Author: Denis Avetisyan
A new approach harnesses the power of foundation models to discover database optimization strategies previously unseen by human experts.
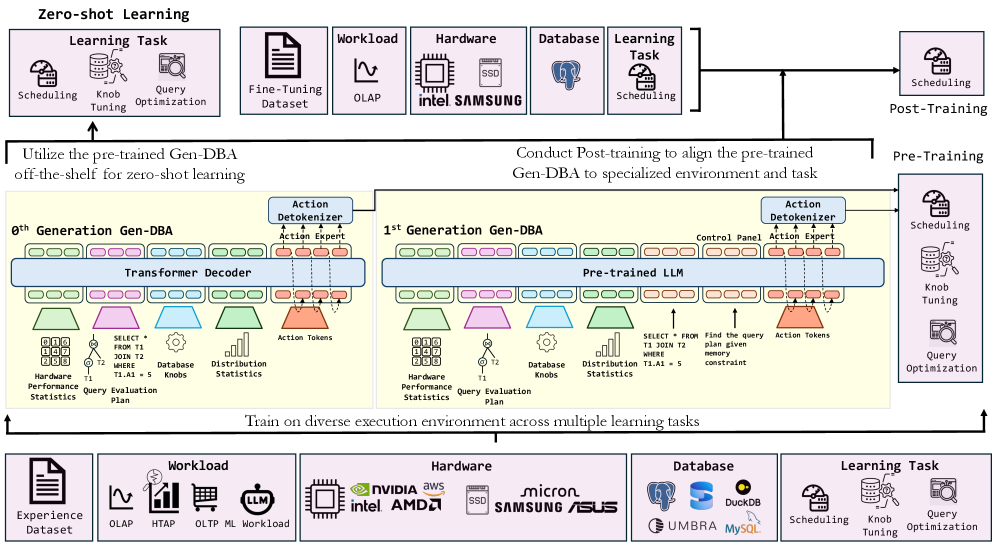
This paper introduces Generative Database Agents (Gen-DBA), a unified learning framework leveraging next token prediction with DB-Tokens to achieve a ‘Move 37’ moment in database systems.
Despite recent advances in Artificial Intelligence, database systems have yet to experience a breakthrough comparable to the paradigm shifts seen in fields like game playing and natural language processing. This paper, ‘Gen-DBA: Generative Database Agents (Towards a Move 37 for Databases)’, proposes a path towards such a ‘Move 37’ moment through Generative Database Agents (Gen-DBAs)-a novel approach leveraging foundation models and a unified learning framework. We envision Gen-DBAs as systems capable of discovering data optimization strategies beyond current human intuition, built upon a Transformer backbone, hardware-grounded tokenization, and a goal-directed next token prediction paradigm. Could this generative approach unlock a new era of autonomous and highly efficient database management?
The Inevitable Decay of Conventional Systems
Conventional database systems, while foundational to modern data management, increasingly falter when faced with the demands of contemporary workloads. These systems, often reliant on pre-defined rules and human expertise, struggle to efficiently handle the volume, velocity, and variety characteristic of today’s data landscape. Consequently, database administrators are frequently tasked with painstaking manual tuning – a reactive process of identifying bottlenecks and adjusting configurations – to maintain acceptable performance. This reliance on human intervention is not only labor-intensive and costly, but also inherently limited by the administrator’s ability to anticipate and address every potential optimization opportunity, creating a significant impediment to fully realizing the potential of rapidly growing datasets and complex analytical queries.
The escalating demands of modern data workloads have exposed critical limitations in traditional database systems, prompting the emergence of AI4DB – Artificial Intelligence for Databases. This innovative field directly addresses these challenges by integrating machine learning techniques to automate and enhance database optimization and management. Rather than relying on manual tuning and pre-defined rules, AI4DB employs algorithms to dynamically analyze database performance, predict bottlenecks, and autonomously adjust configurations for improved efficiency. This includes tasks like query optimization, index selection, resource allocation, and even automated schema design, ultimately aiming to deliver self-tuning and self-managing database systems capable of handling increasingly complex data environments with minimal human intervention.
The emergence of AI4DB isn’t simply about applying machine learning to databases, but rather adopting a fundamentally different approach to database management, mirroring the inventive strategies demonstrated by systems like AlphaGo. AlphaGo’s famed ‘Move 37’, a move defying conventional Go strategy yet proving remarkably effective, exemplifies this shift – a willingness to explore solutions beyond established rules. Similarly, AI4DB research actively pursues database optimizations that might not be discovered through traditional, human-defined tuning methods. This means algorithms are designed to learn and propose solutions that break from conventional wisdom, potentially unlocking significant performance gains and enabling databases to adapt to unforeseen workloads and data characteristics with a level of ingenuity previously unattainable.
