Author: Denis Avetisyan
A new framework generates complex, multimodal question-answer datasets to push the boundaries of Retrieval-Augmented Generation evaluation.
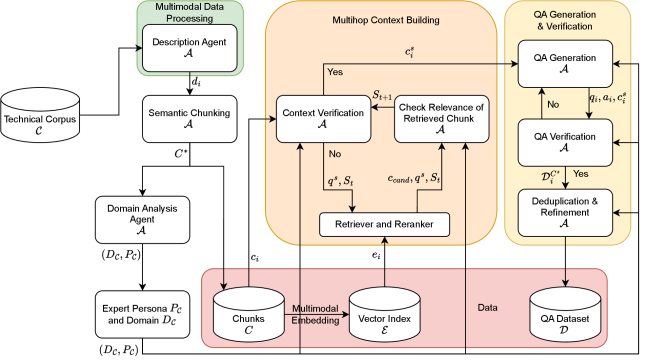
MiRAGE employs a multiagent system for creating high-fidelity datasets designed to assess knowledge retrieval and reasoning in complex, domain-specific scenarios.
Despite advances in Retrieval-Augmented Generation (RAG), evaluating these systems remains challenging, particularly with complex, multimodal, domain-specific knowledge-a gap this work addresses through ‘MiRAGE: A Multiagent Framework for Generating Multimodal Multihop Question-Answer Dataset for RAG Evaluation’. MiRAGE introduces a multiagent framework that automatically generates high-quality, verified question-answer datasets demanding multi-hop reasoning across both text and images. Empirical results demonstrate that MiRAGE generates datasets with significantly higher reasoning complexity and factual faithfulness compared to existing benchmarks, while also revealing the potential of large language models when paired with textual image descriptions. Will this automated dataset creation unlock more robust and reliable evaluation metrics for the next generation of information retrieval systems, and can visual grounding be fully achieved?
The Illusion of Understanding: Why Scale Isn’t Enough
Despite their remarkable ability to generate human-quality text, Large Language Models frequently encounter difficulties when tasked with complex, multi-hop reasoning. These models excel at identifying patterns and associations within data, enabling them to produce coherent and contextually relevant outputs for single-step inferences. However, problems arise when a question or task requires synthesizing information from multiple sources or performing a series of interconnected logical steps. The models often struggle to maintain focus on the initial query throughout this process, leading to errors in inference or a loss of coherence in the final response. This limitation suggests that simply increasing the scale of these models – adding more parameters or training data – may not be sufficient to overcome the fundamental challenges inherent in true, multi-step reasoning.
Despite their fluency, current Large Language Models frequently encounter difficulties when tasked with reasoning that requires integrating information from multiple sources. The models often struggle to maintain contextual coherence as they process each new piece of information, leading to a gradual erosion of accuracy and relevance. This isn’t simply a matter of forgetting earlier details; rather, the very architecture of these models, while adept at identifying patterns, struggles with the nuanced synthesis required for true multi-hop reasoning. Consequently, answers can become internally inconsistent, or based on a misinterpretation of the relationships between different facts-a phenomenon particularly pronounced when dealing with complex, interconnected topics where subtle distinctions are critical. The result is a tendency toward plausible-sounding but ultimately inaccurate responses, highlighting a fundamental limitation in their ability to reliably extract and combine knowledge.
Despite the remarkable progress achieved by scaling transformer models, a fundamental plateau exists in their ability to perform complex reasoning. Simply increasing model size and training data yields diminishing returns, as these models primarily excel at pattern recognition and statistical correlations rather than genuine understanding or inferential capability. This limitation stems from the inherent architecture, which struggles with maintaining long-range dependencies and accurately integrating information across extended contexts-critical for multi-step reasoning. Consequently, researchers are actively pursuing innovative approaches beyond scale, including incorporating symbolic reasoning, knowledge graphs, and neuro-symbolic architectures, to imbue these models with the capacity for deeper, more reliable reasoning and ultimately overcome the limitations of purely statistical approaches.
