Author: Denis Avetisyan
Researchers have developed an intelligent agent that leverages the power of artificial intelligence to accelerate the discovery and design of new polymers with targeted properties.
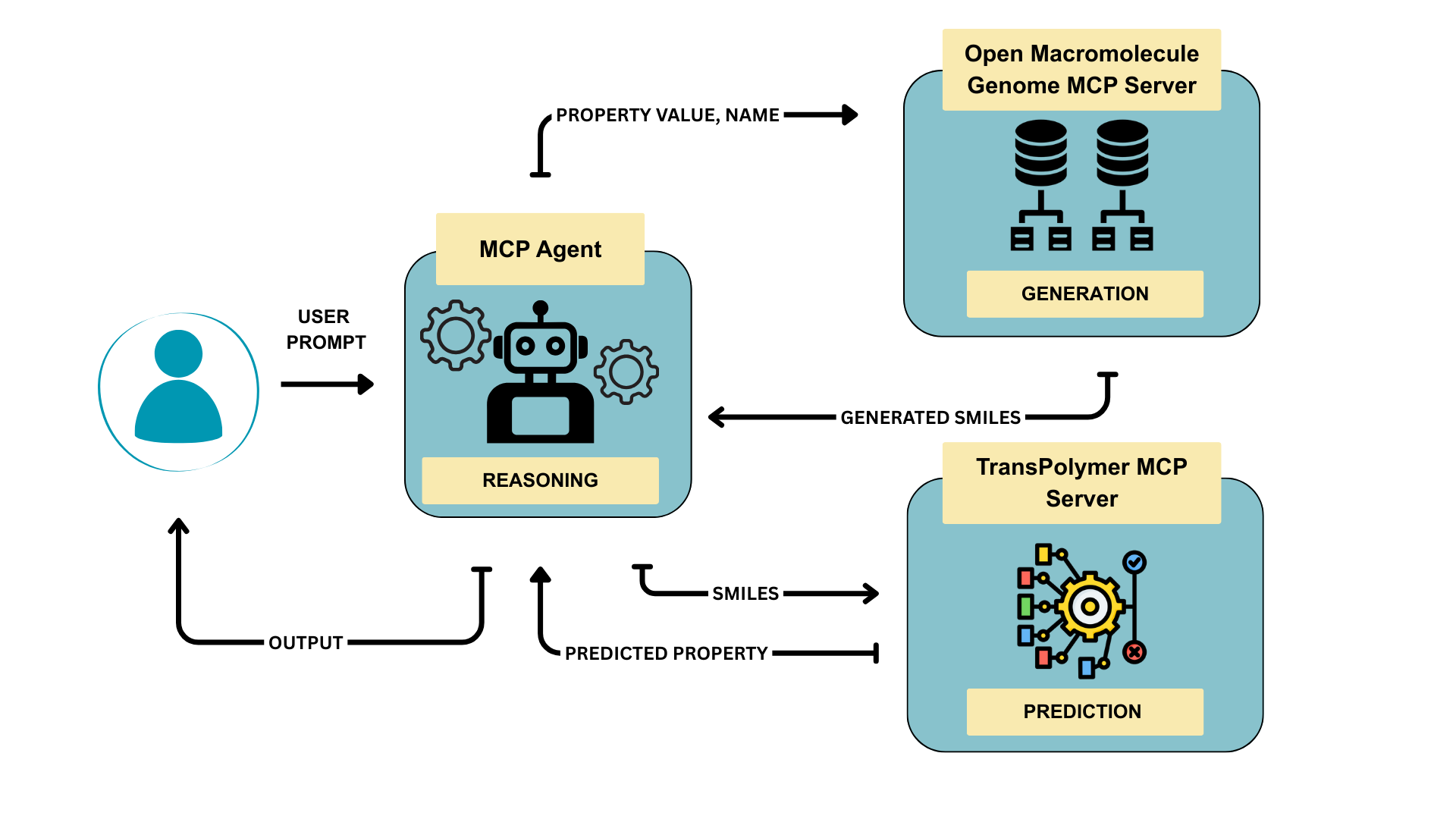
PolyAgent integrates large language models, generative models, and property prediction to automate the polymer design process.