The future of database management hinges on the development of autonomous agents, systems capable of independent learning and adaptation without constant human intervention. These agents move beyond pre-programmed responses, instead employing machine learning to analyze workload patterns, predict future needs, and proactively optimize database performance. This necessitates a shift from reactive tuning – addressing problems as they arise – to a predictive and self-regulating system. Such agents will not merely execute commands but will actively explore the solution space, discovering novel optimization strategies previously unforeseen by human experts, ultimately leading to databases that are not just efficient, but truly self-managing and resilient in the face of evolving demands.
The Genesis of a Self-Evolving System
Gen-DBA represents a new approach to database management by consolidating disparate learning tasks – including query optimization, index selection, and schema design – into a unified generative model. Prior methods typically require task-specific training and architectures; Gen-DBA aims to address these limitations by providing a single framework capable of handling a broad range of database operations. This is achieved through a generative process where the model learns to produce actions and configurations that optimize database performance across multiple learning objectives, eliminating the need for separate models trained for each individual task. The intention is to improve adaptability and reduce the complexity associated with managing and optimizing database systems.
Gen-DBA utilizes Large Language Models (LLMs) to interpret and execute database operations by treating database interactions as a sequence of natural language tokens. This allows the agent to understand the intent behind database requests, rather than simply parsing SQL syntax. The LLM component enables Gen-DBA to perform semantic reasoning about database schemas, data content, and the desired outcome of each operation. Specifically, the LLM processes requests, generates appropriate database actions – including queries, updates, and schema modifications – and predicts the subsequent states of the database, facilitating complex multi-step reasoning and optimization.
Gen-DBA’s foundational architecture is based on the Transformer model, a neural network design that relies on self-attention mechanisms to weigh the importance of different parts of the input data. This allows for parallel processing of sequential data, unlike recurrent neural networks which process data step-by-step. The Transformer’s inherent parallelism significantly improves computational efficiency, especially when dealing with large datasets common in database operations. Furthermore, the model’s scalability is enhanced through its ability to be distributed across multiple processing units, enabling it to handle increasing data volumes and model complexity without substantial performance degradation. This architectural choice is critical for Gen-DBA’s ability to efficiently learn and execute complex database tasks.
Gen-DBA is trained utilizing a Goal-Conditioned Next Token Prediction approach, wherein the model learns to predict the subsequent action, or “token,” given the current database state and a specified goal. This training methodology frames database operations as a sequential decision-making process; the model receives a goal – such as optimizing query performance or reducing storage costs – and learns to select actions that move the database closer to that goal. The prediction process is autoregressive, meaning each predicted token influences subsequent predictions. The model is rewarded for actions that demonstrably improve database efficiency metrics, effectively reinforcing behaviors that lead to optimal database states and enabling it to generalize across a variety of database tasks.
![The [latex]0^{th}[/latex] generation Gen-DBA significantly outperforms baseline spatial scheduling algorithms.](https://arxiv.org/html/2601.16409v1/x3.png)
The Ritual of Learning: Data as the Seed
Gen-DBA’s training methodology is structured around a two-phase process: Pre-training and Post-training. The initial Pre-training phase focuses on establishing a broad understanding of database principles and concepts. This is followed by the Post-training phase, which concentrates on refining the agent’s capabilities for specific database tasks and workloads. This division allows for initial generalization followed by specialization, optimizing Gen-DBA’s performance across a diverse range of database management scenarios. The sequential nature of these phases is critical to the agent’s overall effectiveness and adaptability.
The Pre-training phase of Gen-DBA’s development leverages the Experience Dataset, a comprehensive compilation of database interactions designed to establish a foundational understanding of core database concepts. This dataset includes a broad range of SQL queries, database schemas, and operational scenarios, exposing the agent to diverse database structures and functionalities. The purpose of this initial phase is not to specialize in any particular task, but rather to build a generalized model capable of interpreting and responding to a wide spectrum of database-related inputs, thereby establishing the prerequisite knowledge for subsequent, task-specific training.
Post-training refines Gen-DBA’s capabilities by exposing the agent to datasets designed for specific database tasks. These specialized datasets move beyond general database concepts, allowing the agent to learn patterns and optimize performance for activities such as query generation, schema design, and database optimization. This phase focuses on supervised learning, where Gen-DBA receives feedback on its performance with these specialized datasets, iteratively improving its accuracy and efficiency in completing the targeted tasks. The datasets used in post-training are crucial for aligning Gen-DBA’s broad knowledge from pre-training with practical, real-world database applications.
Gen-DBA incorporates DB-Token, a system of hardware performance statistics used to provide real-time feedback during operation. These statistics include metrics such as CPU utilization, memory access latency, disk I/O rates, and network bandwidth. This data is continuously monitored and fed back into the agent’s decision-making process, allowing it to dynamically adjust query plans, indexing strategies, and resource allocation. The integration of DB-Token enables Gen-DBA to optimize performance based on the current hardware environment and workload, improving query execution times and overall system efficiency.
