Author: Denis Avetisyan
A new wave of AI-powered search is challenging the dominance of traditional web search, prompting a critical look at how we find and consume information online.
This review compares the information retrieval strategies of generative AI models and conventional search engines, analyzing differences in source diversity, content freshness, and the impact of pre-training bias.
Traditional information retrieval has long relied on web search, yet the emergence of generative AI presents a fundamental challenge to this established paradigm. This paper, ‘Navigating the Shift: A Comparative Analysis of Web Search and Generative AI Response Generation’, undertakes a large-scale empirical study revealing significant divergences between Google Search and leading generative AI services in source utilization, content freshness, and the influence of pre-training data. Our analysis demonstrates that AI engines prioritize distinct information ecosystems and leverage inherent knowledge bases in ways that differ substantially from traditional search algorithms. Consequently, these findings raise critical questions about the future of information access and the development of effective strategies for Answer Engine Optimization in this rapidly evolving landscape.
The Shifting Sands of Information Access
For decades, information retrieval largely functioned on a principle of directed discovery. Traditional search engines, like Google Search, respond to user queries not with direct answers, but with ranked lists of potentially relevant sources. This approach necessitates considerable cognitive effort on the part of the user, who must then navigate these lists, evaluate the credibility of each source, and synthesize the information independently to formulate a comprehensive understanding. While effective, this process is inherently time-consuming and demands a degree of information literacy not universally possessed. The user acts as the primary integrator of knowledge, a substantial burden when seeking quick or complex answers, and a significant contrast to emerging methods that aim to directly deliver synthesized insights.
The conventional model of information retrieval, reliant on presenting users with lists of potentially relevant sources, is increasingly challenged by generative AI services that directly synthesize answers. This represents a fundamental shift in how information is accessed, promising a significantly more efficient experience by eliminating the need for users to manually sift through multiple documents. Rather than providing a curated compilation, these AI models aim to provide a concise, direct response to a query, effectively performing the synthesis and summarization process on behalf of the user. This capability is poised to redefine user expectations, moving the focus from locating information to receiving readily digestible knowledge, and potentially altering the very nature of search itself.
The evolution of search is strikingly apparent when examining ranking queries – those requests for ordered lists like “best running shoes” or “top-rated Italian restaurants.” While traditional search engines respond by compiling links to numerous sources, requiring users to synthesize the answer themselves, generative AI models attempt direct synthesis. However, a recent analysis reveals these approaches differ fundamentally in how they build those responses. Unlike search engines which primarily draw from a relatively concentrated set of high-ranking websites, AI models demonstrate markedly divergent sourcing patterns, actively incorporating information from a far broader, and often less-conventional, range of sources. This suggests a fundamental shift not just in presentation, but in the very methodology of information retrieval, potentially exposing users to a wider, though not necessarily more authoritative, spectrum of perspectives.
