Author: Denis Avetisyan
A new approach uses reinforcement learning to intelligently select robot poses, dramatically improving the efficiency of open-loop calibration.
![The study formulates a posture selection problem guided by D-optimality, effectively prioritizing configurations that maximize information gain and minimize uncertainty in subsequent estimations [latex] \mathbf{x} [/latex].](https://arxiv.org/html/2601.15707v1/method.png)
This work presents a D-optimality-guided reinforcement learning framework for efficient system identification and calibration of a 3-DOF ankle rehabilitation robot.
Achieving accurate calibration of multi-degree-of-freedom rehabilitation robots is often hampered by the extensive experimentation required for reliable parameter identification. This paper, ‘D-Optimality-Guided Reinforcement Learning for Efficient Open-Loop Calibration of a 3-DOF Ankle Rehabilitation Robot’, addresses this challenge by introducing a novel framework leveraging reinforcement learning to intelligently select calibration postures. The core finding is that a Proximal Policy Optimization agent, trained to maximize [latex]D[/latex]-optimality, consistently outperforms random posture selection, achieving significantly higher information matrix determinants with only four carefully chosen poses. Could this approach pave the way for more streamlined and robust calibration procedures for complex robotic systems used in rehabilitation and beyond?
Deconstructing Precision: The Challenge of Robotic Calibration
Robotic performance hinges on a precise understanding of a system’s intrinsic parameters – a process known as system identification. However, conventional methods for determining these parameters often demand extensive data collection and complex computations, proving both time-consuming and laborious. Furthermore, these traditional approaches are frequently susceptible to noise within the data, stemming from sensor inaccuracies or external disturbances, which can introduce significant errors in the calibration process. Consequently, even minor inaccuracies in system identification can propagate through the robotic system, diminishing precision and hindering the robot’s ability to execute tasks reliably – a particular concern in sensitive applications like surgical assistance or prosthetic control where even millimeter-level deviations can have substantial consequences.
The efficacy of robotic systems in applications like rehabilitation is fundamentally linked to the precision of their movements, and even slight miscalibration can introduce significant errors in control. These inaccuracies manifest as deviations from intended trajectories, potentially hindering a patient’s recovery or even causing harm during assisted therapy. Beyond therapeutic contexts, inaccurate calibration compromises a robot’s ability to perform delicate tasks-from surgical procedures to precise assembly-reducing its overall utility and reliability. Consequently, a robot’s potential to deliver effective, repeatable interventions, or to function as a dependable tool, is directly limited by the fidelity of its calibration process; improvements in calibration directly translate to enhanced performance and broadened applicability.
The successful integration of robots into practical applications-from automated manufacturing and surgical assistance to in-home care and environmental exploration-hinges critically on the accuracy of their calibration. A robot’s ability to perform tasks reliably and safely depends on a precise understanding of its own physical parameters and how those parameters translate into movement. Consequently, the development of calibration techniques that are both robust to real-world noise and efficient in terms of time and resources is paramount. Without dependable calibration, even the most sophisticated robotic systems are prone to errors, limiting their functionality and potentially jeopardizing outcomes; therefore, ongoing research focuses on streamlining these processes and ensuring consistent performance across diverse and unpredictable environments.
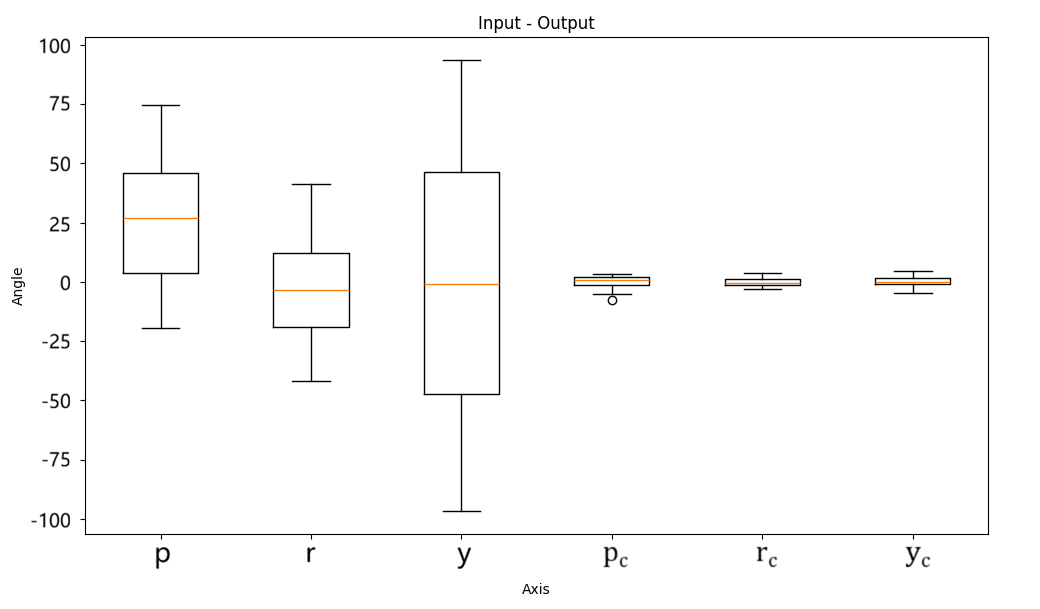
Stripping Away Complexity: Open-Loop Calibration as a Foundation
Open-loop calibration constitutes a system identification technique that determines system parameters through analysis of input signals and corresponding output responses, without requiring a closed-loop feedback mechanism. This contrasts with closed-loop methods which continuously adjust inputs based on measured outputs; open-loop calibration instead relies on a pre-defined set of inputs and the observation of the resulting outputs to build a system model. The absence of feedback simplifies the calibration process, reducing computational demands and potential instability issues, but necessitates precise input control and accurate data acquisition to ensure reliable results. This approach is particularly useful in scenarios where implementing continuous feedback is impractical or undesirable, or as an initial step to establish a baseline model before implementing more complex, feedback-based control strategies.
