Author: Denis Avetisyan
A new approach proposes uniquely identifying algorithms using established digital identifiers to bolster accountability and transparency in increasingly complex AI systems.
This review explores the use of Digital Object Identifiers (DOIs) and associated metadata to enable reliable algorithm identification, auditability, and improved AI governance.
Despite the increasing reliance on algorithms across critical domains, establishing clear accountability and transparency remains a significant challenge. This paper, ‘Algorithmic Identity Based on Metaparameters: A Path to Reliability, Auditability, and Traceability’, proposes a solution by leveraging Digital Object Identifiers (DOIs) to uniquely identify algorithms and link them to essential metadata. This approach facilitates tracking, auditing, and responsible governance, particularly for increasingly complex AI agents and large language models. Could widespread adoption of DOI-based algorithmic identification become a cornerstone of trustworthy AI development and deployment?
The Looming Challenge of Algorithmic Accountability
The rapid integration of artificial intelligence into daily life-from automated decision-making in loan applications to content curation on social media-introduces a significant accountability challenge. As AI systems increasingly influence critical aspects of human experience, determining responsibility when these systems err, produce biased outcomes, or cause harm becomes paramount. Unlike traditional software, the complex and often opaque nature of AI-particularly machine learning models-makes tracing the origins of a decision difficult. Establishing who is accountable-the developer, the deployer, or the AI itself-requires a fundamental shift in how responsibility is assigned in the digital age. This isn’t simply a legal or ethical concern; a lack of clear accountability erodes public trust and hinders the widespread adoption of beneficial AI technologies, potentially stifling innovation and exacerbating existing societal inequalities.
Existing methods for identifying algorithms frequently fall short when faced with the intricacies of modern artificial intelligence. These systems often rely on superficial characteristics – a model’s name, or the library it’s built upon – which are easily altered or circumvented, providing a fleeting and unreliable record. Crucially, they lack the ability to track the numerous revisions and fine-tunings that occur during a model’s lifecycle, meaning a specific instance responsible for a particular outcome can be difficult, if not impossible, to pinpoint. This creates a significant challenge for auditing, debugging, and establishing accountability, as the precise lineage and configuration of a deployed algorithm remain obscured. Consequently, tracing errors, addressing biases, or even confirming compliance with regulatory standards becomes substantially more complex, hindering responsible innovation and fostering distrust in AI systems.
The lack of transparency in algorithmic decision-making erodes public confidence and poses significant risks across multiple sectors. When the reasoning behind an AI’s output remains obscured, it becomes difficult to assess fairness, identify biases, or even understand why a particular outcome occurred, fostering distrust and potentially damaging reputations. This opacity also creates substantial hurdles for regulatory bodies striving to ensure compliance with emerging AI governance standards, as demonstrating accountability requires tracing decisions back to the underlying model and data. Crucially, this lack of clarity opens avenues for malicious actors to exploit vulnerabilities; adversarial attacks can be disguised within complex algorithms, and manipulated outputs can be difficult to detect without a clear understanding of the system’s internal logic, potentially leading to financial losses, reputational damage, or even physical harm.
A foundational step towards trustworthy artificial intelligence lies in the development of robust algorithm identification systems. Currently, tracking the lineage and modifications of complex AI models proves remarkably difficult, creating a significant obstacle to responsible innovation. Without a clear and persistent method for identifying algorithms – encompassing their creators, training data, and iterative revisions – establishing accountability becomes virtually impossible. This lack of transparency not only erodes public trust and complicates regulatory oversight, but also leaves systems vulnerable to manipulation and malicious use. Consequently, prioritizing the creation of such identification systems is not merely a technical challenge, but a crucial prerequisite for fostering a future where AI benefits society with both power and predictability.