Traditional polymer discovery relies on iterative experimentation, a process often hampered by substantial time and resource constraints. Addressing this challenge, we present ‘PolyAgent: Large Language Model Agent for Polymer Design’, a novel framework integrating large language model reasoning with generative models for automated polymer design. This agentic system enables property prediction, property-guided structure generation-prioritizing synthetic accessibility-and iterative structure modification, offering a streamlined approach to material exploration. Will this computational paradigm accelerate the discovery of next-generation polymers with tailored properties and functionalities?
The Polymer Design Bottleneck: A Challenge of Combinatorial Complexity
The development of new polymers, crucial for advancements in materials science, historically proceeds at a glacial pace and with substantial financial investment. Researchers often synthesize and test countless candidate molecules, a process driven largely by intuition and serendipity rather than predictive power. This trial-and-error methodology stems from the immense chemical space available for polymer design – variations in monomer selection, sequencing, and polymerization techniques create a combinatorial explosion of possibilities. Consequently, bringing a novel polymer from concept to practical application can take years, even decades, and require significant resources, limiting innovation and hindering the rapid response needed to address emerging technological challenges. The inherent inefficiency of this approach underscores the need for more intelligent and accelerated polymer discovery strategies.
A fundamental obstacle to accelerating polymer design lies in the difficulty of translating complex macromolecular structures into a format readily digestible by machine learning algorithms. Polymers, unlike small molecules, are characterized by their sequence, topology, and three-dimensional conformation – attributes that generate vast chemical spaces and intricate relationships between structure and properties. Traditional methods of representing polymers, such as simplified descriptors or string-based notations, often lose crucial information, limiting the predictive power of machine learning models. Furthermore, effectively capturing the nuances of polymer architectures – including branching, crosslinking, and tacticity – requires sophisticated representations that are computationally expensive and can hinder the throughput needed for high-volume screening. This challenge necessitates the development of novel encoding schemes that can accurately capture polymeric complexity while remaining amenable to efficient machine learning, ultimately unlocking the potential for rational polymer design and materials discovery.
A persistent hurdle in computational polymer design lies in the trade-off between predictive power and chemical feasibility. Many algorithms excel at forecasting polymer properties, but often propose molecules with complex, strained, or otherwise impractical structures that are exceedingly difficult-or impossible-to synthesize in a laboratory setting. Conversely, methods prioritizing synthetic accessibility frequently sacrifice accuracy, leading to predictions of materials with underwhelming or poorly defined characteristics. This limitation stems from the difficulty in effectively representing the nuanced relationship between a polymer’s molecular architecture-including tacticity, branching, and end-group functionality-and its ultimate performance. Consequently, a significant research focus centers on developing algorithms capable of navigating this complex design space, identifying molecules that are both high-performing and realistically manufacturable, thereby bridging the gap between computational prediction and tangible material innovation.

Inverse Design: A Paradigm Shift in Polymer Discovery
Inverse design in materials science utilizes machine learning algorithms to establish a relationship between a polymer’s chemical structure and its resulting physical or chemical properties. This contrasts with traditional forward prediction, where structure is determined from known properties. By training models on existing datasets of polymer structures and properties, inverse design enables the in silico screening of a vast chemical space – potentially billions of candidates – to identify polymers likely to exhibit desired characteristics. This virtual screening significantly reduces the time and resources required for materials discovery compared to experimental trial-and-error methods, accelerating the development of new materials with tailored functionalities.
Large Language Models (LLMs), architectures initially developed for natural language processing, are increasingly applied to material science due to their capacity to represent and process sequential data. Polymers can be represented using Simplified Molecular Input Line Entry System (SMILES) strings, which are text-based notations of molecular structure. LLMs, trained on extensive text corpora, can learn the patterns and relationships within SMILES strings, enabling them to predict material properties or generate novel polymer sequences. This approach bypasses the need for explicitly defined feature engineering, allowing the model to automatically extract relevant information from the structural representation. The success of this method relies on the LLM’s ability to capture the complex relationships between molecular structure and macroscopic properties solely from the SMILES notation.