Calibration data, fundamental to open-loop calibration, consists of paired sets of robot commands and the corresponding achieved positions. This data is gathered through a series of controlled experiments where specific commands are issued to the robot, and the resulting end-effector or tool center point (TCP) position is precisely measured using external sensing systems like laser trackers or coordinate measuring machines (CMMs). The quality and quantity of this data directly influence the accuracy of the established relationship; a larger dataset with minimal measurement noise yields a more reliable model. This data is then used to build a mathematical representation, typically a transformation matrix or a more complex function, that maps commanded positions to actual positions, effectively characterizing the systematic errors within the robotic system.
Input-Output Alignment establishes the correspondence between robot control signals and achieved positions by systematically comparing commanded and actual robot states. This process typically involves acquiring paired data sets of input commands and resulting output positions across the robot’s workspace. Statistical methods, such as least-squares estimation, are then employed to minimize the error between the predicted and measured positions, effectively determining a transformation matrix that maps commands to positions. The resulting alignment serves as a foundational calibration, reducing systematic errors and enabling the application of more complex calibration techniques, like closed-loop refinement, to achieve higher precision.
Intelligent Exploration: Optimizing Data Acquisition with D-Optimal Design
D-Optimal Experimental Design is a methodology used in calibration processes to proactively select experimental points that yield the maximum possible information about the parameters being estimated. This approach differs from traditional methods by explicitly optimizing the experimental configuration before data collection, rather than relying on random or evenly spaced points. The core principle involves iteratively adding experimental points that minimize the generalized variance of the parameter estimates, effectively reducing uncertainty with each new measurement. Mathematically, this is achieved by maximizing the determinant of the information matrix [latex]det(S)[/latex], which represents the volume of the ellipsoid formed by the covariance matrix of the parameter estimates; a larger determinant indicates a more precise and reliable parameter estimation. By focusing on information gain, D-Optimal design minimizes redundancy in the collected data and efficiently utilizes experimental resources.
The Information Matrix, denoted as [latex]S[/latex], is a central concept in experimental design, representing the expected Fisher information contained within a set of experimental observations. Each element of [latex]S[/latex] relates to the variance of the estimator for a specific parameter, allowing quantification of the sensitivity of experimental results to changes in model parameters. The Determinant of the Information Matrix, [latex]det(S)[/latex], serves as a scalar metric for the overall information content; a larger determinant indicates a greater ability to precisely estimate model parameters. While commonly used, this metric is consistently surpassed in performance by the proposed experimental design methodology, which directly optimizes for parameter estimation accuracy rather than solely maximizing [latex]det(S)[/latex].
Strategic selection of experimental configurations, termed Experimental Point Selection, demonstrably increases the [latex]\text{det}(S)[/latex] value – the determinant of the Information Matrix – when compared to random experimental point selection. This increase in [latex]\text{det}(S)[/latex] directly correlates with improved robustness in parameter estimation. A higher determinant indicates a lower variance in estimated parameters, meaning the model is less sensitive to noise and provides more reliable results. This approach optimizes data collection efficiency by prioritizing configurations that maximize the information gained about the system parameters, ultimately leading to more accurate and precise model calibration.