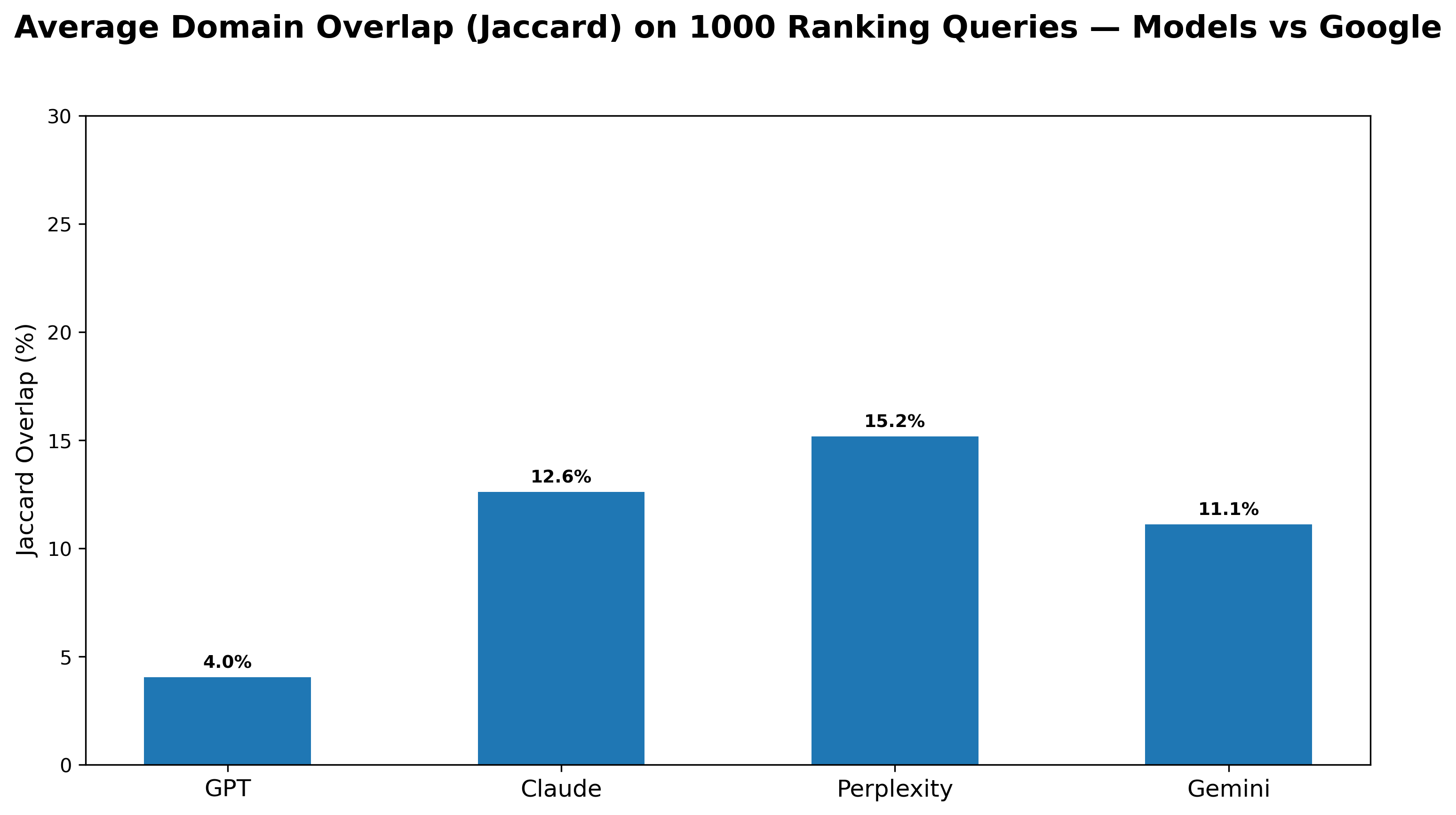
Analysis reveals a striking divergence in how GPT-4o and Google Search arrive at information, with the generative AI exhibiting remarkably little overlap – just 4.0% – with the domains typically surfaced by the traditional search engine. This suggests GPT-4o isn’t simply repackaging existing web content, but instead synthesizes answers from a distinctly different set of sources, potentially drawing upon a broader, less-indexed portion of the internet, or prioritizing different types of information altogether. While Google Search prioritizes established websites and high-ranking pages, GPT-4o appears to explore a more diverse range of resources, indicating a fundamental shift in information sourcing strategies and raising questions about the future of search and knowledge discovery.
