Author: Denis Avetisyan
A new approach leverages attention mechanisms and surrogate modeling to intelligently schedule HPC jobs, optimizing for both runtime and power consumption.

This work introduces an attention-informed surrogate framework for multi-objective Bayesian optimization of HPC scheduling, demonstrating improved Pareto front analysis using real-world telemetry data.
Balancing computational performance with energy consumption remains a core challenge in High-Performance Computing (HPC) resource management. This paper, ‘Attention-Informed Surrogates for Navigating Power-Performance Trade-offs in HPC’, introduces a novel multi-objective Bayesian optimization (MOBO) framework leveraging attention-based embeddings of job telemetry to model and optimize the runtime-power trade-off. Experimental results on production HPC datasets demonstrate that this approach consistently identifies higher-quality Pareto fronts compared to standard techniques, while also reducing training costs through intelligent data sampling. Could this embedding-informed surrogate modeling paradigm unlock more sustainable and efficient resource allocation strategies for increasingly complex HPC workloads?
Deconstructing the HPC Resource Allocation Paradox
The effective distribution of computational resources is paramount to achieving peak performance in High-Performance Computing environments, yet conventional allocation strategies often falter when faced with the intricacies of modern workloads. These traditional methods, frequently designed for simpler, more predictable tasks, struggle to adapt to the dynamic and heterogeneous nature of current applications-which may involve varying computational demands, data dependencies, and communication patterns. This mismatch leads to inefficiencies, such as underutilized processors, prolonged job queues, and ultimately, a reduction in overall system throughput. Consequently, a significant research focus lies in developing novel resource management techniques capable of intelligently handling the complexities inherent in diverse and evolving HPC workloads, moving beyond static scheduling and embracing adaptive, workload-aware allocation strategies.
High-performance computing faces a fundamental challenge in scheduling: the inherent conflict between minimizing job completion time and reducing overall power consumption – a dynamic often referred to as the ‘Runtime-Power Trade-off’. Faster computation typically demands greater energy expenditure, while prioritizing energy efficiency invariably extends the time required to complete tasks. This presents a complex optimization problem for HPC schedulers, as simply minimizing runtime can lead to unsustainable energy usage and increased operational costs. Conversely, aggressively reducing power consumption may result in unacceptable delays, hindering scientific progress and potentially impacting time-sensitive applications. Effective scheduling, therefore, requires a nuanced approach that balances these competing objectives, considering both the urgency of computations and the limitations of available power resources to achieve sustainable and efficient high-performance computing.
Effective management of High-Performance Computing (HPC) resources hinges on the ability to anticipate how long a job will take and how much power it will consume, but traditional predictive models frequently prove inadequate. These conventional techniques, often reliant on historical averages or simplified benchmarks, struggle to capture the nuanced behavior of modern, diverse workloads-particularly those exhibiting complex interdependencies or utilizing heterogeneous architectures. Consequently, schedulers may overestimate runtime, leading to underutilization of expensive hardware, or underestimate power draw, risking system instability and increased operational costs. Recent research indicates that the limitations of these models stem from their inability to dynamically adapt to the specific characteristics of each job, necessitating the development of more sophisticated techniques – such as machine learning approaches – capable of capturing the intricate relationship between workload parameters, resource allocation, and performance metrics.

Modeling the Unseen: Surrogate Models as HPC Proxies
Surrogate modeling addresses the computational cost associated with evaluating numerous scheduling alternatives in High Performance Computing (HPC) environments. These techniques create computationally inexpensive approximations – the ‘surrogate models’ – of complex HPC workload behaviors. Instead of directly simulating the execution of a job on a given resource, a surrogate model, typically trained on historical workload data, predicts key performance indicators such as completion time or resource utilization. This allows for the rapid evaluation of a large design space of scheduling options without requiring the time-consuming execution of actual workloads, significantly accelerating the optimization process. The accuracy of the surrogate model is paramount; a sufficiently accurate approximation enables near-optimal scheduling decisions based on predicted performance rather than actual measurements.
Multiple machine learning algorithms were evaluated for use as surrogate models in HPC optimization due to their differing performance characteristics. XGBoost, a gradient boosting algorithm, consistently demonstrated high predictive accuracy, though at a computational cost. Random Forest offered a balance between accuracy and efficiency, proving robust across diverse workload features. LightGBM, another gradient boosting framework, prioritized speed and memory efficiency, making it suitable for large-scale datasets. Finally, TabNet, a neural network-based approach utilizing sequential attention, showed promising results in feature selection and interpretability, potentially reducing the dimensionality of the input feature space while maintaining predictive power.
