Author: Denis Avetisyan
Researchers have developed a novel reinforcement learning framework that combines the strengths of model-based control and data-driven techniques to create more robust and efficient walking gaits for humanoid robots.
This work presents a supervised reinforcement learning method utilizing an ‘Oracle’ policy to improve torque-based locomotion and enhance the adaptability of humanoid robots in complex environments.
Achieving robust and adaptive bipedal walking remains a challenge due to the inherent complexities of dynamics modeling and real-world uncertainties. This paper, ‘Efficiently Learning Robust Torque-based Locomotion Through Reinforcement with Model-Based Supervision’, introduces a framework that integrates model-based control with reinforcement learning, leveraging a supervised loss from an ‘oracle’ policy to accelerate learning. The approach yields improved robustness and generalization in simulated and potentially real-world environments by efficiently learning corrective behaviors for unmodeled effects. Could this supervised reinforcement learning strategy provide a scalable path toward truly versatile humanoid locomotion?
The Inevitable Imperfection of Simulated Motion
The pursuit of truly reliable bipedal robots faces substantial challenges stemming from the unavoidable gap between simulated design and messy reality. A robot’s internal model – its understanding of its own body and the world – is never a perfect representation. These inaccuracies, coupled with unpredictable external factors like uneven terrain, unexpected obstacles, or even subtle shifts in the robot’s center of mass, create a cascade of errors. Consequently, control systems struggle to maintain balance and execute planned movements smoothly. Even minute discrepancies can amplify over time, leading to instability and ultimately, falls. Researchers are actively exploring methods – from adaptive control algorithms to more sophisticated sensor integration – to mitigate these issues and enable robots to navigate the complexities of real-world environments with greater resilience.
A fundamental challenge in robotics lies in the inevitable gap between a robot’s internal model of itself and the messy reality of its physical embodiment. Even with precise engineering, imperfections in manufacturing, component variations, and unmodeled dynamics – like friction or subtle shifts in the center of mass – create discrepancies. These seemingly minor deviations accumulate during movement, introducing errors into control calculations. Consequently, the robot’s actions diverge from the intended trajectory, jeopardizing stability and hindering performance. For example, a robot attempting a precise step might overcompensate for a perceived imbalance, leading to a stumble or fall. Addressing this model-reality mismatch requires sophisticated control algorithms capable of adapting to unforeseen disturbances and continually refining the robot’s understanding of its own physical characteristics, ultimately bridging the gap between simulation and successful real-world locomotion.
Building on Imperfection: A Foundation of Dynamic Control
Model-based control forms the core of our system, relying on the creation and utilization of a dynamic model representing the robot’s physical properties and response to applied forces. This model incorporates parameters such as mass, inertia, and joint friction, enabling the prediction of robot behavior and the calculation of required control actions. Accurate state estimation, achieved through sensor fusion and filtering techniques – including but not limited to inertial measurement units (IMUs) and encoders – provides the necessary feedback for closed-loop control. The combination of a precise dynamic model and accurate state estimation allows for the planning of feasible trajectories and the computation of control inputs that minimize tracking errors and ensure stable robot operation.
