Author: Denis Avetisyan
A novel memory framework allows AI agents to better understand and predict user behavior by evolving individual experiences into collective insights.
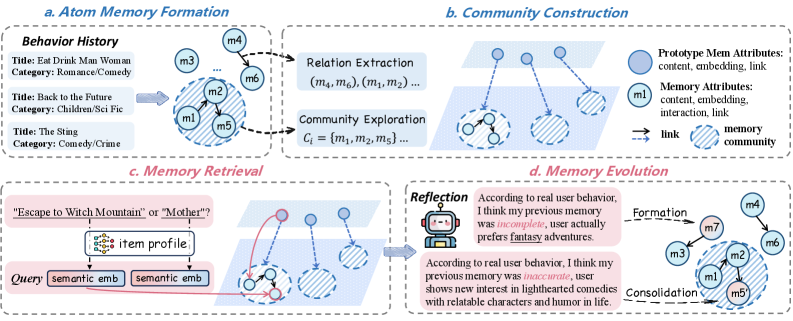
This paper introduces STEAM, a self-evolving memory system that leverages atomic memory units and community construction to enhance user behavior modeling in recommendation systems.
Effective user behavior modeling requires nuanced preference representation, yet current large language model (LLM) approaches often rely on simplistic, unstructured memory updates. This paper, ‘From Atom to Community: Structured and Evolving Agent Memory for User Behavior Modeling’, introduces STEAM, a novel framework that reimagines agent memory through fine-grained, atomic units and community-based knowledge propagation. By decomposing preferences and enabling adaptive memory evolution, STEAM demonstrably outperforms existing methods in recommendation accuracy and simulation fidelity. Could this approach unlock more robust and personalized experiences beyond recommendation systems, fostering truly intelligent agents capable of long-term user understanding?
Beyond Recall: The Limits of Static Agent Memory
The rising prevalence of large language model (LLM)-based agents in tackling intricate tasks-from automated scheduling and research to personalized assistance-is fundamentally dependent on their ability to effectively manage information over time. These agents don’t simply respond; they are intended to learn from each interaction and refine their actions accordingly. However, this capacity for adaptive behavior is critically constrained by how well they store, retrieve, and utilize past experiences. Unlike traditional programs with explicitly defined states, LLM agents rely on capturing the essence of interactions – the user’s goals, preferences, and the evolving context of the task – within their ‘memory’. Consequently, the performance of these agents isn’t solely about the power of the underlying language model, but also about the sophistication of the mechanisms used to retain and access relevant information, ultimately determining their usefulness in dynamic, real-world applications.
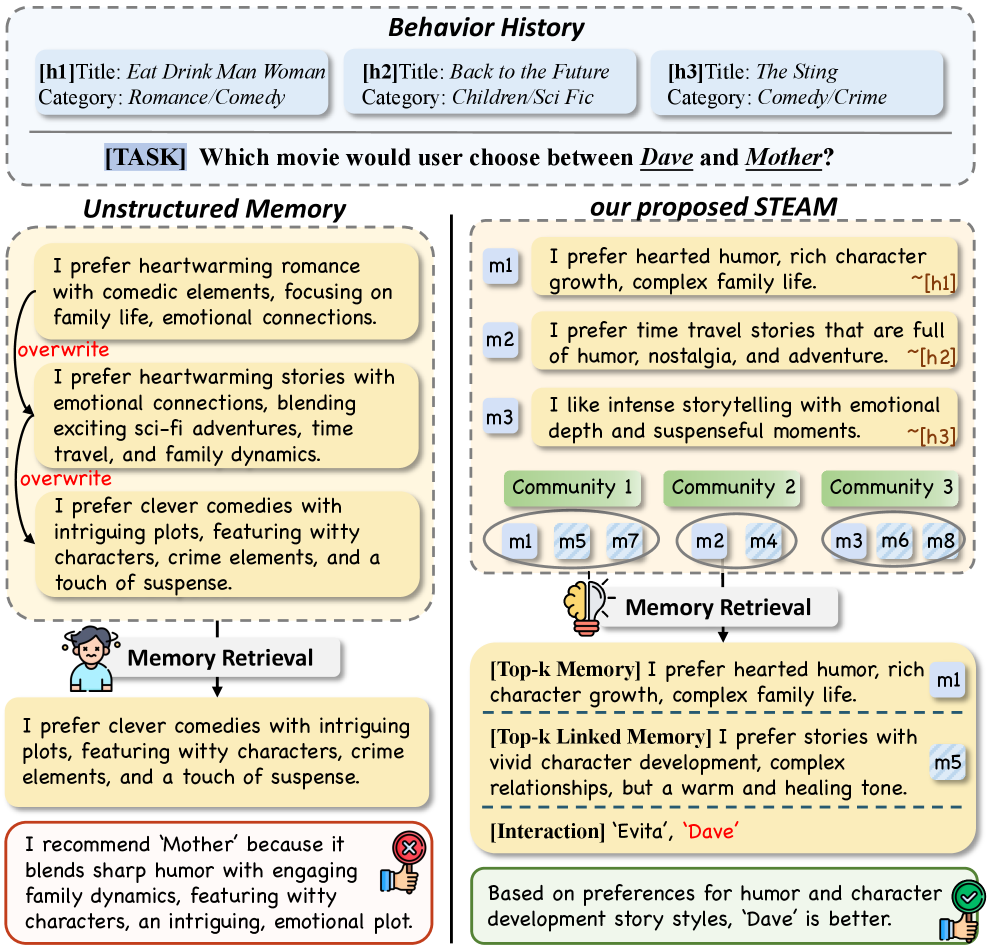
The efficacy of large language model agents often relies on a ‘Single Summary Memory’ – a condensed recollection of past interactions. However, this approach demonstrably falters when faced with the subtleties of extended dialogue or complex task execution. By distilling interactions into a monolithic summary, crucial contextual details and nuanced preferences are inevitably lost. This simplification results in a flattened representation of user intent, hindering the agent’s ability to differentiate between similar requests or adapt to evolving needs. Consequently, the agent may offer generic, unhelpful responses, or struggle to maintain coherence across multiple turns, ultimately limiting its practical application in scenarios demanding a deep understanding of user history and intent.
