Author: Denis Avetisyan
A new reinforcement learning framework enables agricultural robots to autonomously plan energy-efficient paths for comprehensive field coverage.
This study demonstrates a Soft Actor-Critic approach to coverage path planning, achieving improved performance and reduced energy constraint violations in grid-based agricultural environments.
Effective agricultural robotics demands robust autonomy, yet existing coverage path planning methods often neglect critical energy constraints, limiting operational scale. This paper introduces a novel framework for ‘Reinforcement Learning-Based Energy-Aware Coverage Path Planning for Precision Agriculture’– leveraging Soft Actor-Critic (SAC) reinforcement learning to navigate grid-based environments with obstacles and charging stations. Experimental results demonstrate that the proposed approach consistently achieves over 90% coverage while significantly reducing energy constraint violations compared to traditional algorithms. Could this energy-aware planning framework unlock truly scalable and sustainable precision agriculture solutions?
Decoding the Autonomous Path: Beyond Simple Navigation
The ability of a mobile robot to function effectively within unpredictable, real-world settings hinges on sophisticated coverage path planning. This isn’t simply about reaching a destination; it requires the robot to systematically explore and map its surroundings, ensuring no area remains unvisited while optimizing its route. Efficient coverage demands algorithms that balance thoroughness with speed, allowing the robot to build a comprehensive understanding of the environment. Consequently, researchers are developing methods that move beyond simple grid-based approaches, incorporating techniques like boustrophedon decomposition, spiral patterns, and rapidly-exploring random trees to navigate complex spaces. The ultimate goal is to enable robots to autonomously perform tasks – from environmental monitoring and search-and-rescue operations to precision agriculture and automated inspection – without constant human intervention, and a robust coverage plan is foundational to achieving that independence.
Conventional autonomous navigation strategies frequently prioritize path length or speed, overlooking the substantial impact of energy expenditure on a robot’s functional duration. This oversight is particularly problematic in real-world deployments where robots must operate for extended periods without intervention. Minimizing energy use isn’t simply about traveling shorter distances; it involves optimizing for factors like motor efficiency, minimizing unnecessary accelerations and decelerations, and strategically managing sensor usage. A path that appears shortest may demand significantly more power if it requires frequent turning or traversing uneven terrain. Consequently, neglecting energy consumption can dramatically curtail a robot’s operational lifespan, rendering even the most sophisticated navigation algorithms impractical for long-term, sustained tasks. Recent research suggests that incorporating energy-aware path planning can extend operational time by up to 30% compared to traditional methods, highlighting the crucial need to address this often-overlooked constraint.
While robotic navigation has made significant strides in obstacle avoidance, ensuring a robot can complete a task requires more than simply finding a path around impediments. A robot capable of circumventing every obstacle still faces limitations if its energy reserves are depleted before the mission is fulfilled. Research demonstrates that naive path planning, focused solely on distance or time, often results in unnecessarily complex trajectories and excessive energy expenditure. Consequently, algorithms are increasingly designed to integrate energy consumption as a core optimization parameter, prioritizing routes that minimize not only travel distance but also factors like motor strain, velocity changes, and the need for frequent re-planning due to dynamic environments-ultimately extending operational lifespan and ensuring task completion even in challenging conditions.
![The robot achieves near-complete coverage ([latex] \approx 95\% [/latex]) of the simplest map after 400 training episodes, and consistently covers over 90% of the more complex maps in later stages, demonstrating effective adaptation to varying environments.](https://arxiv.org/html/2601.16405v1/x10.png)
Learning to Roam: Reinforcement Learning and the Energy Equation
Reinforcement Learning (RL) offers a computational approach to robot navigation by enabling the development of policies through trial-and-error interaction with its environment. Unlike pre-programmed routes, RL algorithms allow a robot to autonomously discover optimal paths based on received rewards or penalties. This is achieved by framing the navigation task as a Markov Decision Process (MDP), where the robot (agent) observes the environment (state), takes actions, and receives feedback in the form of a reward signal. Through repeated interactions, the RL agent learns a policy – a mapping from states to actions – that maximizes its cumulative reward, effectively learning to navigate efficiently and adapt to dynamic environmental changes without explicit programming for every scenario.