A Standardized Taxonomy for Algorithm Identification
A hierarchical taxonomy for algorithm identification is proposed, utilizing the Digital Object Identifier (DOI) system as its foundational element. This system assigns a unique, persistent identifier to each distinct component of an algorithm’s definition and implementation. The taxonomy is structured to encompass not only the algorithm itself, but also its concrete realizations, and is intended to provide a standardized method for referencing and tracking algorithms throughout their lifecycle. By leveraging DOIs, the taxonomy facilitates unambiguous identification and version control, enabling precise attribution and reproducibility of algorithmic work. The use of DOIs ensures that each algorithmic component can be reliably located and cited, even as it evolves over time.
The proposed taxonomy categorizes algorithms across three distinct levels to comprehensively define their lifecycle. Algorithmic Logic represents the abstract, mathematical or conceptual definition of the algorithm, independent of any specific implementation. The Reference Implementation level consists of concrete source code realizing that logic, providing a functional, executable form. Finally, Trained Models are the artifacts resulting from applying the reference implementation to data, representing the algorithm’s learned parameters and operational state. This tiered structure allows for granular identification and tracking of each component throughout the algorithm’s development and deployment.
The assignment of a unique Digital Object Identifier (DOI) to each level – Algorithmic Logic, Reference Implementation, and Trained Models – provides a persistent and actionable identifier for tracking modifications throughout an algorithm’s lifecycle. This DOI system allows for granular version control, as each revision at any level receives a new, resolvable DOI. Consequently, specific algorithmic concepts, source code versions, or trained model states can be unambiguously referenced and retrieved. Furthermore, the DOI infrastructure supports metadata recording, documenting the provenance of changes, author information, and associated datasets, thereby ensuring reproducibility and facilitating auditing of algorithmic processes. The use of DOIs moves beyond simple snapshotting of model weights to a complete record of the algorithm’s development.
Traditional model versioning systems primarily track changes to trained parameters, neglecting the underlying algorithmic logic and its implementations. This taxonomy, however, establishes a comprehensive lineage by assigning unique DOIs to each stage of an algorithm’s lifecycle – from the abstract algorithmic logic itself, through specific reference implementations in source code, to the resulting trained models. This allows for precise tracking of dependencies and modifications across all components, facilitating reproducibility, auditing, and the ability to revert to specific states of the algorithm at any point in its development. Consequently, researchers and developers can pinpoint the exact code and data used to generate a particular model, and understand how changes at any level propagate through the entire system.
Establishing Trust: Metadata for Provenance and Auditing
The system utilizes comprehensive metadata to establish provenance and facilitate auditing of algorithms. This metadata includes direct links to the datasets used for training, allowing for reproducibility and bias assessment. Furthermore, access to associated Ethical Alignment Reports documents the considerations made regarding potential societal impacts and mitigation strategies. Crucially, each algorithm is linked to a Software Heritage ID (SWHID), a unique identifier referencing the complete software development history – including source code, commits, and authorship – archived at Software Heritage. This combination of data, ethical documentation, and software lineage provides a verifiable record of the algorithm’s creation and evolution.