The reliance on condensed summaries as long-term memory for LLM agents often results in recommendations lacking personalization and foresight. By distilling interactions into brief overviews, crucial details regarding user intent, evolving needs, and previously expressed preferences are frequently lost. This inability to retain and leverage granular context effectively diminishes the agent’s capacity to provide truly tailored responses or anticipate future requests. Consequently, the agent’s utility degrades over time as it struggles to move beyond superficial understanding, ultimately hindering its ability to function as a genuinely adaptive and helpful assistant capable of sustained, meaningful engagement.
Deconstructing Memory: Introducing STEAM
STEAM utilizes ‘Atomic Memory Units’ as the fundamental building blocks of long-term agent memory, representing user interests with a granularity exceeding that of traditional summarization techniques. These units are not comprehensive digests of information, but rather discrete, focused representations of specific facts, concepts, or observations. This approach allows for more precise recall and reasoning, as the agent can access and combine individual units relevant to a query, rather than relying on potentially imprecise or incomplete summaries. The fine-grained nature of Atomic Memory Units facilitates nuanced understanding and enables the agent to adapt to evolving user preferences with greater accuracy, as individual units can be updated or refined without requiring the re-processing of large monolithic memory structures.
Memory Communities within the STEAM framework represent a non-hierarchical organization of Atomic Memory Units based on identified semantic relationships. This structure moves beyond simple keyword association, utilizing LLM backbones to determine conceptual similarity and relatedness between units, even across disparate topics. Consequently, information isn’t stored in isolated silos; instead, relevant memories are grouped to facilitate knowledge transfer and collaborative reasoning. This interconnectedness enables the system to retrieve not only directly relevant information, but also related concepts, improving contextual understanding and the ability to draw inferences from the stored data.
STEAM utilizes Event Segmentation Theory, a cognitive science principle, to organize agent memory. This theory posits that humans do not perceive time as a continuous stream, but rather as a sequence of discrete, bounded events defined by shifts in attention and context. Within STEAM, this is implemented by structuring memories around identifiable event boundaries, allowing for more efficient recall and reasoning. The system identifies changes in situational factors – such as shifts in actors, locations, or goals – to delineate these events. By mirroring this human cognitive process, STEAM aims to create a memory architecture that is both intuitive and effective for long-term information retention and retrieval, facilitating more relevant and context-aware responses.
STEAM’s architecture relies on Large Language Model (LLM) backbones to provide core reasoning capabilities. These LLMs are not merely used for text generation but function as the engine for processing, interpreting, and relating Atomic Memory Units within Memory Communities. Specifically, the LLMs facilitate tasks such as semantic similarity assessment, inference of relationships between concepts, and the construction of contextualized responses. The selection of LLM backbone allows for adaptability; different models can be integrated to optimize performance based on specific reasoning requirements or computational constraints. Furthermore, the LLM’s ability to perform few-shot or zero-shot learning enhances STEAM’s capacity to generalize knowledge and handle novel situations without extensive retraining.
Proving the Architecture: Validating STEAM’s Predictive Power
User simulation is employed as the primary validation method for STEAM, evaluating its capacity to forecast user interactions with recommended items. This process involves constructing synthetic user behaviors based on historical data, then comparing STEAM’s predicted actions – such as item clicks or purchases – against the simulated ground truth. The accuracy of these predictions is crucial for demonstrating the framework’s effectiveness in mirroring real-world user preferences and decision-making processes. By systematically comparing predicted and actual user behaviors, we quantify STEAM’s ability to generalize beyond the training data and provide relevant recommendations in a realistic context.