Divide and Conquer: The Promise of Multi-Agent Systems
Multi-Agent Systems (MAS) address complex reasoning tasks by distributing computational demands across multiple autonomous agents. This paradigm shifts away from monolithic systems that require a single processor to handle all aspects of a problem. Instead, MAS decompose the overall task into smaller, specialized sub-tasks, assigning each to an agent designed for efficient processing. Each agent operates independently, managing its own knowledge and reasoning processes, but collaborates with others through defined communication protocols. This distribution of cognitive load allows for parallel processing, increased scalability, and improved robustness; if one agent fails, others can potentially compensate, maintaining overall system functionality. The specialization of agents also enables optimization for specific sub-problems, leading to enhanced accuracy and efficiency compared to general-purpose reasoning systems.
Problem decomposition within Multi-Agent Systems (MAS) involves breaking down a complex task into smaller, independent sub-tasks, each assigned to a specific agent. This distribution of labor allows for parallel processing, significantly improving computational efficiency compared to monolithic approaches. Furthermore, specialized agents can be designed and trained to excel at their assigned sub-tasks, leading to increased accuracy in overall system performance. This modularity also facilitates easier debugging, maintenance, and scalability, as modifications to one agent do not necessarily require changes to the entire system. The assignment strategy – how sub-tasks are allocated to agents – is a critical factor influencing both efficiency and accuracy, with algorithms often employed to optimize this distribution based on agent capabilities and task dependencies.
Multi-Agent Systems (MAS) demonstrate improved reasoning performance when processing multimodal data, specifically integrating text and image inputs. This enhancement stems from the ability of specialized agents within the MAS to independently process each modality, extracting relevant features and contextual information. These independently derived representations are then combined through inter-agent communication, enabling a more comprehensive understanding of the input data than would be possible with unimodal processing. The system benefits from complementary information – textual descriptions providing semantic context and images offering visual details – leading to more accurate and robust knowledge synthesis. Agents can be designed to focus on specific aspects of each modality, such as object recognition in images or named entity recognition in text, further refining the combined representation and improving overall reasoning capabilities.
MiRAGE: Rigorous Evaluation Through Automated Challenge
MiRAGE addresses the need for more robust evaluation of Retrieval-Augmented Generation (RAG) systems by automatically generating question-answer datasets that demand complex reasoning. Unlike existing benchmarks often limited to single-hop questions relying on direct fact retrieval, MiRAGE creates datasets requiring multiple reasoning steps – an average of 2.3 hops with peaks at 2.84 across varied domains including Finance, Regulation, and Science. The framework’s novelty lies in its ability to produce challenging datasets through automated construction, rather than manual annotation, enabling scalable and rigorous assessment of a RAG system’s capacity for multi-hop reasoning and information synthesis. Datasets generated by MiRAGE are designed to be multimodal, incorporating both textual and visual inputs to further test the capabilities of advanced RAG pipelines.
The MiRAGE framework utilizes a Multi-Agent System (MAS) to create complex question-answer chains. This system consists of specialized agents, including those powered by Vision Language Models (VLMs) and Large Language Models (LLMs), which collaboratively construct reasoning paths to answer questions. Evaluation demonstrates an average reasoning “hop count” of 2.3 across datasets in the Finance, Regulation, and Science domains, with a maximum observed hop count of 2.84. This multi-hop reasoning is a key characteristic of the generated datasets, designed to rigorously test the capabilities of Retrieval-Augmented Generation (RAG) systems.
The MiRAGE framework prioritizes dataset quality through two key preprocessing stages: Semantic Chunking and Data Deduplication. Semantic Chunking divides source documents based on conceptual meaning, rather than fixed-size windows, to create more coherent and relevant retrieval units. Following chunking, Data Deduplication identifies and removes redundant or near-duplicate passages within the generated dataset, minimizing bias and improving the diversity of retrieved information. These processes consistently result in high faithfulness scores – exceeding 0.91 across tested domains including Finance, Regulation, and Science – indicating a strong correlation between the generated answers and the supporting evidence within the constructed datasets.