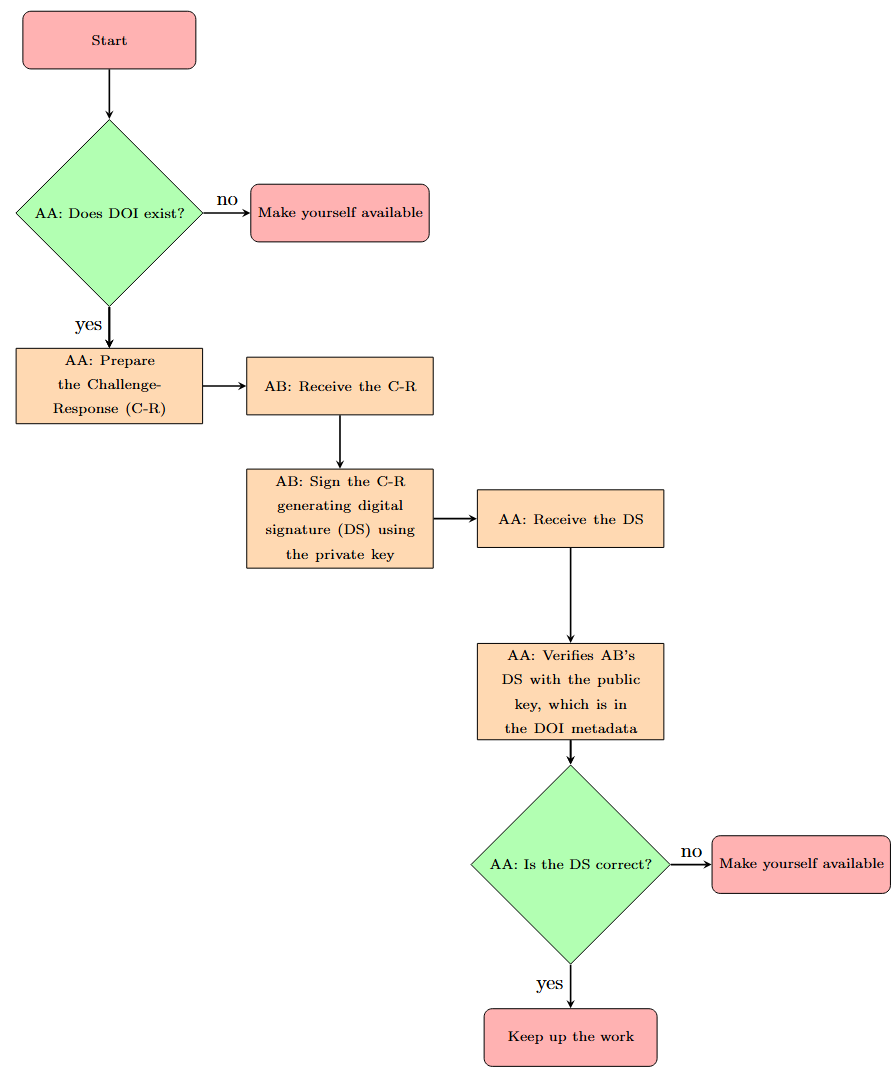
The system employs an authentication protocol leveraging the Digital Object Identifier (DOI) infrastructure to establish and verify the authenticity of algorithms. Each algorithm is assigned a unique, persistent DOI, functioning as a cryptographic anchor. This DOI is linked to a digitally signed hash of the algorithm’s code and associated data, allowing for verification of integrity. Any modification to the algorithm, however minor, will result in a different hash value and thus fail authentication against the original DOI. This process effectively prevents malicious manipulation by ensuring that any unauthorized changes are detectable and invalidate the algorithm’s established identity, providing a tamper-evident record.
Semantic Versioning (SemVer) is implemented to manage algorithm updates efficiently without necessitating the assignment of new Digital Object Identifiers (DOIs) for each incremental change. This approach utilizes a three-part version number – MAJOR.MINOR.PATCH – where MAJOR version changes indicate incompatible API changes, MINOR versions denote functionality added in a backwards-compatible manner, and PATCH versions represent backwards-compatible bug fixes. By adhering to SemVer principles, the system allows for precise tracking of modifications while maintaining a persistent, verifiable link to the algorithm’s core identity via the DOI, thus streamlining version control and reducing administrative overhead compared to assigning a new DOI for every update.
Citizen Explainability provides a concise, non-technical description of an algorithm’s intended function and potential societal impact, designed for public consumption. This summary, distinct from technical documentation, aims to foster understanding among stakeholders lacking specialized expertise in machine learning or data science. The content focuses on the algorithm’s purpose, the data it utilizes, the decisions it influences, and potential biases or limitations. By providing accessible information, Citizen Explainability supports public accountability and enables informed discussion regarding the deployment and governance of algorithmic systems, addressing concerns about transparency and fairness.