![Across episodes, the variance of estimated parameters on [latex]Dataset_{3}[/latex] differs significantly depending on the experimental point selection strategy employed.](https://arxiv.org/html/2601.15707v1/X_variance_summary.png)
Letting the Machine Learn: Reinforcement Learning for Adaptive Calibration
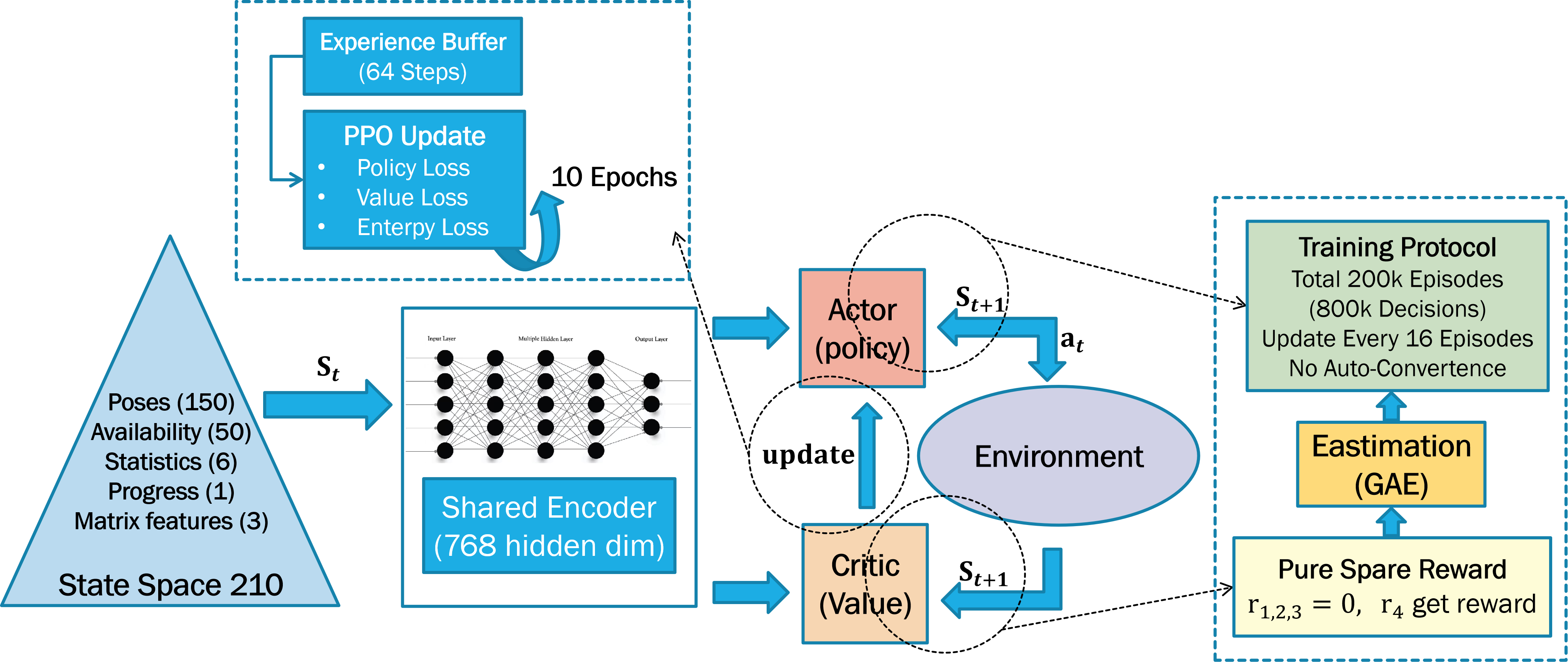
Reinforcement Learning (RL) offers a methodology for automated experimental design by formulating the calibration process as a sequential decision-making problem. An RL agent interacts with a simulated or real robotic system, iteratively selecting experimental points – specific system inputs – and observing the resulting outputs. This interaction allows the agent to learn a policy that maps system states to optimal experimental choices. Crucially, the agent adapts to the unique characteristics of the robotic system, such as actuator limitations, sensor noise, and nonlinear dynamics, without requiring an explicit model. The agent’s objective is to maximize a cumulative reward signal, which is designed to reflect the information gained from each experiment and the progress towards an accurate system calibration. This contrasts with traditional calibration methods that rely on pre-defined sampling strategies or require substantial manual intervention.