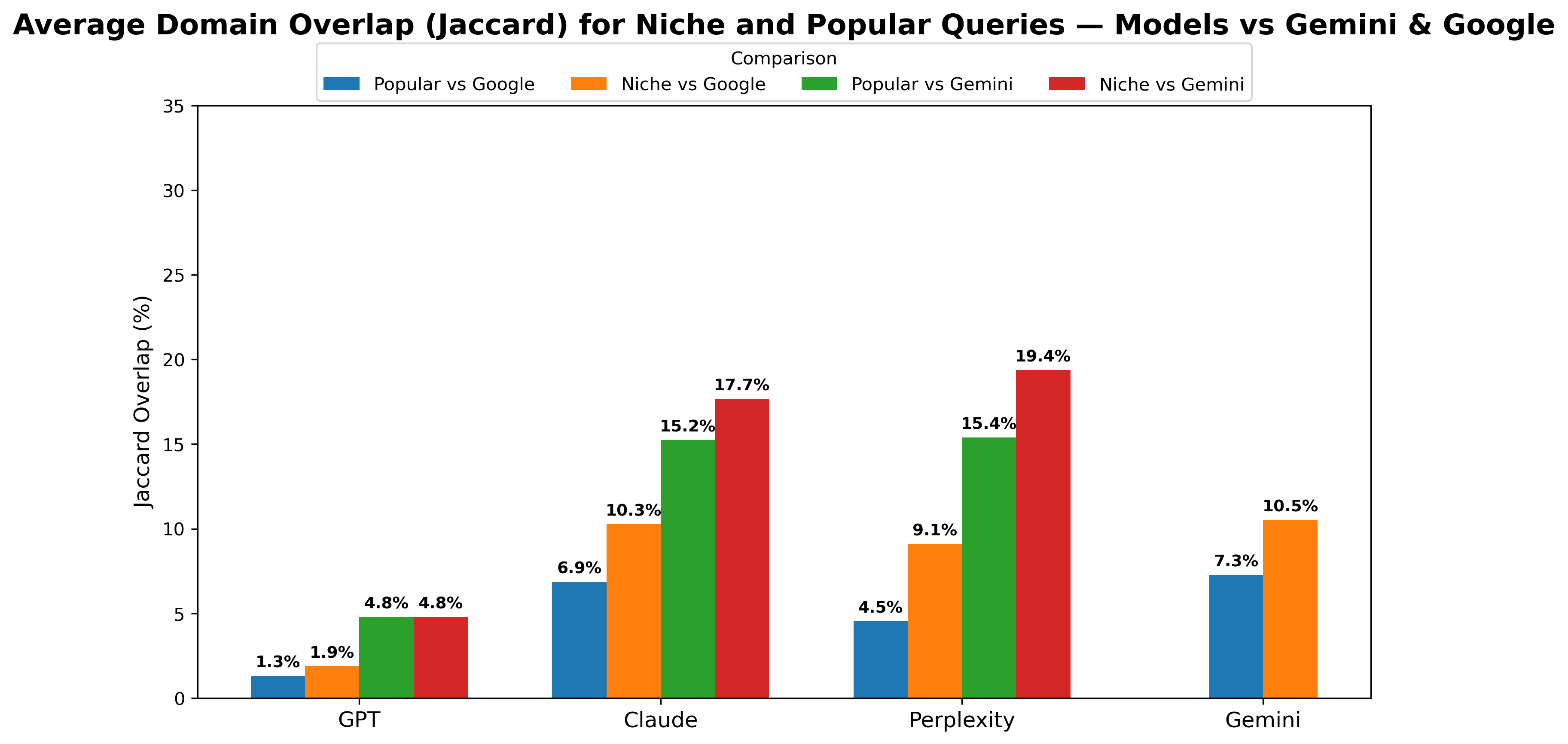
The Fragility of Relevance: Assessing AI Synthesis
Generative AI services commonly assess the relevance of retrieved content snippets to formulate responses; however, this process exhibits vulnerabilities, particularly when sources demonstrate significant domain overlap. When multiple documents address the same topics, the AI may struggle to differentiate between genuinely relevant and superficially similar content. This is because relevance scoring often relies on keyword matching and statistical correlations, which can be misleading when sources are highly redundant. The resulting ranking of snippets may not accurately reflect the information most pertinent to the user’s query, leading to inaccurate or unhelpful generated outputs. Consequently, evaluation methodologies must account for this susceptibility to domain overlap to provide a realistic assessment of service performance.