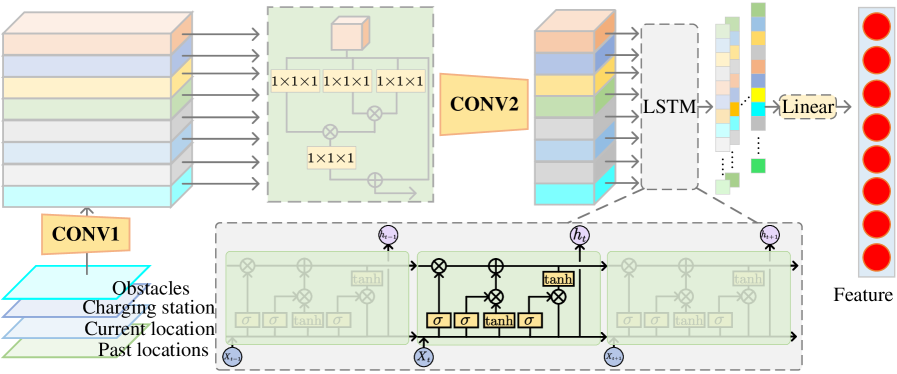
The Soft Actor-Critic (SAC) algorithm is an off-policy reinforcement learning method particularly suited for continuous action spaces and complex tasks. SAC maximizes a trade-off between expected return and entropy, encouraging exploration and preventing premature convergence to suboptimal policies. Its efficiency in long-horizon tasks is further enhanced by the integration of Long Short-Term Memory (LSTM) networks within the actor and critic components. LSTMs allow the algorithm to maintain a memory of past states and actions, enabling it to learn temporal dependencies and effectively plan over extended sequences, crucial for navigation tasks where distant actions influence current energy expenditure and path optimality. This memory capability improves sample efficiency and allows SAC to learn robust policies even with sparse or delayed rewards.
Effective reinforcement learning for robotic navigation requires a state representation capable of capturing relevant environmental information. A robust approach combines techniques such as Convolutional Neural Networks (CNNs) to process visual inputs – like camera images – extracting spatial features, and Self-Attention Mechanisms to model relationships between different parts of the observed state. The CNNs automatically learn hierarchical representations from raw sensory data, reducing the dimensionality of the input, while self-attention allows the agent to focus on the most pertinent features within the state, improving generalization and performance in complex environments. This combined approach facilitates the learning of optimal policies by providing the agent with a concise and informative understanding of its surroundings.
Robot operation within the defined environment is contingent upon the availability of a charging station for energy replenishment. Continuous operation is not feasible due to the finite energy capacity of the robot’s battery; therefore, the robot must periodically return to the charging station to resume functionality. The location and accessibility of this charging station directly impact path planning and overall task completion rates. The reinforcement learning framework incorporates the charging station as a critical element within the state space, allowing the robot to learn policies that balance task objectives with energy constraints and charging necessities. Failure to access the charging station results in task termination due to depleted battery levels.
Mapping Efficiency: Algorithms and the Pursuit of Complete Coverage
Energy-aware navigation strategies are critical for robotic systems operating with limited power resources. These strategies move beyond simple path planning to actively consider energy expenditure during trajectory generation and execution. Minimizing energy consumption is achieved through optimization of robot speed, acceleration, and selection of traversable terrain, all while maintaining mission objectives. Prolonged operational time is a direct result of reduced energy draw, enabling extended data collection, surveillance, or exploration capabilities. Implementation often involves modifying classic path planning algorithms to include energy cost as a key weighting factor alongside distance and time, leading to more efficient and sustainable robotic operation.