Fine-tuning Large Language Models (LLMs) for inverse design involves adapting a pre-trained LLM to specific materials science datasets using parameter-efficient techniques like Low-Rank Adaptation (LoRA). LoRA freezes the pre-trained weights of the LLM and introduces trainable rank decomposition matrices, significantly reducing the number of trainable parameters. This approach mitigates the computational cost and data requirements associated with full fine-tuning, enabling effective adaptation to material databases containing polymer structures and properties. By learning the relationships within these datasets, the fine-tuned LLM enhances its ability to predict material properties from SMILES strings, leading to improved accuracy in inverse design tasks compared to the base, untrained model or models trained with fewer parameters.
Generative Models: From Prediction to De Novo Polymer Creation
Molecular Chef is a generative model specifically designed for de novo molecular design, operating by iteratively constructing molecules represented as simplified molecular-input line-entry system (SELFIES) strings. The model accepts target properties as input and generates candidate molecular structures predicted to exhibit those characteristics. A key feature of Molecular Chef is its incorporation of a “syntizability filter” which assesses the feasibility of physically synthesizing the generated molecules, thereby prioritizing structures likely to be achievable in a laboratory setting. This filter utilizes established rules and heuristics regarding chemical reactions and bond formation, ensuring the generated candidates are not merely theoretically plausible but practically realizable, addressing a common limitation of earlier generative models which often produced chemically invalid or extremely difficult-to-synthesize compounds.
Traditional SMILES (Simplified Molecular Input Line Entry System) strings, while widely used for representing molecular structures, are prone to generating syntactically invalid molecules during generative modeling processes due to their sensitivity to minor alterations. SELFIES (SELF-referencing Embedded Strings) addresses this limitation by employing a grammar designed to ensure all generated strings represent valid molecules. This is achieved through a transition from context-free to context-sensitive grammar, enabling more stable and reliable molecule generation. Specifically, SELFIES utilizes branching and recursion to represent molecular connectivity, guaranteeing that any valid SELFIES string can be unambiguously translated into a valid molecular graph, thereby improving the efficiency and success rate of de novo molecular design algorithms.
The integration of property prediction and de novo structure generation establishes a closed-loop design cycle for polymer discovery. This iterative process begins with a generative model proposing a molecular structure, which is then evaluated by a property prediction model – often a quantitative structure-property relationship (QSPR) or machine learning model – to assess its characteristics. The predicted properties are then fed back into the generative model as constraints or objectives, guiding the creation of subsequent structures with improved or targeted characteristics. This feedback loop minimizes the need for trial-and-error synthesis and testing, significantly accelerating the identification of polymers meeting specific performance criteria and reducing the overall time to discovery.

PolyAgent: An Autonomous Framework for Polymer Design
PolyAgent utilizes a Model Context Protocol to integrate Large Language Models (LLMs) with specialized external tools, establishing an agentic AI system capable of autonomous operation. This protocol facilitates communication between the LLM and tools such as polymer property predictors and materials databases, allowing the LLM to iteratively refine polymer designs based on feedback from these tools. The agentic architecture enables PolyAgent to independently formulate hypotheses, plan experiments-in this case, polymer structure modifications-execute those plans by querying external tools, and analyze the results to optimize polymer properties without requiring constant human intervention. This differs from traditional machine learning approaches by moving beyond prediction to encompass a full design cycle driven by the LLM.
Within the PolyAgent framework, property prediction is facilitated by TransPolymer, a transformer-based language model. Quantitative evaluation demonstrates high predictive accuracy for key material properties; specifically, TransPolymer achieves R² values ranging from 0.92 to 0.93 for bulk bandgap, 0.69 for electric conductivity, and 0.91 for electron affinity. These R² values indicate a strong correlation between predicted and experimentally observed values, validating the model’s capability to accurately estimate these properties during autonomous polymer design.
The PolyAgent framework automates polymer design by iteratively proposing, evaluating, and refining candidate materials, thereby enabling high-throughput exploration of the polymer chemical space. This automation circumvents the traditionally slow and labor-intensive manual process of material discovery. The system leverages the predictive capabilities of TransPolymer to estimate material properties, and uses these predictions to guide the selection of subsequent polymer designs. This iterative loop facilitates the rapid assessment of a vast number of potential polymer structures, significantly accelerating the identification of materials with desired characteristics and reducing the need for costly and time-consuming physical synthesis and testing.