Evaluation of STEAM’s predictive performance utilizes Precision and F1 Score as primary metrics. Precision, calculated as the ratio of correctly predicted relevant items to the total number of items predicted, measures the accuracy of positive predictions. The F1 Score represents the harmonic mean of Precision and Recall – Recall being the ratio of correctly predicted relevant items to the total number of actually relevant items – providing a balanced measure of the system’s accuracy. Comparative analysis consistently demonstrates that STEAM achieves significantly higher Precision and F1 Scores across multiple datasets when benchmarked against traditional collaborative filtering methods, indicating an improved capacity to accurately predict user preferences and behaviors. These gains are statistically significant, validating the efficacy of the STEAM framework.
Normalized Discounted Cumulative Gain at 10 (NDCG@10) was used to consistently evaluate the framework’s performance across all tested datasets and Large Language Model (LLM) backbones. NDCG@10 measures the ranking quality of the top 10 recommendations, prioritizing highly relevant items appearing earlier in the list. Results indicate that the framework achieves robust and stable performance, consistently yielding high NDCG@10 scores regardless of the dataset or LLM used, demonstrating its generalizability and effectiveness in predicting user preferences across varying conditions. This metric provides a standardized and reliable measure of ranking accuracy, allowing for direct comparison against other recommendation systems.
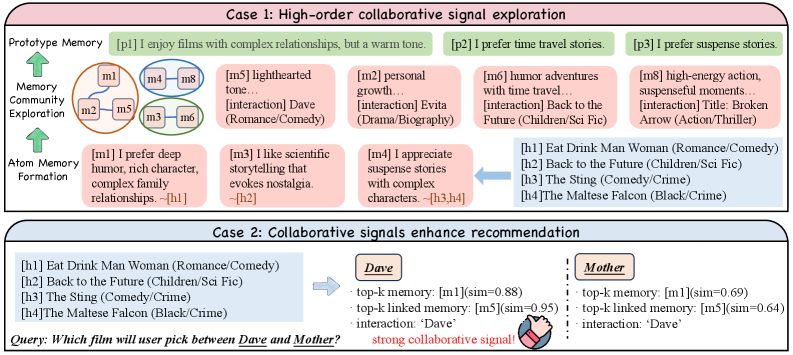
STEAM exhibits enhanced performance on datasets with limited user-item interaction data due to its propagation of explicit collaborative signals. This mechanism effectively identifies and leverages shared interests between users, even with sparse interaction histories. By disseminating signals based on observed collaborations – such as co-purchases or co-views – the framework constructs broader and more meaningful interest communities. This is particularly impactful in sparse datasets where traditional collaborative filtering methods struggle to establish robust connections, leading to improved recommendation accuracy and coverage by capturing latent relationships not readily apparent from individual user behaviors.
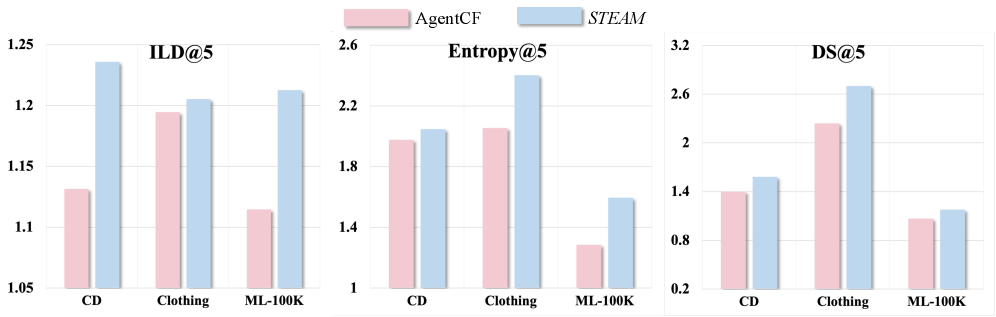
Recommendation diversity was quantitatively assessed using three metrics: Diversity Score, Intra-List Distance, and Entropy. Results indicate that STEAM achieves higher values for all three metrics when compared to the AgentCF baseline. Diversity Score measures the variety of items recommended, while Intra-List Distance quantifies the dissimilarity between items within a single recommendation list. Entropy, in this context, assesses the unpredictability of the recommendations, with higher values indicating greater diversity. These findings collectively demonstrate that STEAM generates recommendations that are not only relevant but also exhibit a broader range of items compared to AgentCF, suggesting improved exploration of the item catalog.