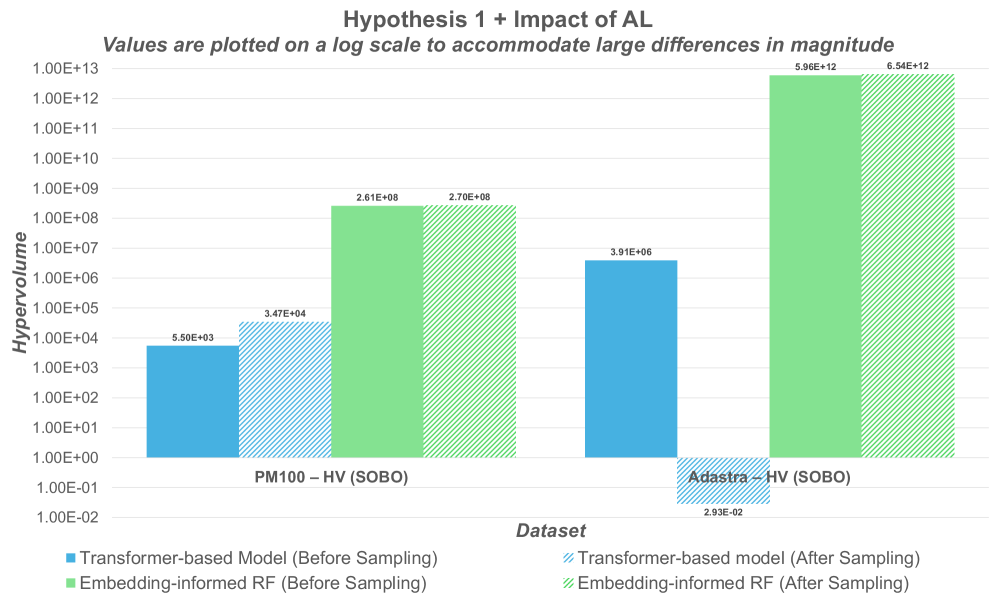
Attention-Based Embeddings were integrated into the surrogate modeling framework to improve prediction accuracy by focusing on the most impactful workload characteristics. These embeddings operate by weighting input features based on their relevance to the predicted outcome, effectively learning which features are most critical for representing workload behavior. Evaluation on the PM100 dataset revealed that models utilizing Attention-Based Embeddings achieved hypervolume (HV) improvements that were orders of magnitude greater than those obtained using standard regression techniques. This indicates a significant enhancement in the ability of the surrogate model to accurately represent the complex relationships within the HPC workload data and, consequently, to optimize scheduling decisions.
Decoding HPC Behavior: Telemetry as the Ground Truth
HPC Telemetry data forms the foundation for training and validating our surrogate models, consisting of performance metrics and resource usage data gathered from operational high-performance computing systems. This telemetry includes a range of quantifiable measurements such as CPU utilization, memory access rates, network bandwidth, and disk I/O operations. Data is collected continuously during normal system operation, providing a representative sample of diverse workloads and system behaviors. The resulting datasets enable the creation of accurate surrogate models capable of predicting system performance and resource requirements without requiring computationally expensive simulations or direct measurements on the live system.
The PM100 Dataset and the Adastra Dataset constitute the foundational data resources for our analysis of High-Performance Computing (HPC) systems. The PM100 Dataset, compiled from a range of production systems, contains performance metrics and resource utilization data covering 100 distinct workload types, representing common scientific computing applications. The Adastra Dataset expands on this with data collected from larger-scale, heterogeneous HPC environments, encompassing a wider variety of system configurations and workload profiles, including both traditional simulations and emerging machine learning applications. Combined, these datasets provide a broad and representative view of HPC system behavior, enabling the training and validation of surrogate models applicable across diverse computational scenarios and infrastructure configurations.