The Proximal Policy Optimization (PPO) algorithm was implemented as the reinforcement learning method due to its stability and sample efficiency. PPO functions by iteratively improving a policy, represented as a probability distribution over actions, while ensuring that each update remains close to the previous policy, preventing drastic changes that could destabilize learning. To further refine the agent’s behavior, reward shaping was incorporated, providing intermediate rewards based on the information gain achieved by each selected configuration. This encourages the agent to prioritize configurations that actively reduce uncertainty in the robotic system’s parameters, as quantified by the variance of predicted outputs. The resulting reward function, combining intrinsic and extrinsic components, effectively guides the PPO agent towards optimal experimental point selection for calibration.
Quantitative analysis demonstrates that the proposed reinforcement learning-based calibration method consistently minimizes cross-episode parameter variance compared to random experimental point selection. This reduction in variance-measured as the standard deviation of estimated parameters across independent simulation episodes-directly correlates with improved accuracy in predicting system outputs. Specifically, lower variance indicates that the calibration process is less sensitive to stochasticity within the simulation environment, leading to more reliable parameter estimates. This enhanced reliability translates to stronger generalization capabilities, allowing the calibrated system to maintain predictive performance when applied to previously unseen conditions or datasets.
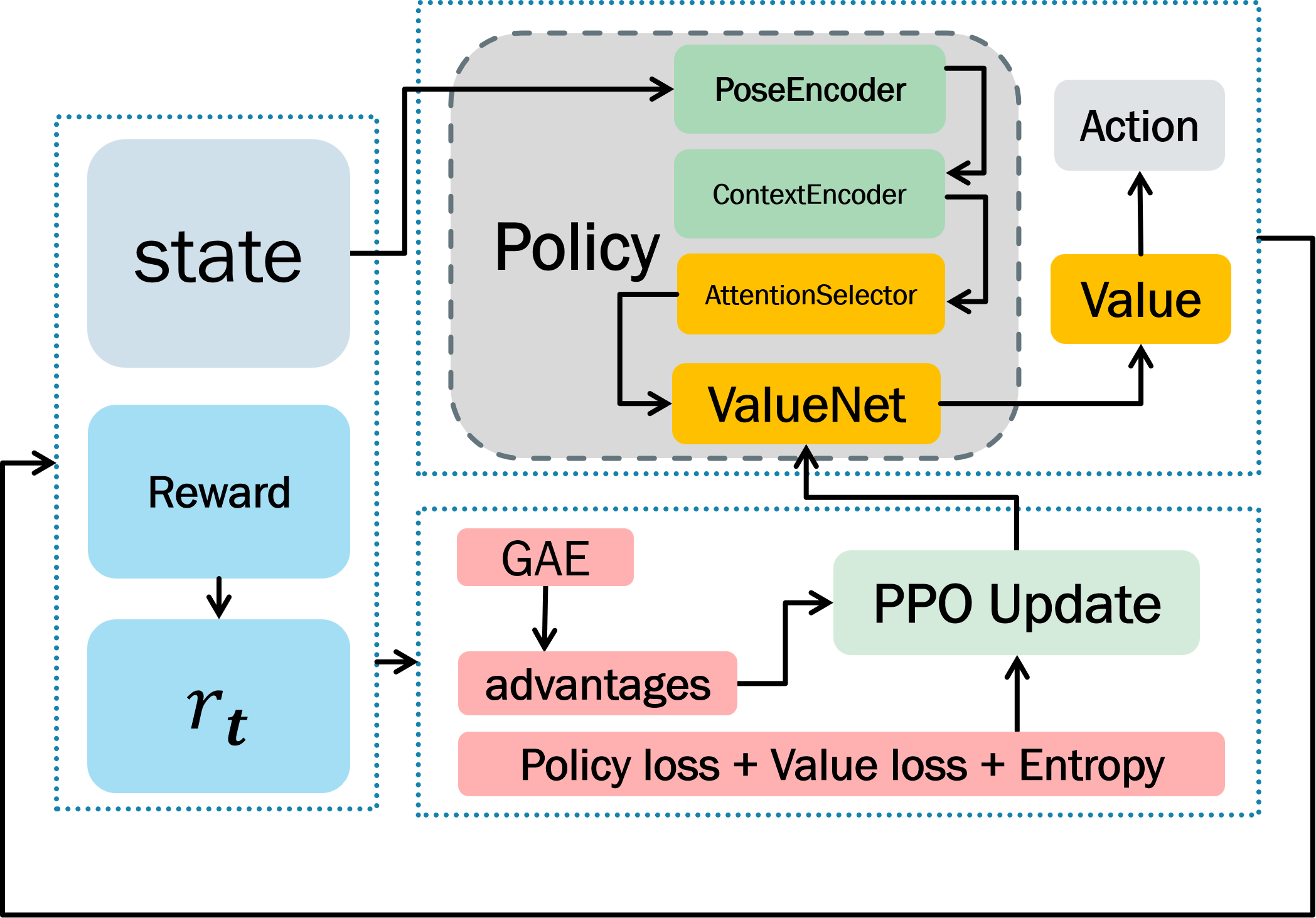
Beyond Static Models: Towards Enhanced Ankle Rehabilitation Through Adaptive Robotics
Current robotic rehabilitation systems often struggle with the inherent variability in patient response and the complexities of human movement. To address this, researchers are integrating reinforcement learning with a technique called open-loop calibration to create adaptive robotic systems. This combination allows the robot to move beyond pre-programmed motions and dynamically adjust its performance during a rehabilitation session. Open-loop calibration establishes an initial, accurate baseline for the robot’s movements, while reinforcement learning then allows the system to learn from each patient interaction, subtly refining its parameters – speed, force, range of motion – to optimize the exercise delivery. This creates a continuously improving, closed-loop system where the robot doesn’t just execute a plan, but actively learns and adapts to maximize the therapeutic benefit for each individual, ultimately paving the way for more personalized and effective recovery programs.