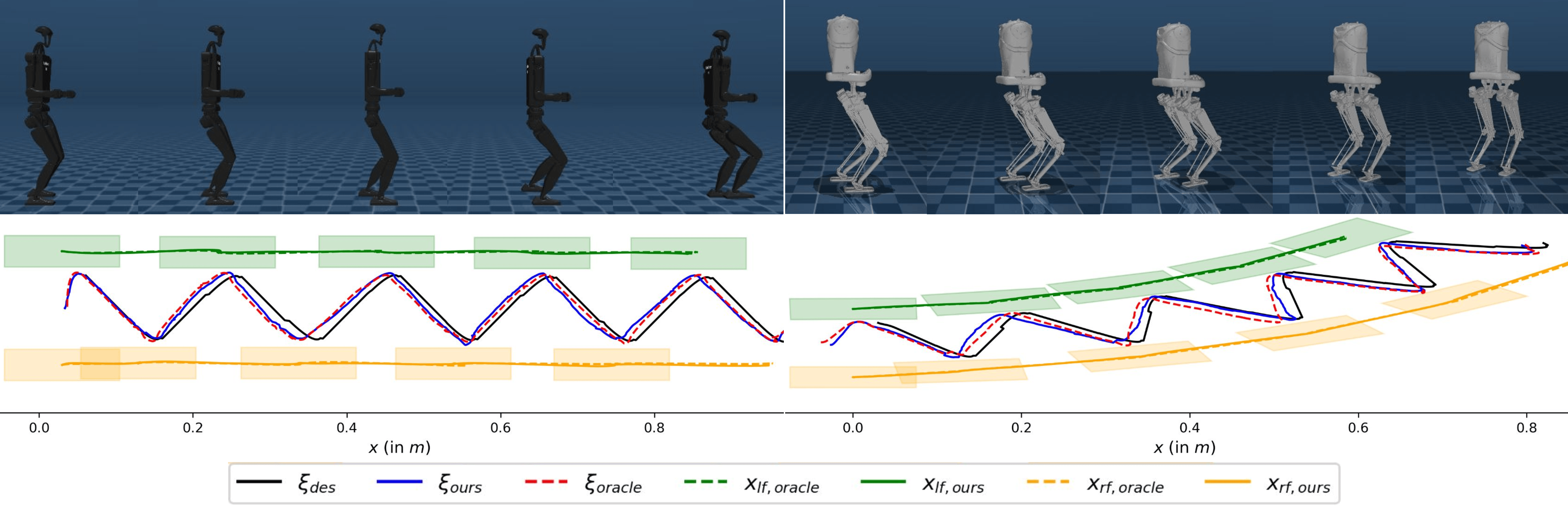
The trajectory generation framework utilizes the Divergent Component of Motion (DCM) to define desired robot motions. The DCM decomposes the desired motion into components that dictate translation, rotation, and their rates of change, allowing for the specification of a desired trajectory without explicitly defining its time evolution. This approach inherently promotes stability by naturally damping oscillations and efficiently managing momentum during locomotion. By controlling the DCM, the system can achieve stable and efficient gaits, simplifying the planning and control process compared to methods that directly specify joint trajectories or end-effector positions. [latex] \dot{D} = J \dot{q} [/latex], where [latex] D [/latex] represents the DCM, [latex] J [/latex] is the Jacobian matrix, and [latex] \dot{q} [/latex] is the joint velocity vector.
The whole-body controller utilizes an inverse dynamics approach to compute joint torques required for trajectory tracking. This involves calculating the necessary torques based on the robot’s desired motion, current state, and dynamic model, accounting for inertia, Coriolis and centrifugal forces, and gravity. The controller computes these torques for each degree of freedom, effectively translating the planned trajectory into actuator commands. The inverse dynamics calculation is performed in the joint space, allowing for precise control of the robot’s position and orientation while maintaining stability and accommodating external disturbances. [latex] \tau = M(q)\ddot{q} + C(q, \dot{q}) + G(q) [/latex], where τ represents the joint torques, [latex] M(q) [/latex] is the inertia matrix, [latex] C(q, \dot{q}) [/latex] represents the Coriolis and centrifugal forces, and [latex] G(q) [/latex] is the gravity vector.