A grid map represents the operational environment as a two-dimensional array of cells, each denoting occupancy or free space. This discrete representation simplifies spatial reasoning and enables efficient path planning by reducing continuous space into a finite set of navigable locations. The grid structure facilitates the application of algorithms such as A* and Dijkstra’s algorithm for finding optimal or near-optimal paths, while also allowing for straightforward collision detection. Furthermore, grid maps enable the quantification of unexplored areas, informing the navigation strategy and ensuring comprehensive coverage of the environment. The resolution of the grid impacts both computational cost and path accuracy; higher resolution grids provide more detailed representations but require greater processing power.
Established path planning algorithms – Rapidly-exploring Random Trees (RRT), Ant Colony Optimization (ACO), and Particle Swarm Optimization (PSO) – can be adapted to address energy efficiency by modifying their cost functions. Traditional implementations prioritize path length or directness; incorporating energy consumption as a weighted factor within these cost functions allows the algorithms to favor paths that minimize energy expenditure, even if those paths are not the shortest. This is achieved by estimating energy usage based on factors such as robot speed, terrain type, and operational constraints, and integrating these estimates into the path evaluation process. By adjusting the weighting of energy consumption relative to other path characteristics, a trade-off between coverage and energy efficiency can be established to meet specific operational requirements.
Coverage rate serves as the primary metric for evaluating the performance of the autonomous navigation framework. This metric quantifies the percentage of the operational area successfully traversed by the system during a defined period. Across three distinct map configurations – representing varying environmental complexities – the framework consistently achieved coverage rates exceeding 90%. This indicates a high degree of spatial awareness and efficient path planning, ensuring comprehensive area coverage despite obstacles and constraints within the operational environment. The consistently high coverage rate demonstrates the robustness and adaptability of the implemented algorithms across diverse scenarios.
Constraint violations, representing instances where the navigation system exceeds operational limits or collides with obstacles, were significantly reduced using the proposed approach. Comparative analysis against the Rapidly-exploring Random Tree (RRT) algorithm demonstrates an 83% to 85% decrease in these violations across all tested map configurations. This improvement indicates a higher degree of operational reliability and safety, as the system more consistently adheres to predefined boundaries and avoids collisions during navigation. The reduction in constraint violations directly contributes to extended operational lifespan and minimized risk of system failure.
Comparative analysis of the implemented algorithms across three distinct map configurations – designated Maps 1, 2, and 3 – demonstrated consistent improvements in coverage rate. Specifically, the developed approach achieved a 7.3% higher coverage rate than the second-best performing algorithm on Map 1. This performance increase was sustained on Maps 2 and 3, with improvements of 8.0% and 9.1% respectively, indicating a consistent advantage in environmental coverage across varied spatial layouts. These gains were quantified using the established coverage rate metric, providing a statistically verifiable measure of performance enhancement.
![Experiments were conducted across three maps-simple with evenly distributed stations, complex with clustered obstacles, and challenging with irregular patterns-each representing a [latex]1m \times 1m[/latex] area of an agricultural field with green indicating charging stations and black indicating obstacles.](https://arxiv.org/html/2601.16405v1/x4.png)
Beyond Automation: The Expanding Horizon of Autonomous Systems
The convergence of reinforcement learning and sophisticated path planning algorithms is rapidly enabling the development of genuinely autonomous mobile robots capable of undertaking diverse tasks. These robots move beyond pre-programmed routines by learning optimal behaviors through trial and error within complex environments. By leveraging reinforcement learning, robots can adapt to unforeseen obstacles and dynamically adjust their trajectories, while advanced path planning ensures efficient and safe navigation. This synergy isn’t merely about automating existing processes; it’s about creating robots that can independently assess situations, formulate strategies, and execute tasks with a level of flexibility previously unattainable, opening doors for applications ranging from logistical operations and search-and-rescue missions to precision agriculture and environmental monitoring.
The development of autonomous mobile robots promises a revolution in agricultural practices, offering solutions for efficient crop monitoring and precision weeding. These robots, guided by advanced algorithms, can navigate fields, identify weeds with remarkable accuracy, and remove them mechanically or with targeted herbicide application – significantly reducing the overall chemical load on the environment. This approach minimizes soil disruption and promotes healthier ecosystems, while simultaneously decreasing labor costs and increasing crop yields. The potential extends beyond simple weed control, offering capabilities for detailed plant health assessments, early disease detection, and optimized irrigation strategies, ultimately contributing to a more sustainable and productive agricultural future.
