinates and class labels for surrounding elements, while MAPLM processes and integrates this visual data with other sensory inputs, such as LiDAR point clouds and vehicle telemetry. This combined approach allows the LLM to move beyond simple object recognition to a more comprehensive scene interpretation, enabling accurate identification of dynamic agents, prediction of their trajectories, and ultimately, informed decision-making for autonomous navigation. The autoregressive nature of MAPLM further facilitates reasoning about temporal relationships within the perceived environment.
Ensuring Robustness: Advanced Frameworks for Validation and Safety
Evaluating the safety of autonomous systems demands more than just pass/fail criteria; it requires nuanced, quantifiable metrics. Surrogate safety measures, prominently including Time-to-Collision (TTC), offer a powerful solution by continuously assessing the nearness of potential collisions during simulated driving scenarios. TTC calculates the time remaining until an impact, assuming current trajectories hold – a lower TTC value indicating a more hazardous situation. By tracking TTC across countless simulated miles, developers gain statistically significant insights into an agent’s risk profile, enabling targeted improvements to decision-making algorithms and control systems. This approach allows for proactive hazard mitigation, moving beyond reactive collision avoidance and fostering a robust safety validation process that complements traditional testing methods, ultimately building confidence in the reliability of autonomous vehicles.
Rule-based labeling offers a systematic approach to understanding the behavior of autonomous systems within complex simulations. Rather than relying solely on pass/fail metrics, this technique categorizes each simulation ‘rollout’ – a complete run of the scenario – based on predefined rules reflecting specific safety or performance criteria. For example, a rollout might be labeled as ‘near-miss’, ‘safe-following’, or ‘aggressive-maneuver’ depending on the actions taken by the agent. This granular categorization is invaluable for debugging, allowing developers to pinpoint the precise conditions that trigger undesirable behavior. Furthermore, it enables robust validation by providing interpretable data on how the system responds to a diverse range of scenarios, fostering confidence in its reliability and paving the way for targeted improvements.
The Superalignment Framework addresses critical safety and ethical concerns inherent in deploying Large Language Models (LLMs) within autonomous vehicles. This framework isn’t simply about ensuring the car drives well, but verifying that its decisions consistently adhere to pre-defined security protocols and policy constraints, even in unforeseen circumstances. It achieves this through rigorous data validation – confirming the training data isn’t compromised or biased – and robust policy enforcement, guaranteeing the LLM prioritizes passenger safety, respects traffic laws, and operates within legal boundaries. By establishing a verifiable alignment between the LLM’s internal reasoning and externally defined rules, the Superalignment Framework mitigates risks associated with unpredictable or malicious behavior, fostering trust and enabling responsible innovation in the field of autonomous driving.
Bench2ADVLM represents a significant advancement in the evaluation of autonomous driving systems, specifically those reliant on vision-language models. This closed-loop framework doesn’t merely present static scenarios; instead, it allows the AD model to interact with a dynamic environment, responding to unfolding events and making decisions in real-time. By creating this interactive loop, Bench2ADVLM exposes vulnerabilities often missed by traditional, passive evaluation methods – for example, how the system reacts to unexpected pedestrian behavior or ambiguous traffic signals. The resulting data reveals not only what went wrong, but why, pinpointing specific areas where the vision-language model requires improvement in its perception, reasoning, and decision-making capabilities. Ultimately, this rigorous testing process fosters the development of more robust and reliable autonomous driving systems prepared for the complexities of real-world conditions.
Towards Adaptive Intelligence: The Future of Autonomous Systems
DriVLMe signifies a notable advancement in the development of autonomous driving agents, moving beyond purely functional navigation to incorporate elements of embodied and social intelligence. This system distinguishes itself by equipping large language models (LLMs) not only with the ability to interpret sensor data and plan routes, but also to understand and respond to the nuances of a dynamic driving environment – including the behaviors of other road users and unpredictable events. By simulating realistic, interactive driving scenarios, DriVLMe allows LLMs to develop a more comprehensive understanding of the world, enabling more natural and safer interactions with both the physical environment and other agents. This approach promises a future where autonomous vehicles are not merely robotic drivers, but integrated participants in the complex social ecosystem of our roads, capable of anticipating, adapting, and collaborating to improve overall traffic flow and safety.