![This framework learns a residual policy to correct inaccuracies in a base model-based controller by combining reinforcement learning [latex]\mathcal{L}_{rl}[/latex] with direct supervision from a more accurate oracle policy trained with full system knowledge.](https://arxiv.org/html/2601.16109v1/figures/FrameworkOverview.png)
Learning to Navigate the Inevitable: A Residual Correction
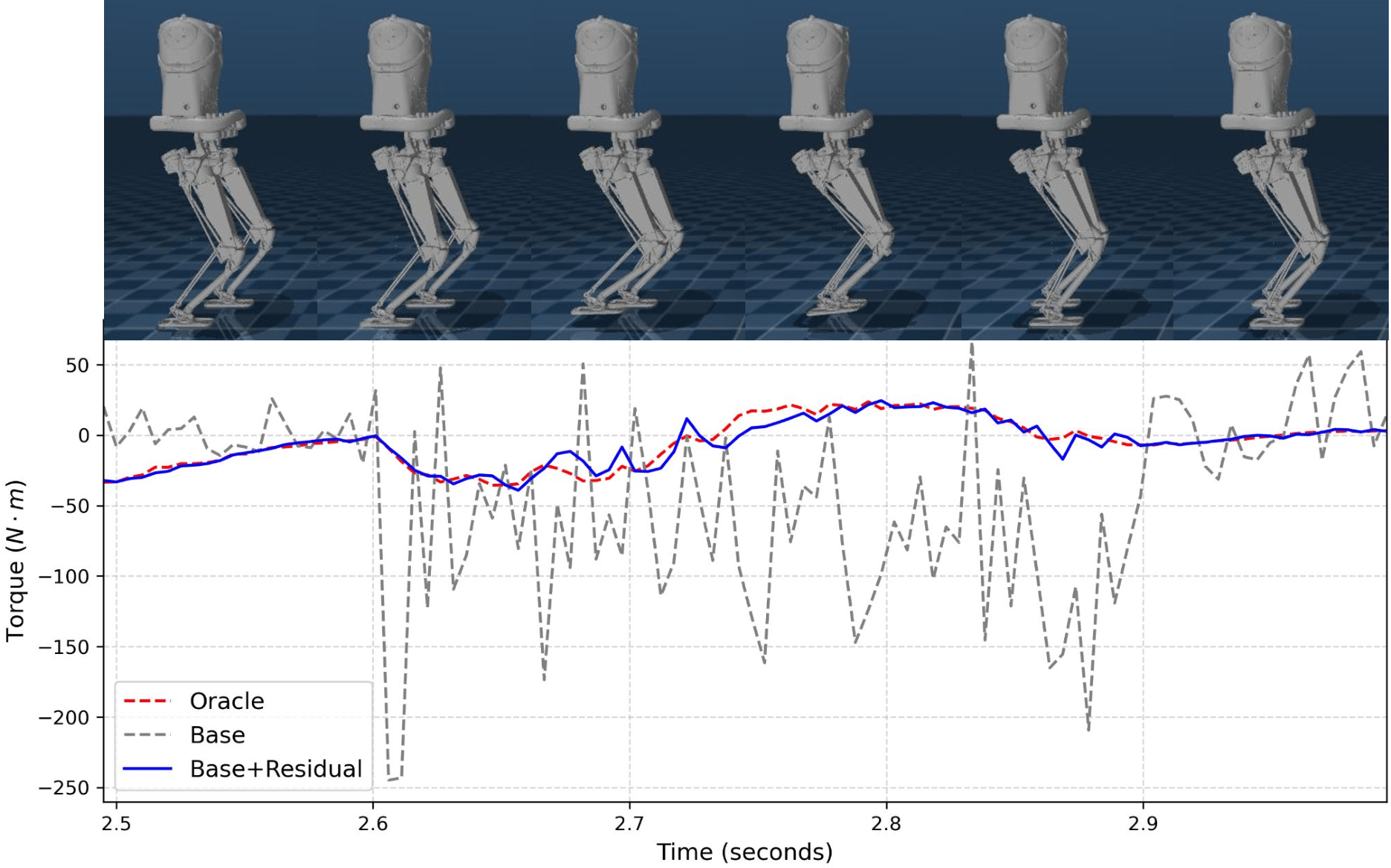
A residual policy is implemented as a learned corrective mechanism that operates in conjunction with a pre-existing model-based controller. This policy does not replace the base controller, but rather refines its output by predicting and applying adjustments to compensate for inaccuracies inherent in the model. The residual policy receives the base controller’s action as input and outputs a correction vector, which is then added to the original action before execution. This approach allows the system to benefit from the general planning capabilities of the model-based controller while simultaneously mitigating the effects of model errors, thereby improving overall performance and robustness.