Continued development prioritizes enhancing the adaptability of these robotic algorithms to real-world conditions, which are rarely static or predictable. Current research investigates methods to improve performance when faced with unforeseen obstacles, changing lighting, or variations in terrain and plant growth. This includes incorporating sensor fusion techniques, leveraging more sophisticated state estimation, and exploring reinforcement learning approaches that emphasize generalization and rapid adaptation. Ultimately, the goal is to create autonomous systems capable of reliably navigating and operating in complex agricultural environments, even as conditions shift unexpectedly, thereby maximizing efficiency and minimizing the need for human intervention.
Continued advancements in autonomous robotic systems hinge on refining how these robots perceive and interpret their surroundings, a process defined by the ‘State Representation’. Current research indicates that a more nuanced and efficient encoding of environmental data-incorporating not only immediate sensor readings but also predictive modeling of potential changes-could dramatically improve performance. Simultaneously, exploring reinforcement learning algorithms beyond conventional methods-such as those integrating hierarchical structures or intrinsic motivation-promises to address limitations in complex, real-world scenarios. These combined efforts aim to move beyond task-specific training, fostering robots capable of adapting and generalizing their skills to previously unseen challenges, ultimately unlocking a far greater level of autonomy and practical application.
Achieving robust autonomous navigation for mobile robots demands substantial computational resources, and the training phase of the developed algorithms is no exception. Utilizing a high-end NVIDIA RTX 3090 GPU, the entire reinforcement learning process, from initial exploration to policy convergence, currently requires approximately 1.8 hours. This timeframe reflects the complexity of the state space and the iterative nature of the learning process, where the robot virtually explores numerous scenarios to refine its path planning capabilities. While this duration represents a significant advancement towards practical deployment, ongoing research focuses on algorithmic optimizations and potential hardware acceleration to further reduce training times and enable even more rapid adaptation to new environments and tasks.
The pursuit of optimized navigation, as detailed in the study, echoes a fundamental principle of systemic understanding. The framework’s iterative refinement of coverage paths through reinforcement learning isn’t merely about efficiency; it’s about probing the limits of the operational space, exposing vulnerabilities within the defined constraints. As Bertrand Russell observed, “The only way to deal with an unfree world is to become so absolutely free that your very existence is an act of rebellion.” This holds true for the agricultural robot; its relentless pursuit of energy-aware coverage, constantly testing and adapting its path, embodies a rejection of static limitations and a drive to maximize operational freedom within a complex environment. The robot, in essence, ‘confesses’ the design sins of the environment by pushing against its boundaries.
What Lies Beyond the Field?
The pursuit of efficient coverage, as demonstrated by this work, invariably leads one to question the very definition of ‘coverage’ itself. Is complete traversal truly the optimal strategy, or does a nuanced understanding of crop variability-identifying zones of diminishing returns-demand a more selective approach? The algorithm excels within the constraints of a grid-based environment, but real agricultural fields are gloriously, frustratingly irregular. One wonders if the ‘obstacles’ avoided aren’t, in fact, information – indicators of soil composition, pest concentration, or subtle shifts in plant health.
The energy constraint, while pragmatic, feels… limiting. It presupposes a finite resource, a static battery life. But what if the ‘violation’ of that constraint – the deliberate push towards energy expenditure – unlocks a faster data acquisition rate, allowing for preemptive intervention before problems escalate? Perhaps the true metric isn’t minimizing energy used, but maximizing information gained per unit of energy.
Future iterations should, perhaps, abandon the pursuit of a ‘path’ altogether. Instead of planning a route, the system could learn to ‘seed’ the field with sensors, adapting in real-time to emergent data. The robot ceases to be a planner, and becomes a responsive element within a larger, self-organizing network. The bug isn’t a flaw, but a signal, indicating the need to redefine the problem itself.
Original article: https://arxiv.org/pdf/2601.16405.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-01-27 02:35