![STEAM achieves superior performance, as measured by NDCG@10, compared to both [latex]k_1[/latex] and [latex]k_2[/latex].](https://arxiv.org/html/2601.16872v1/x5.png)
Beyond Prediction: The Dawn of Truly Adaptive Intelligence
Within the STEAM framework, ‘Prototype Memories’ function as compressed representations of shared experiences, dramatically accelerating the learning process for adaptive agents. Instead of each agent independently processing raw data from interactions, these prototypes – essentially distilled lessons – are rapidly propagated throughout the network. This collaborative signal propagation allows agents to benefit from the collective knowledge of the entire system, swiftly recognizing patterns and adapting to new situations. The efficiency stems from focusing on what was learned, rather than how it was learned, allowing for generalization and transfer of knowledge without the computational burden of re-experiencing every event. Consequently, agents demonstrate enhanced responsiveness and a greater capacity to leverage the combined intelligence of the collective, fostering a truly synergistic learning environment.
The core strength of STEAM lies in its capacity for continuous refinement of user understanding. Unlike systems reliant on static datasets or pre-programmed responses, STEAM agents dynamically evolve their internal models based on ongoing interactions. This isn’t merely about tracking explicit feedback; the system subtly analyzes patterns in user behavior – dwell times, content selections, even micro-adjustments in input – to infer evolving preferences. Consequently, an agent powered by STEAM doesn’t just learn what a user likes; it anticipates changing needs and proactively adjusts its responses, offering a truly personalized and fluid experience that feels increasingly intuitive over time. This adaptive capacity moves beyond simple personalization towards a more nuanced form of collaborative intelligence, where the agent and user effectively co-evolve in a symbiotic relationship.
The advent of STEAM promises a significant leap toward genuinely user-centric technology, extending far beyond current personalization techniques. This framework doesn’t simply tailor experiences based on past behavior; it dynamically adapts to evolving preferences across diverse applications. Imagine content recommendation systems that intuitively grasp nuanced tastes, or personalized assistance that anticipates needs before they are voiced. Such capabilities aren’t limited to entertainment or convenience; STEAM’s adaptive intelligence holds potential for revolutionizing fields like education, healthcare, and accessibility, creating interfaces that respond intelligently and offer uniquely tailored support. The result is a future where technology feels less like a tool and more like a collaborative partner, fostering deeper engagement and more meaningful interactions.
Current artificial intelligence often relies on summarization – condensing information into pre-defined categories. STEAM, however, transcends this limitation by fostering agents capable of genuine adaptation. This framework doesn’t simply distill data; it allows agents to build internal models that evolve through interaction and collective experience. Instead of merely reporting what users want, STEAM enables agents to understand underlying preferences and anticipate future needs, even as those needs change. This move beyond simple summarization is crucial, because it unlocks the potential for agents that don’t just respond to commands, but proactively collaborate, learn, and offer truly personalized and intelligent assistance across diverse applications.
The pursuit of modeling user behavior, as demonstrated by STEAM’s framework of atomic memory and community construction, echoes a fundamental principle of dismantling to understand. The system isn’t accepted as a given; rather, it’s broken down into its smallest components – the ‘atomic’ memories – and then reassembled through the emergent properties of ‘communities’. This process resonates with G. H. Hardy’s assertion: “A mathematician, like a painter or a poet, is a maker of patterns.” STEAM doesn’t simply use patterns of user behavior; it actively creates them through its self-evolving memory, building and refining those patterns until the underlying structure-the ‘click of truth’-becomes apparent. The efficacy of collaborative filtering is less about predicting and more about engineering predictable patterns.
What Breaks Down From Here?
The pursuit of increasingly granular agent memory, as exemplified by STEAM, inevitably leads to a question of diminishing returns. At what point does the fidelity of atomic-level recall cease to meaningfully improve predictive power? The framework currently assumes a static definition of “atomic” – a unit of interaction. But what if the very definition of an atomic event is fluid, context-dependent, and subject to the agent’s evolving understanding of the user? To truly reverse-engineer user behavior, one must challenge the presupposition of fixed units, and allow the memory structure itself to fragment and coalesce based on observed patterns.
Furthermore, the current emphasis on community construction within the memory framework feels…comfortable. Predictably effective, perhaps. But genuine novelty rarely emerges from consensus. A more provocative line of inquiry involves actively disrupting these communities, introducing controlled ‘noise’ to force the agent to explore less probable connections. Can a recommendation system be improved by deliberately suggesting items the user is likely to reject, and then analyzing the resulting feedback? It’s a messy proposition, but the most revealing data often lies at the edge of predictability.
Ultimately, the success of any such system rests not on flawlessly replicating user behavior, but on subtly perturbing it. The true test of STEAM – and its successors – will be its ability to not just predict what a user will do, but to engineer a controlled deviation from the expected, and then to learn from the consequences. It’s a game of controlled chaos, and the rules, naturally, are meant to be broken.
Original article: https://arxiv.org/pdf/2601.16872.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-01-27 00:57