Mitigating Risks and Enabling Responsible AI Deployment
The proliferation of machine learning models introduces vulnerabilities, notably ‘model washing’ – where a model is superficially altered to evade detection or accountability. To counter this, a robust system for uniquely identifying and tracking algorithms is crucial. This involves assigning a persistent, verifiable identifier to each model, similar to a Digital Object Identifier (DOI), allowing its lineage and modifications to be traced throughout its lifecycle. Such tracking isn’t merely about detection; it establishes a verifiable record of a model’s development, training data, and performance characteristics. This capability is particularly important in distributed models, where components might be developed and deployed by different entities, demanding a transparent and auditable chain of custody to ensure ongoing integrity and prevent malicious substitution or manipulation. Effectively, this approach moves beyond simply having algorithms to knowing them, bolstering trust and responsible deployment in increasingly complex AI ecosystems.
A persistent and verifiable audit trail is now achievable through the implementation of a Digital Object Identifier (DOI)-based system for algorithms. This framework assigns a unique and permanent identifier to each algorithm, recording its evolution, training data, and performance metrics over time. Consequently, investigations into potential algorithmic bias and unfair outcomes become significantly more robust; researchers and regulators can trace the lineage of a decision-making process, pinpoint sources of discriminatory behavior, and assess accountability. The DOI system doesn’t merely flag problematic outputs, but actively enables a forensic analysis of how those outcomes arose, fostering a pathway towards algorithmic correction and promoting equitable AI systems. This level of transparency is critical for building public trust and ensuring responsible deployment of increasingly powerful technologies.
A robust system of algorithmic accountability hinges on a principle of Qualified Transparency – a carefully calibrated approach to revealing an algorithm’s inner workings without compromising intellectual property or security. This framework doesn’t demand complete exposure of source code, but instead focuses on providing stakeholders – from developers and regulators to affected individuals – with accessible information regarding the algorithm’s design choices, training data, and potential biases. By detailing the key parameters influencing decision-making and offering explanations for specific outcomes, Qualified Transparency empowers meaningful scrutiny and facilitates the identification of unintended consequences. This level of insight moves beyond a ‘black box’ approach, fostering trust and allowing for informed assessments of an algorithm’s impact on individuals and society, ultimately enabling responsible innovation and deployment.
The pursuit of responsible artificial intelligence hinges on bridging the gap between potent algorithmic capabilities and public understanding. This framework directly addresses that need by establishing a pathway toward democratic explainability – a system where the logic and potential impacts of algorithms are accessible for scrutiny. By empowering stakeholders with insight into how these systems function, and by providing mechanisms to audit their behavior, it fosters accountability and builds confidence. This isn’t merely about transparency for transparency’s sake, but about aligning technological power with societal values, ultimately encouraging public trust and enabling the continued, beneficial development of AI technologies. The result is a shift from opaque ‘black boxes’ to systems that are understood, questioned, and demonstrably aligned with principles of fairness and equity.
Towards a Future of Accountable Algorithms
Assigning Digital Object Identifiers (DOIs) to Application Programming Interfaces (APIs) establishes a crucial system of version control and accountability for these increasingly vital technological interfaces. This approach treats APIs not as ephemeral software components, but as persistent, citable entities, much like research datasets or scholarly articles. Each modification to an API – whether a bug fix, feature addition, or fundamental architectural change – receives a new DOI, creating an immutable record of its evolution. Consequently, developers can reliably reference specific API versions, ensuring reproducibility and facilitating audits when issues arise. This is particularly important in critical applications – such as those governing financial transactions, healthcare systems, or autonomous vehicles – where precise tracking of algorithmic behavior is paramount and responsibility for outcomes must be clearly established. By anchoring APIs to a persistent identifier, the system moves beyond simply having algorithms to knowing which algorithm was used, when, and why.