The residual policy is trained via a hybrid approach combining supervised learning and deep reinforcement learning. Initially, a supervised learning phase utilizes data generated by an ‘oracle policy’ – a pre-defined policy representing optimal corrective actions – to establish a baseline understanding of necessary corrections. Subsequently, deep reinforcement learning refines this policy through interaction with the environment, allowing it to generalize beyond the oracle’s dataset and adapt to previously unseen scenarios. This combination leverages the efficiency of supervised learning for initial policy shaping and the adaptability of reinforcement learning for robust performance improvement.
The residual policy functions by directly addressing discrepancies between the base controller’s predicted actions and optimal behavior. Training utilizes error signals derived from the difference between the base controller output and an ‘oracle policy’ representing ideal control, allowing the residual policy to learn a mapping from these errors to corrective actions. This learned correction is then added to the base controller’s output during execution, effectively mitigating inaccuracies and improving the overall system’s robustness to model imperfections and environmental disturbances. Consequently, the residual policy enhances both the accuracy and consistency of the control system’s performance across a range of operating conditions.
The Illusion of Perfection: Robustness Through Controlled Chaos
Domain randomization serves as a critical component in developing robust robotic control policies, functioning as a form of ‘stress testing’ during the training phase. The residual policy isn’t simply taught what to do, but rather learns to adapt to a wide spectrum of potential real-world conditions through exposure to varied simulations. These simulations deliberately introduce discrepancies – altering friction coefficients, lighting conditions, ground textures, and even robot dynamics – forcing the policy to develop generalized solutions rather than memorizing specific responses. This approach effectively bridges the reality gap between simulation and the physical world, enabling the robot to maintain performance even when confronted with unforeseen disturbances or environmental variations, ultimately bolstering its adaptability and reliability in complex scenarios.
The developed framework exhibits remarkable versatility, successfully deployed across a diverse range of quadrupedal robot platforms – specifically the Unitree H1-2, Bruce, and Kangaroo robots. Rigorous testing on each platform consistently yielded a 100% success rate, demonstrating the robustness and adaptability of the proposed control strategy. This achievement highlights the framework’s capacity to transcend the limitations of platform-specific tuning, offering a generalized solution for dynamic locomotion control applicable to various robotic systems without requiring substantial modifications or re-calibration for each new hardware configuration.
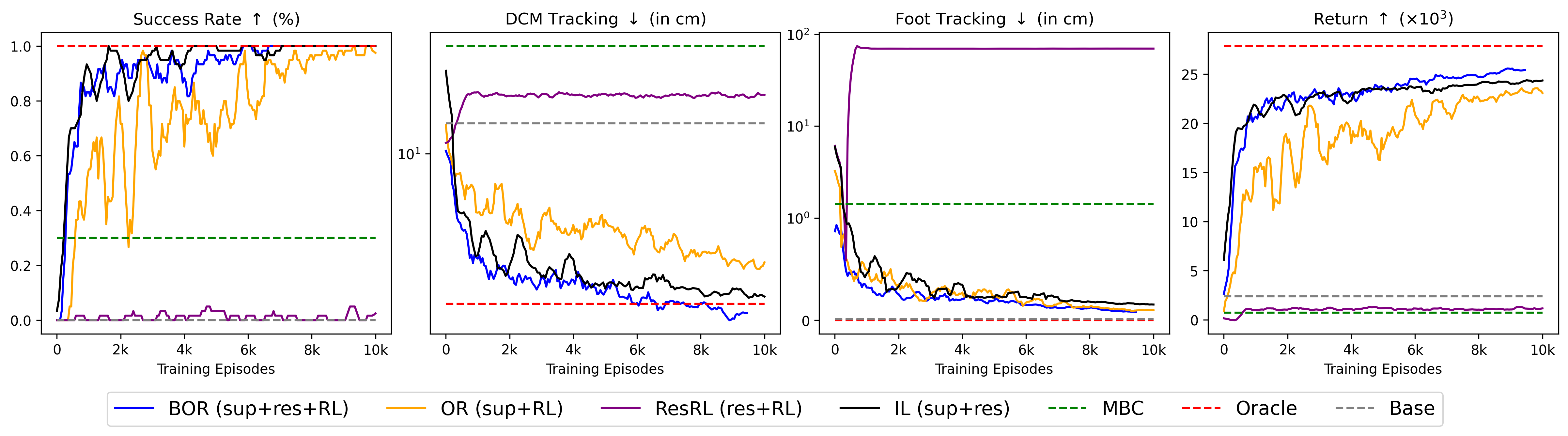
Rigorous evaluation reveals substantial performance gains facilitated by the proposed framework, as evidenced by key metrics including success rate, dynamic consistency measure (DCM) tracking error, and foot tracking error-all demonstrating marked improvements over the baseline controller. Notably, the system achieved an 80% success rate after approximately 4.16 hours of simulated training, encompassing 1,500 episodes, and attained performance levels comparable to those of an Oracle policy – a theoretically ideal controller. These results indicate not only enhanced robustness but also a capacity for sophisticated locomotion control, suggesting the framework effectively learns and implements strategies approaching optimal performance within the simulated environment.