Precise execution of rehabilitation exercises hinges on a robot’s ability to consistently and accurately achieve the intended postural configurations. Recent advancements enable robots to select and maintain these postures with greater fidelity, moving beyond pre-programmed movements to dynamically adjust based on patient-specific needs and real-time feedback. This accurate posture selection is achieved through sophisticated algorithms that account for variations in patient anatomy, range of motion, and exercise protocol. The result is a robotic system capable of delivering prescribed movements – such as dorsiflexion or plantarflexion – with the consistency and precision required to stimulate muscle recovery and optimize therapeutic outcomes. By minimizing deviations from the intended exercise form, the system enhances the effectiveness of each repetition, promoting targeted muscle strengthening and accelerating the return to functional mobility.
The convergence of reinforcement learning and open-loop calibration within robotic rehabilitation systems holds considerable promise for accelerating patient recovery and enhancing functional outcomes following ankle injury. This integrated methodology allows for a dynamically adaptive treatment regimen, tailoring exercises to an individual’s progress in real-time – a departure from traditional, static rehabilitation protocols. By continuously refining the robot’s parameters based on patient performance, the system ensures precise and effective delivery of prescribed movements, maximizing therapeutic benefit. Consequently, patients may experience reduced recovery times, improved range of motion, and a greater ability to regain pre-injury functionality, ultimately contributing to a higher quality of life post-rehabilitation.
The pursuit of efficient calibration, as demonstrated in this work concerning a 3-DOF ankle rehabilitation robot, mirrors a fundamental principle of understanding any system: intelligent probing. One might recall Claude Shannon’s assertion that, “The most important thing in communication is to convey information.” This paper doesn’t merely calibrate; it strategically queries the robot’s state space, leveraging D-optimal experimental design and reinforcement learning to actively seek out the most informative postures. The system isn’t passively accepting data; it’s actively shaping the experiment, maximizing information gain with each movement – a process of reverse-engineering the robot’s behavior through focused, data-driven interaction. This echoes a core tenet: knowledge isn’t found, it’s extracted through clever interrogation.
Beyond the Calibration Horizon
The pursuit of efficient calibration, as demonstrated, inevitably exposes the inherent limitations of any model-based system. This work successfully navigates the challenge of reducing experimental burden, but the underlying premise – that a finite set of postures can fully encapsulate the robot’s behavior – remains a simplification. Future efforts must confront the reality of unmodeled dynamics, sensor drift, and the ever-present spectre of environmental variation. The true test isn’t minimizing calibration time, but maximizing robustness despite imperfect knowledge.
One can envision a shift from calibration as a discrete event to a continuous, adaptive process. Reinforcement learning, ideally, shouldn’t merely select postures, but actively interpret discrepancies between predicted and observed behavior, effectively learning the model errors themselves. This demands a move beyond purely geometric calibration toward identification of dynamic parameters and, crucially, an assessment of their uncertainty. The best hack is understanding why it worked; every patch is a philosophical confession of imperfection.
Ultimately, the focus should extend beyond the robot itself. The interaction between the rehabilitation device and the patient introduces a further layer of complexity – a dynamic system defined not just by actuators and sensors, but by biological adaptation. True efficiency lies not in calibrating the machine, but in designing a system capable of calibrating to the patient, and even anticipating their evolving needs.
Original article: https://arxiv.org/pdf/2601.15707.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-01-25 08:27