Towards a Sustainable Materials Future: A Paradigm of Rational Design
The convergence of artificial intelligence and expansive materials data is rapidly reshaping the landscape of materials discovery. By leveraging accessible databases, such as the Open Macromolecule Genome – a repository of polymer characteristics – AI algorithms can systematically explore vast chemical spaces previously inaccessible to traditional methods. This computational approach dramatically accelerates the design of novel polymers with targeted properties, circumventing the costly and time-consuming trial-and-error processes of conventional materials science. The resulting efficiency not only speeds up innovation but also enables the creation of more sustainable materials by optimizing performance with minimal resource expenditure, ultimately fostering a circular economy within the polymer industry.
The traditional development of new polymers is a resource-intensive and lengthy process, often requiring significant trial-and-error experimentation. However, automated design strategies offer a pathway to drastically reduce both the time and financial investment traditionally needed. By leveraging algorithms to predict polymer properties and performance, researchers can virtually screen countless material combinations before synthesizing even a single molecule. This in silico approach minimizes wasted materials, reduces energy consumption associated with laboratory work, and accelerates the discovery of sustainable alternatives. The resulting efficiency not only lowers production costs but also facilitates the rapid iteration needed to address pressing environmental challenges, such as plastic pollution and the demand for biodegradable materials, fostering a more circular and responsible materials economy.
The generated polymers demonstrate a promising level of feasibility for actual synthesis, as evidenced by their Synthetic Accessibility (SA) scores falling between 1.094 and 7.953-a range consistently observed within the Open Macromolecule Genome (OMG) database. This indicates that the computationally designed materials aren’t merely theoretical constructs, but possess a realistic pathway to production. Further supporting their potential, comparisons to the well-established polymer Nylon-6 reveal a Tanimoto Similarity of 0.34 and a Dice Similarity of 0.5. While not identical, these similarity scores suggest shared structural characteristics and potentially analogous properties, hinting at a viable route towards creating sustainable alternatives with predictable performance based on a known material.
The presented PolyAgent framework embodies a rigorous approach to polymer design, mirroring the principles of provable correctness. The system’s integration of generative models with property prediction isn’t merely about achieving functional results; it’s about establishing a predictable relationship between molecular structure and material characteristics. This aligns with a mathematical ideal – a solution isn’t simply ‘working’ if it lacks a demonstrable foundation. As Tim Berners-Lee stated, “The Web is more a social creation than a technical one.” While PolyAgent focuses on material science, the underlying principle – creating a robust, interconnected system – resonates with the Web’s own architecture. The framework’s ability to automate exploration and refine designs isn’t just efficient; it’s elegant in its logical structure, striving for a provable path from input to desired outcome.
The Road Ahead
The introduction of PolyAgent, while a logical progression in the application of large language models, does not, of course, solve the problem of polymer design. It merely shifts the locus of difficulty. The elegance of a generative model is meaningless without a rigorously defined objective function-a mathematically pure expression of desired material properties. Currently, much reliance is placed on empirical data to ‘teach’ the model what constitutes a good polymer; this is, at best, an approximation, and at worst, a perpetuation of existing limitations. True innovation demands a departure from the merely observed.
A critical area for future work lies in the formalization of design constraints. The current approach treats properties largely as independent variables. However, the inherent interconnectedness of polymeric behavior-the trade-offs between strength, flexibility, thermal stability, and so on-requires a more holistic mathematical framework. A purely predictive model, however accurate, remains a black box. The goal should not be to find polymers that work, but to prove that a given design will satisfy specified criteria.
Ultimately, the success of such systems will not be measured by the number of novel polymers proposed, but by the certainty with which their properties can be predicted. Simplicity, in this context, does not equate to brevity of code; it signifies non-contradiction and logical completeness. Until the underlying principles of material behavior are expressed with mathematical rigor, PolyAgent – and all similar systems – will remain sophisticated tools for exploration, rather than engines of true discovery.
Original article: https://arxiv.org/pdf/2601.16376.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-01-26 21:26