Snippet Shuffle is a perturbation technique used to assess the ranking stability of generative AI systems. This method involves randomly reordering the input snippets provided to the model and observing the resulting changes in the generated ranking of responses. A stable ranking indicates the model is prioritizing content based on inherent relevance, not simply positional bias within the input. Significant fluctuations in ranking after shuffling suggest the model is overly sensitive to snippet order and may not be accurately evaluating content relevance, potentially leading to unreliable or inconsistent outputs. The degree of ranking change after multiple shuffles is quantified to provide a metric for evaluating the robustness of the ranking algorithm.
Entity-Swap Injection (ESI) is an evaluation technique designed to assess a generative AI service’s ability to understand context and relationships within retrieved content. The method involves systematically replacing entities – such as names, locations, or organizations – within the source snippets with other, semantically similar entities. A robust system should recognize these substitutions and adjust its response accordingly, indicating true comprehension rather than reliance on keyword matching. Significant changes in generated output following entity swaps suggest a deficiency in contextual understanding, while minimal variation implies the system correctly maintains meaning despite the alterations. This provides a more nuanced evaluation than simple relevance scoring, as it directly tests the model’s ability to reason about the information presented.
Evaluation of retrieval-augmented generation systems using perturbation techniques has revealed substantial discrepancies in the freshness of source material utilized by different models. Specifically, analysis of Consumer Electronics queries indicates that Claude relies on articles with a median age of 62 days, suggesting a preference for more recent information. In contrast, Google demonstrates a significantly older median article age of 493 days for the same query type, indicating a greater reliance on established, potentially dated, content. This difference in content freshness impacts ranking stability and highlights a key distinction in how these services approach information retrieval and synthesis.
Anchoring Responses: Grounding and the Pursuit of Reliable Ranking
Strict grounding is a critical technique employed in retrieval-augmented generation (RAG) systems to mitigate the issue of hallucination in large language models (LLMs). This methodology constrains the generative model to base its responses exclusively on the content of the retrieved source documents, or snippets. By limiting the model’s knowledge scope to the provided context, strict grounding prevents the generation of information not explicitly supported by the evidence, thereby enhancing the factual accuracy and reliability of the output. Implementation typically involves mechanisms that explicitly mask or penalize the generation of tokens not traceable to the retrieved snippets, ensuring responses are firmly rooted in the provided evidence and reducing the risk of fabricated or unsupported claims.
Pairwise comparison is a ranking methodology where a generative model evaluates two entities in response to a specific query and directly selects the preferred option. This approach bypasses the need to assign absolute scores to each entity; instead, the model focuses on relative preference. By repeatedly comparing pairs of entities for a given query, a complete ranking can be constructed. The robustness of this method stems from its focus on discerning the better option within a limited scope, reducing the potential for errors associated with absolute value estimations and promoting a more reliable ordering of results.
Kendall’s Tau is a non-parametric statistical measure used to assess the ordinal association between two rankings; in this context, it quantifies the correlation between a model’s ranked list of entities and a ground truth or expert-provided ranking. Values range from -1 to 1, with 1 indicating perfect agreement, 0 indicating no association, and -1 indicating perfect disagreement. Evaluation using Kendall’s Tau reveals that for frequently queried, or “popular” entities, the ranking produced via Pairwise Comparison exhibits a very high degree of consistency – approaching a Tau of 1 – when compared to established ranking methodologies or human judgment. This indicates a strong reliability in ranking well-known entities using this approach.
Evaluation of ranking consistency using Kendall’s Tau demonstrates a reduction in correlation when applied to niche entities compared to popular entities. This indicates that while ranking methods perform reliably for widely known subjects with abundant data, maintaining the same level of accuracy and agreement with ground truth or expert judgment becomes more difficult with less frequently queried or obscure topics. This decreased consistency suggests a challenge in generalizing ranking reliability across the entire spectrum of possible queries, particularly those concerning specialized or infrequently discussed entities.