![The experience dataset comprises [latex] 80\% [/latex] demonstrations, [latex] 10\% [/latex] human-guided rollouts, and [latex] 10\% [/latex] self-play rollouts.](https://arxiv.org/html/2601.16409v1/x2.png)
The Inevitable Manifestation: Beyond Optimization
Spatial query scheduling presents a significant challenge in database management, requiring the efficient placement of index operations to minimize data access latency. Recent work has successfully demonstrated Gen-DBA’s capabilities in tackling this complexity, achieving autonomous optimization of these operations within a Non-Uniform Memory Access (NUMA) architecture. This system intelligently navigates the varying access speeds of different memory locations, ensuring data is processed where it resides, thereby reducing costly data transfers. The successful application of Gen-DBA to spatial query scheduling showcases its potential to automatically enhance database performance in scenarios demanding intricate data placement strategies and efficient resource allocation.
Gen-DBA demonstrates a sophisticated understanding of Non-Uniform Memory Access (NUMA) architecture, a critical factor in modern database performance. NUMA systems present challenges due to varying data access latencies depending on the processor and memory location; effectively managing this complexity is paramount. Gen-DBA successfully navigates these intricacies by intelligently placing index operations to minimize data transfer costs and maximize the efficiency of data retrieval. This capability isn’t simply about speed; it’s about optimizing resource utilization within the server’s memory hierarchy, ensuring that each processor core has rapid access to the data it requires. The system’s ability to dynamically adapt to the NUMA landscape allows it to consistently outperform traditional optimization strategies and achieve substantial gains in query processing speed, ultimately leading to a more responsive and efficient database system.
Gen-DBA’s architectural flexibility extends beyond query scheduling to encompass the autonomous design of core database components. The system demonstrably generates optimized configurations for elements like Learned Indexes and Cardinality Estimators, traditionally requiring extensive manual tuning by database administrators. This generative approach allows Gen-DBA to tailor these components to specific hardware and workload characteristics, effectively automating the process of performance optimization at a granular level. By autonomously evolving these crucial building blocks, Gen-DBA moves beyond simple query optimization to fundamentally reshape the internal workings of the database system itself, promising a new era of self-managing database infrastructure.
Evaluations of Gen-DBA on spatial query scheduling demonstrate a substantial performance gain, achieving a 2.51x speedup over standard operating system baselines when tested with a YCSB workload. This initial success with a 0th generation model is further amplified through strategic training methodologies; leveraging data collected across multiple servers yields an additional 2.17% improvement. Refinement through post-training fine-tuning, specifically on an Intel Skylake X server, pushes performance even further, adding another 0.56% gain. These results highlight Gen-DBA’s capacity not only to optimize database operations, but also to continually improve through data-driven learning, paving the way for increasingly autonomous and efficient database management systems.
Gen-DBA represents a paradigm shift in database management, moving beyond manual tuning towards a system capable of autonomous optimization and significantly improved resource utilization. This generative approach allows the database to proactively adapt to evolving workloads and hardware configurations, effectively streamlining operations without human intervention. By learning and implementing optimal configurations for crucial components – from index operation placement to cardinality estimation – Gen-DBA promises not just incremental gains, but a fundamental rethinking of how databases are managed, ultimately leading to more efficient, responsive, and scalable systems capable of handling the ever-increasing demands of modern data processing.
The pursuit of Gen-DBA, with its emphasis on foundation models and ‘next token prediction’ for database optimization, reveals a familiar pattern. Systems aren’t built, they accrete. The researchers don’t design optimization strategies; they cultivate an environment where emergent behaviors, exceeding human foresight, become possible. This echoes a sentiment articulated by Henri Poincaré: “The fact that a phenomenon can be predicted does not prove that it is necessary.” Long stability, celebrated as ‘uptime’, merely masks the inevitable evolution towards unforeseen states. Gen-DBA doesn’t promise a flawless system, but one capable of surprising even its creators, a testament to the inherent unpredictability of complex ecosystems.
The Horizon Recedes
The pursuit of ‘Move 37’-strategies beyond established human understanding-is less a destination and more a perpetual realignment. Gen-DBA, in framing database optimization as a next-token prediction problem, does not so much solve complexity as externalize it. The foundation model becomes the repository for unarticulated constraints, the hidden costs of every schema decision, the inevitable entropy of data itself. This is not innovation, strictly speaking, but a shifting of the burden.
One anticipates a proliferation of ‘DB-Tokens’-languages not of queries, but of potential queries, of the data a system anticipates needing, even before it is asked. The challenge, however, is not simply to generate, but to contain. Each added layer of abstraction introduces new failure modes, new dependencies masked by apparent simplicity. Technologies change, dependencies remain. The optimization landscape will not become flatter; it will simply grow more baroque.
The true test will lie not in benchmark improvements, but in the observation of failure. What unanticipated biases are embedded within these generative agents? Where do the limits of this ‘learning’ truly lie? The system, like any complex ecosystem, will reveal its vulnerabilities not through design, but through attrition. Architecture isn’t structure – it’s a compromise frozen in time.
Original article: https://arxiv.org/pdf/2601.16409.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-01-26 13:14