Advancing autonomous systems beyond current capabilities necessitates a focused exploration of hybrid reasoning and multimodal perception. Hybrid reasoning seeks to combine the strengths of different AI approaches – such as symbolic reasoning and deep learning – to create more robust and explainable decision-making processes. Simultaneously, expanding perception beyond simple vision to incorporate data from diverse sensors – including lidar, radar, and audio – enables a more comprehensive understanding of the environment. These combined advancements promise to address critical limitations in current systems, improving their ability to navigate complex scenarios, anticipate unforeseen events, and ultimately achieve greater levels of safety and reliability in real-world applications. Continued investment in these areas is poised to unlock the full potential of autonomous technology, paving the way for truly adaptive and intelligent systems.
The development of truly autonomous systems demands rigorous and standardized evaluation, and the AgentDrive benchmark is emerging as a pivotal tool in this process. This comprehensive platform assesses the capabilities of large language models (LLMs) when applied to complex driving scenarios, moving beyond simple simulations to test reasoning and decision-making in realistic, physics-based environments. Notably, AgentDrive has facilitated the evaluation of fifty prominent LLMs, providing a comparative landscape of performance and identifying key strengths and weaknesses across different models. The benchmark doesn’t merely report overall accuracy; it dissects performance across crucial areas like policy reasoning and physics understanding, offering granular insights that guide further research and development. By providing a consistent and challenging testing ground, AgentDrive is accelerating progress towards safer, more reliable, and truly adaptive autonomous systems.
Recent evaluations utilizing the AgentDrive benchmark reveal ChatGPT-4o currently leads the field of large language model-driven autonomous systems, achieving an impressive overall accuracy of 82.5%. This performance surpasses that of fifty other leading models assessed on the same platform. Notably, the system demonstrated flawless performance in the critical area of policy reasoning – the ability to determine appropriate actions based on situational understanding. This suggests ChatGPT-4o exhibits a particularly strong capacity for decision-making within complex, simulated driving scenarios, representing a significant advancement toward more reliable and intelligent autonomous agents.
Among open-source large language models vying to power the next generation of autonomous systems, Qwen3 235B A22B currently demonstrates leading performance. Evaluations on the AgentDrive benchmark reveal an overall accuracy of 81.0%, positioning it as a strong contender in the development of LLM-driven agents. Notably, the model excels in physics reasoning, achieving an accuracy of 67.5%-a critical capability for navigating complex, real-world scenarios and ensuring safe, reliable operation of autonomous vehicles and robots. This level of performance suggests Qwen3 235B A22B provides a robust foundation for continued research and adaptation in the field of embodied artificial intelligence.
The introduction of AgentDrive signifies more than just a new benchmark; it acknowledges the inevitable entropy within complex systems. Each scenario generated, each simulation run, contributes to a growing understanding of limitations and failure points. As systems evolve, their initial elegance gives way to accumulated complexities, demanding constant refinement. This echoes Blaise Pascal’s observation: “All of humanity’s problems stem from man’s inability to sit quietly in a room alone.” AgentDrive, by forcing rigorous evaluation of agentic AI, offers a means to confront these inherent challenges, to ‘sit quietly’ with the system’s shortcomings, and to proactively address decay before it compromises functionality. The dataset’s focus on reasoning within autonomous driving highlights the necessity of anticipating future states, a direct engagement with the relentless passage of time and its impact on system performance.
What Lies Ahead?
The introduction of AgentDrive represents, predictably, not an arrival, but a more precisely defined departure point. Each commit to this benchmark-every generated scenario, every evaluated response-is a record in the annals, and each version a chapter in the ongoing saga of autonomous systems. The challenge, as always, isn’t simply achieving functionality, but enduring it. The dataset’s strength lies in its breadth, yet the true test will be its depth-how readily can these agentic systems extrapolate beyond the presented conditions, and adapt to the unforeseen, the genuinely novel?
Currently, the focus rests on simulation. However, the translation of reasoned responses into reliable action remains a critical gap. Delaying fixes to this translational latency is a tax on ambition; a beautifully articulated plan is, ultimately, insufficient without dependable execution. Furthermore, the inherent limitations of LLM-generated scenarios-their dependence on the training data, their potential for subtle biases-must be continually addressed.
Future iterations will likely demand not merely improved performance within the simulation, but demonstrable robustness against adversarial inputs and a more nuanced understanding of uncertainty. The metric isn’t simply ‘success’ or ‘failure,’ but the grace with which a system degrades, the elegance of its adaptation in the face of inevitable decay. The question isn’t whether these systems will falter, but how.
Original article: https://arxiv.org/pdf/2601.16964.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-01-27 02:37