The Long Tail of Knowledge: Addressing Niche Entities and Ephemeral Truths
Generative AI systems, despite their impressive capabilities, frequently encounter difficulties when processing niche entities – specialized concepts or obscure references lacking widespread representation in their training datasets. This limitation stems from the reliance on massive pre-training corpora; if a topic isn’t extensively covered in these datasets, the AI struggles to accurately determine its relevance or contextual significance. Consequently, responses involving specialized terminology, less-known figures, or highly specific events can be inaccurate, nonsensical, or entirely miss the mark. The system may misinterpret the entity, fail to recognize its importance, or generate responses that lack the necessary nuance and precision, highlighting a critical challenge in building truly knowledgeable and reliable artificial intelligence.
The reliability of generative AI hinges significantly on accessing and utilizing current information; outdated data quickly compromises accuracy, especially within dynamic fields like technology, science, and current events. Recent analysis reveals that while models such as Gemini, Claude, and Perplexity increasingly draw from sources overlapping with Google Search – showing domain overlap of 11.1%, 12.6%, and 15.2% respectively – each still exhibits distinct preferences in source prioritization. This divergence underscores the critical need for continuous knowledge updates and refined retrieval mechanisms, as relying solely on pre-existing training data leaves these systems vulnerable to propagating stale or incorrect information and ultimately erodes user trust.
Building generative search experiences that users can truly rely on demands a multifaceted strategy. Simply possessing vast datasets isn’t enough; the system must be strictly grounded in verifiable sources to avoid fabrication or misrepresentation. Robust evaluation techniques are then critical, going beyond simple accuracy checks to assess the nuance and contextual relevance of responses. Crucially, this process isn’t static; a commitment to comprehensive and current information is essential, as knowledge evolves rapidly across many domains. By prioritizing these elements – grounding, evaluation, and freshness – developers can move beyond impressive demonstrations toward genuinely trustworthy tools that deliver insightful and reliable answers.
The study of generative AI’s divergence from traditional web search illuminates a predictable trajectory – systems evolving, and inevitably, decaying from their initial state. The research highlights how these AI engines, while appearing novel, fundamentally lean on pre-existing knowledge, demonstrating a prioritization of learned patterns over dynamic source freshness. This reliance echoes a natural system step toward maturity, where initial exploration gives way to consolidation. As Carl Friedrich Gauss observed, “If I have seen further it is by standing on the shoulders of giants.” Generative AI, in its current form, stands firmly on the shoulders of its pre-training data, acknowledging the inherent debt to established knowledge – a debt that shapes its responses and defines its limitations, much like any system undergoing the stresses of time and use.
What’s Next?
The observed divergence between retrieval-based web search and generative AI response generation isn’t a disruption, but a re-calibration. Traditional search, predicated on indexing the ever-shifting present, now confronts a system that actively synthesizes a past-a past inherently weighted by the biases and limitations of its pre-training. This isn’t a failure of the new architecture, but a predictable consequence of building intelligence upon a foundation of finite data. Every abstraction carries the weight of the past, and the challenge isn’t to eliminate that weight, but to understand its distribution.
Future work must move beyond simply measuring differences in source diversity or content freshness. More nuanced analyses are needed to quantify the ‘staleness’ of knowledge within these systems-to determine not just if information is old, but how it decays within the generative process. The emphasis should shift from chasing the new, to assessing the resilience of established knowledge against the entropy of time.
Ultimately, the longevity of either approach hinges not on technological novelty, but on adaptability. Slow change preserves resilience. A system capable of gracefully accommodating outdated information-of acknowledging its own limitations-will fare better than one perpetually striving for an impossible present. The question isn’t whether generative AI will surpass traditional search, but which system will age more gracefully.
Original article: https://arxiv.org/pdf/2601.16858.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- Gold Rate Forecast
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- We talked to ‘Bachelorette’ Taylor Frankie Paul. Then reality hit pause on her TV career
- Roco Kingdom: World China beta turns chaotic for unexpected semi-nudity as players run around undressed
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
2026-01-26 16:25