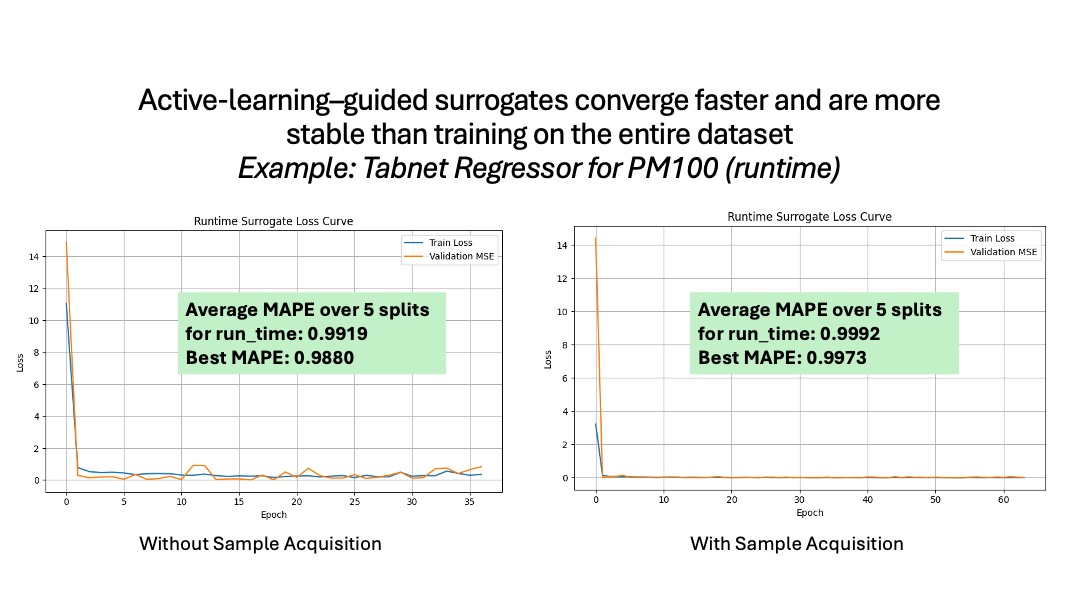
Intelligent Sample Acquisition was implemented to mitigate the challenges posed by limited labeled data in training surrogate models. This technique prioritizes the selection of the most informative data samples for model training, thereby increasing predictive accuracy while minimizing data requirements. Specifically, application of this method to the Adastra dataset resulted in a 27% reduction in the total volume of data necessary to achieve performance levels comparable to those obtained with a fully populated training set. This efficiency is achieved through algorithms that identify samples with high uncertainty or those expected to contribute significantly to model learning.
Navigating the Pareto Frontier: Optimizing for Balanced HPC Performance
High-performance computing (HPC) scheduling often presents a fundamental trade-off between minimizing job completion time and reducing overall energy consumption. This work focuses on identifying the ‘Pareto Front’, a critical concept in multi-objective optimization, which represents the set of scheduling solutions where no single solution can simultaneously improve both runtime and power usage without compromising the other. Each point on the Pareto Front defines an optimal balance – a non-dominated solution – between these competing objectives. By characterizing this front, system administrators gain insight into the achievable limits of performance and efficiency, allowing them to select a scheduling strategy that best aligns with specific application needs and resource constraints, rather than being limited to a single, potentially suboptimal, outcome. Understanding the Pareto Front is thus crucial for making informed decisions and maximizing the value of HPC resources.
The computational demands of high-performance computing (HPC) scheduling necessitate efficient methods for exploring the solution space. Instead of exhaustively testing every possible scheduling configuration – a prohibitively expensive undertaking – trained surrogate models offer a powerful shortcut. These models, built through machine learning, learn to predict the performance and power consumption of different schedules without actually running them on the hardware. This allows researchers to rapidly assess a vast number of alternatives, pinpointing those that represent the best possible trade-offs between runtime and energy usage-those that lie on the Pareto Front. By intelligently navigating this complex landscape, the system can identify scheduling strategies that deliver optimal performance while minimizing power consumption, a crucial benefit for large-scale deployments.