The proposed framework exhibits a marked advantage on challenging, uneven terrain when contrasted with traditional Imitation Learning techniques. While Imitation Learning relies on replicating demonstrated behaviors, its performance is inherently constrained by the limitations of the training data – specifically, the Oracle policy’s inability to foresee and react to unpredictable ground irregularities. This method, however, moves beyond simple mimicry by leveraging simulation and randomization to cultivate adaptive behaviors. Through exposure to diverse simulated terrains, the residual policy learns to dynamically adjust its gait and maintain stability even when faced with previously unseen obstacles. This results in a robot capable of navigating complex landscapes with a robustness that surpasses the reactive capabilities of Imitation Learning, demonstrating a true capacity for autonomous adaptation.

The pursuit of robust locomotion, as detailed in this work, reveals a fundamental truth about complex systems. The ‘Oracle’ policy, functioning as a form of supervised learning, isn’t about achieving a flawless initial design, but about cultivating adaptability. G.H. Hardy observed, “The greatest enemy of knowledge is not ignorance, it is the illusion of knowledge.” This resonates deeply; a system rigidly defined by a presumed perfect model will inevitably falter when confronted with the unpredictable nuances of the physical world. The framework detailed here embraces imperfection, allowing the robot to learn from deviations and refine its gait. It isn’t about building locomotion, but fostering an ecosystem where it can grow-even through failure.
The Looming Silhouette
This work, with its careful choreography of supervision and learning, does not solve locomotion. It merely postpones the inevitable confrontation with the truly unpredictable. The ‘Oracle’ policy, however cleverly constructed, is still a prophecy written in sand – a finite expression of an infinite possibility space. Each successful step forward is, implicitly, a cataloging of future failures, a narrowing of the unknown. The system doesn’t learn to walk; it learns where it is most likely to not fall – a subtly different, and ultimately more fragile, equilibrium.
The real challenge lies not in achieving robustness within a predefined domain, but in gracefully accepting the inevitable drift beyond it. Domain randomization, as a technique, is akin to building a ship with slightly different leaks, then hoping enough of them hold. The future demands a move beyond anticipating disturbance, toward systems that become the disturbance, that internalize uncertainty as a fundamental principle of operation.
Perhaps the most potent direction lies not in more sophisticated controllers, but in radically simplified ones – policies that prioritize recoverability over precise trajectory following. A system that consistently returns to a stable state, even after catastrophic deviations, may prove far more resilient than one that strives for perfect, but ultimately brittle, execution. The goal, then, is not to build a walker, but to cultivate a tumbler.
Original article: https://arxiv.org/pdf/2601.16109.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-01-25 21:57