The increasing prevalence of autonomous agents – from self-driving vehicles to algorithmic trading systems – necessitates robust identification mechanisms, not simply for tracking their actions, but crucially, for attributing responsibility when unpredictable behaviors occur. Current systems often lack the granularity to pinpoint the precise origin of an error or unintended consequence within a complex AI, hindering effective oversight and remediation. Establishing a persistent, verifiable identity for each agent, linked to its development lineage, training data, and operational parameters, becomes paramount. This allows for detailed forensic analysis following incidents, enabling developers and regulators to understand how an agent arrived at a particular decision and to assign accountability appropriately. Such a system moves beyond simply detecting anomalous behavior to proactively managing risk and fostering trust in increasingly autonomous systems, paving the way for safe and ethical deployment at scale.
A core challenge in tracking and governing autonomous systems lies in the rapid evolution of artificial intelligence itself. Recognizing this, researchers have developed a taxonomy – a hierarchical classification system – designed not as a rigid definition, but as a flexible framework. This system moves beyond simply categorizing current AI architectures; it is built to accommodate novel approaches and unforeseen technological advancements. By prioritizing adaptability, the taxonomy facilitates consistent identification and accountability even as AI models become more complex and diverge from existing paradigms. The framework’s modular design allows for the seamless integration of new classifications, ensuring that tracking mechanisms remain relevant and effective throughout the continuing development of increasingly sophisticated autonomous agents and their underlying technologies.
The development of robust algorithmic identification and tracking systems represents more than simply solving a technical challenge; it signifies a crucial advancement toward establishing a future defined by responsible artificial intelligence. By creating mechanisms for attributing actions and decisions to specific algorithmic versions – and ultimately, their creators – these systems lay the groundwork for genuine algorithmic accountability. This isn’t about assigning blame, but about fostering transparency, enabling effective oversight, and ensuring that increasingly complex AI systems operate in alignment with established ethical guidelines and human values. Ultimately, the ability to trace an algorithm’s lineage and behavior is paramount to building public trust and realizing the full, beneficial potential of artificial intelligence across all facets of life.
The pursuit of algorithmic identity, as detailed in this work, echoes a fundamental principle of systemic understanding. Just as a complex system’s behavior stems from its underlying structure, so too must algorithms be understood through traceable metadata and unique identifiers. Carl Friedrich Gauss observed, “If other people would think differently about things, then the world would be a better place.” This sentiment applies directly to the need for qualified transparency in AI; by uniquely identifying algorithms with DOIs and associated ‘model cards’, the system gains clarity, enabling better evaluation and accountability. The work establishes a pathway toward ensuring that each algorithmic component is not treated as an isolated entity, but as an integral part of a larger, comprehensible whole.
What Lies Ahead?
The assignment of persistent identifiers, such as DOIs, to algorithms represents a necessary, if belated, acknowledgement of their increasing agency. However, the simplicity of this act belies a considerable challenge: scalability. A DOI is merely a handle; the true value resides in the richness and reliability of the metadata it unlocks. The current focus on ‘Model Cards’ is a promising start, but risks becoming a fragmented taxonomy, a digital equivalent of Linnaean botany applied to a protean, evolving system. The ecosystem demands interoperability, not isolated gardens.
A crucial, often overlooked, limitation stems from the very nature of algorithms. They are not static entities. They learn, adapt, and drift. A DOI assigned at one moment may describe an algorithm that no longer exists in a subsequent state. This raises complex questions of versioning, provenance, and accountability. The challenge isn’t simply identifying an algorithm, but tracing its lineage and understanding its present configuration. The structure, inevitably, dictates the behavior.
Future work must move beyond descriptive metadata toward verifiable computational reproducibility. Ideally, a DOI should unlock not just what an algorithm does, but how it does it, allowing for independent validation and audit. The pursuit of ‘Qualified Transparency’ will require a shift in thinking – from documenting algorithms as they are to documenting the processes by which they become what they are. The clarity of such a system will not be found in increased server power, but in the elegance of its design.
Original article: https://arxiv.org/pdf/2601.16234.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-01-26 18:12