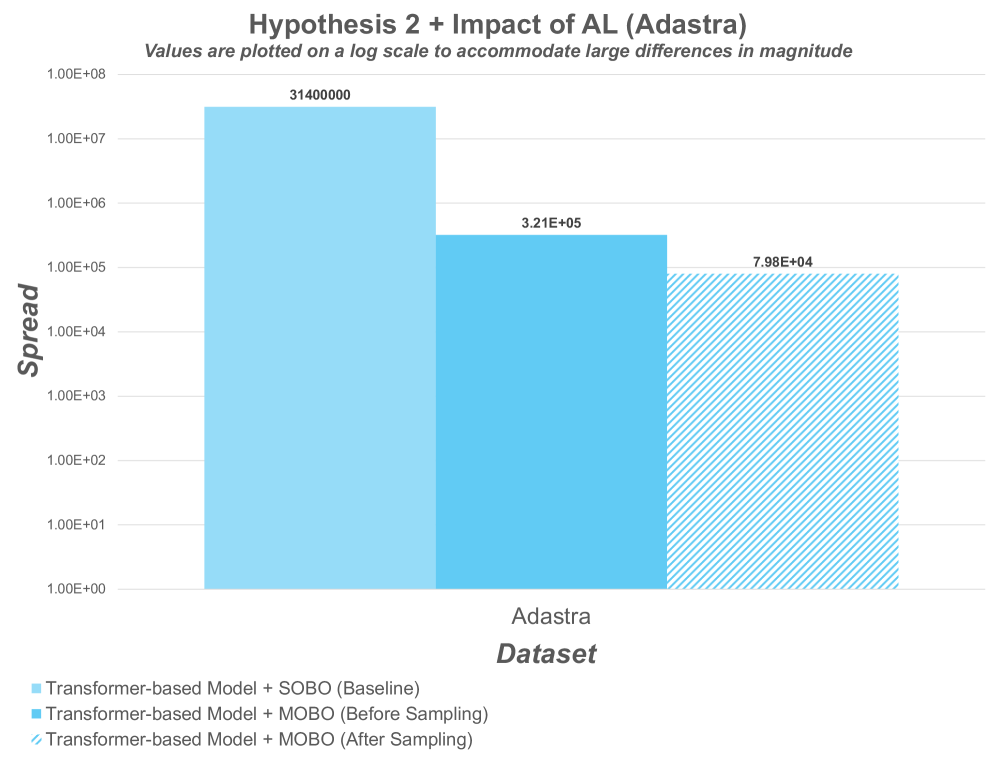
High-performance computing administrators now have access to a refined methodology for resource allocation, enabling a dynamic balance between application runtime and power consumption. A surrogate-driven, multi-objective Bayesian optimization (MOBO) framework facilitates informed decisions by efficiently exploring scheduling possibilities and identifying optimal trade-offs. Evaluations demonstrate a substantial improvement in performance; specifically, the framework achieves up to 37% higher hypervolume – a measure of Pareto front quality – when tested on the Adastra dataset, surpassing single-objective Bayesian optimization. Further, the use of attention-based embeddings minimizes solution dispersion, evidenced by a 99% reduction in spread on the PM100 dataset, thereby providing administrators with a more focused and reliable set of scheduling options tailored to specific application demands.
The pursuit of efficient HPC scheduling, as detailed in this work, inherently involves probing system limitations. It’s a process of controlled disruption, seeking the edges of performance and power consumption. Donald Davies keenly observed, “A bug is the system confessing its design sins.” This sentiment resonates deeply with the methodology presented; the attention-based surrogate models aren’t merely predicting behavior, but actively revealing the inherent trade-offs – the ‘sins’ – within the scheduling system. By exposing these weaknesses through telemetry data and MOBO, the framework facilitates a more informed navigation of the Pareto front, ultimately optimizing resource allocation not by avoiding errors, but by understanding them.
Beyond the Pareto: Future Directions
The pursuit of efficient High-Performance Computing invariably distills to a negotiation with constraints. This work demonstrates a functional, if not elegant, method for mapping the power-performance landscape, but the true challenge lies not in finding the Pareto front, but in actively violating it. Current surrogate models, even those enhanced with attention mechanisms, remain fundamentally limited by the data upon which they are trained. The next iteration necessitates a move beyond passive observation – towards systems capable of actively soliciting data from the extreme edges of the operating space, deliberately courting instability to refine the model’s predictive power.
Furthermore, the definition of “optimal” remains stubbornly fixed. The current framework treats power and performance as isolated objectives, but real-world HPC usage is a complex interplay of application requirements, user priorities, and economic considerations. Future research should explore multi-objective Bayesian optimization schemes that incorporate these higher-level constraints, potentially leveraging techniques from game theory to model the interactions between competing workloads.
Ultimately, the system’s true test will not be its ability to predict, but its capacity to mislead. A truly intelligent scheduler will not simply optimize for known parameters; it will strategically exploit the inherent uncertainties within the system, pushing boundaries and discovering previously unforeseen efficiencies – or, failing that, failing in a manner that reveals fundamental limits to computational efficiency.
Original article: https://arxiv.org/pdf/2601.15399.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-01-25 20:08