Beyond Retrieval: Grounding Answers in Expertise and Truth
The efficacy of MiRAGE, and Retrieval-Augmented Generation (RAG) systems generally, hinges critically on two interconnected factors: access to highly specific domain knowledge and the faithful embodiment of an expert persona. These systems don’t simply retrieve information; they construct answers, and the quality of those answers is directly proportional to the depth and accuracy of the knowledge base they draw upon. Moreover, simply possessing data isn’t enough; the system must effectively role-play an expert – understanding not just what an expert knows, but how that expert would articulate and prioritize information. A successful implementation requires careful curation of domain-specific resources and a robust mechanism for shaping the system’s responses to reflect the nuanced perspective and reasoning patterns of a subject matter authority, ultimately bridging the gap between data retrieval and insightful, credible answers.
The reliability of modern multi-agent systems (MAS) hinges on robust verification mechanisms; simply retrieving or generating information is insufficient without confirming its validity. These ‘Verification Agents’ function as critical filters, meticulously assessing the accuracy of both the information sourced from external knowledge bases and the content created by the system itself. This process isn’t merely about identifying factual errors, but also about detecting inconsistencies, biases, or irrelevant data that could compromise the final answer. By incorporating these agents, the system avoids propagating misinformation and ensures that responses are grounded in verifiable evidence, building trust and enhancing the overall utility of the MAS for complex reasoning tasks and decision-making processes.
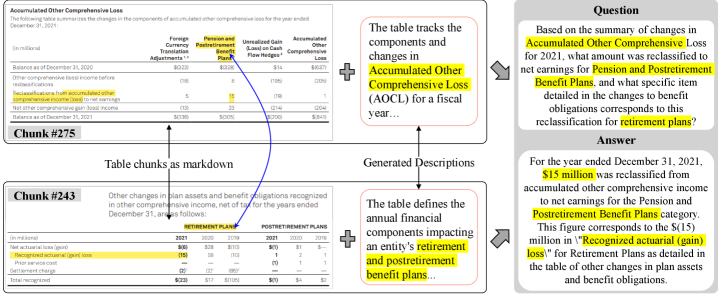
Evaluations using the UNECE GTRs dataset reveal MiRAGE’s substantial multimodal reasoning skills, achieving a peak visual grounding score of 0.45. This indicates the framework effectively correlates visual information with textual data to establish a coherent understanding. Beyond accurate reasoning, MiRAGE prioritizes consistency; JS Divergence metrics confirm the generated datasets maintain thematic integrity, ensuring outputs remain relevant and focused. This dual emphasis on both reasoning accuracy and content preservation highlights MiRAGE’s capability to not only answer questions, but to produce reliable and contextually appropriate information from multimodal inputs.
The pursuit of ever-more-complex RAG systems, as demonstrated by MiRAGE’s multi-agent approach, feels…familiar. It’s a beautifully intricate solution searching for a problem that will inevitably evolve. One suspects that within a decade, these meticulously crafted, multi-hop datasets will be considered quaint, surpassed by emergent behaviors no one anticipated. As Grace Hopper observed, “It’s easier to ask forgiveness than it is to get permission.” This framework, while impressive in its scope, is essentially building a more elaborate scaffolding for the inevitable entropy. The system will crash, the data will drift, and someone will be left deciphering the digital archaeology of its design choices. It’s not a criticism, merely an observation-if a system crashes consistently, at least it’s predictable.
What’s Next?
The proliferation of synthetic datasets, as exemplified by MiRAGE, feels less like progress and more like a beautifully engineered delay of inevitable failure. Each layer of abstraction-agents generating questions, systems evaluating answers-adds another point of divergence from the messy reality of production. It’s a comforting illusion that rigorous evaluation, even against carefully constructed challenges, can truly predict performance when faced with users who defy categorization and data that refuses to cooperate.
The focus on multimodal, multi-hop reasoning is, of course, necessary. But the assumption that a more complex benchmark equates to a more robust system feels… optimistic. The true test won’t be whether a RAG system can navigate a synthetic knowledge graph, but whether it can gracefully degrade when confronted with irrelevant images, poorly formatted documents, and the inherent contradictions within any real-world knowledge source.
Future work will undoubtedly explore ever more sophisticated agentic frameworks, aiming to generate datasets that are indistinguishable from human-created content. But it’s worth remembering that documentation is a myth invented by managers, and that the only constant in software development is the emergence of unforeseen edge cases. CI is the temple-one prays nothing breaks when deployed.
Original article: https://arxiv.org/pdf/2601.15487.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-01-25 06:47