Author: Denis Avetisyan
A new reinforcement learning approach enables robots to rapidly acquire complex skills using just a single example, bridging the gap between simulation and real-world deployment.
![Soft Q-learning, when employing a Gaussian policy with standard deviation [latex]\sigma_{\pi} = 0.1[/latex], demonstrates that a standard negative entropy term encourages policy improvement to select out-of-distribution actions, while a sigmoid-bounded entropy function constrains this effect, establishing a more well-defined action space and clearer region of high Q-values for maximization-particularly when sampled actions remain within [latex]1.5\sigma_{\pi}[/latex] of the mean.](https://arxiv.org/html/2601.15761v1/figures/draw_entropy_concept_4_compare_Q_H_Z.png)
SigEnt-SAC combines sigmoid-bounded entropy regularization with gated behavior cloning to achieve high sample efficiency and robustness in offline-to-online robot learning.
Despite advances in deep reinforcement learning, deploying agents in real-world robotic settings remains challenging due to the need for extensive data and robust handling of sparse rewards and noisy observations. This paper introduces a novel approach, ‘Off-Policy Actor-Critic with Sigmoid-Bounded Entropy for Real-World Robot Learning’, which achieves high sample efficiency by learning directly from a single expert trajectory. The core innovation lies in a sigmoid-bounded entropy term that stabilizes learning and prevents exploitation of out-of-distribution actions, coupled with gated behavior cloning. Demonstrated across diverse robotic embodiments and benchmarked on standard D4RL tasks, can this framework pave the way for more practical and cost-effective real-world reinforcement learning deployments?
The Challenge of Offline Reinforcement Learning: Data Sufficiency and Extrapolation Error
Conventional reinforcement learning algorithms typically require an agent to learn through continuous interaction with an environment, a process often involving millions of trials and errors. This presents a significant hurdle when applying these techniques to real-world problems; for instance, training a robotic system demands considerable physical wear and tear, while deploying an agent in healthcare or finance necessitates minimizing potentially harmful exploratory actions. The sheer volume of data needed for effective online learning can also be prohibitively expensive or time-consuming to acquire, particularly in scenarios where each interaction carries a real-world cost or requires human supervision. Consequently, the practical implementation of traditional reinforcement learning is often limited by the need for extensive, and sometimes infeasible, online experimentation.
Offline reinforcement learning presents a compelling alternative to traditional methods by enabling agents to learn effective policies from pre-existing datasets, eliminating the need for costly or impractical online interaction. However, a significant challenge arises from what is known as extrapolation error: the agent encounters states or actions during learning that are not well-represented in the static dataset. This mismatch leads to inaccurate estimations of future rewards, as the agent attempts to generalize beyond the scope of its training experience. Consequently, policies learned through offline RL can exhibit unpredictable and potentially unsafe behavior when deployed in real-world scenarios, necessitating careful consideration of data coverage and the development of algorithms that mitigate the risks associated with venturing outside the boundaries of the observed data distribution.
A central challenge in offline reinforcement learning arises from the distributional shift between the static dataset used for training and the actions a learned policy might subsequently take. Because the agent learns from data generated by a potentially different, and often suboptimal, policy, it can encounter states and actions not well-represented in the training data. This leads to extrapolation errors – inaccurate predictions of outcomes for unseen state-action pairs – which can severely degrade performance and, critically, compromise safety. An agent confidently acting outside the support of its training data may exhibit unpredictable and potentially hazardous behavior, necessitating careful constraint and regularization techniques to ensure robust and reliable offline learning.
Constraining Policy Exploration: A Conservative Approach to Offline RL
Conservative Q-Learning (CQL), Calibration-aware Q-Learning (Cal-QL), and Implicit Q-Learning (IQL) mitigate extrapolation error by directly modifying the Q-function learning process. These algorithms introduce a penalty term to the standard Q-learning loss function, reducing the estimated Q-values for actions that are rarely or never observed within the offline dataset. This penalty encourages the agent to assign lower values to out-of-distribution actions – those significantly different from the data used for training – effectively constraining the learned policy to the support of the training data and preventing overestimation of unseen action-state pairs. The strength of this penalty is a tunable hyperparameter, allowing for control over the degree of conservatism applied during learning.
Conservative policy optimization methods constrain the learned policy by penalizing Q-values associated with actions outside the distribution of the offline dataset. This constraint directly addresses the extrapolation error problem, where Q-learning algorithms can overestimate the value of state-action pairs not represented in the training data. By limiting the policy’s ability to select and value these out-of-distribution actions, these methods prevent the algorithm from exploiting spurious correlations or generalizing to unseen scenarios, leading to more stable and reliable performance when learning from static datasets.
Constraining policy exploration in offline reinforcement learning algorithms directly addresses the issue of distributional shift, which commonly degrades performance when applying learned policies to states not well-represented in the training data. By limiting the range of actions considered during policy evaluation, these methods reduce the likelihood of extrapolating Q-values to out-of-distribution actions, thereby minimizing overestimation bias. This explicit regularization enhances the stability of the learning process, particularly on datasets with limited coverage or high dimensionality, and consistently results in improved performance compared to unconstrained offline algorithms. The benefit is most pronounced on challenging datasets where extrapolation errors are prevalent, and the learned policy would otherwise exhibit unpredictable or suboptimal behavior.
![Introducing a negative entropy term during policy optimization increases the frequency of out-of-distribution (OOD) actions-quantified by [latex] ext{Eq. 3}[/latex] with a threshold of 0.3-but can be mitigated by applying LayerNorm to Cal-QL to stabilize network behavior.](https://arxiv.org/html/2601.15761v1/x1.png)
Sigmoid-Bounded Entropy: Enhancing Sample Efficiency in Offline RL
SigEnt-SAC addresses limitations in standard Soft Actor-Critic (SAC) algorithms when applied to offline reinforcement learning by introducing a modified entropy formulation. Traditional SAC relies on maximizing entropy to encourage exploration; however, in offline settings – where interaction with the environment is limited to a fixed dataset – unrestricted entropy maximization can lead to instability and suboptimal policies. SigEnt-SAC constrains the entropy using a sigmoid function, effectively bounding its range and preventing excessively high entropy values that might promote overly exploratory or random behaviors. This bounded entropy encourages the agent to focus on learning from the existing dataset more effectively, leading to improved stability and performance in offline learning scenarios without requiring any online environment interaction.
SigEnt-SAC utilizes a sigmoid function to constrain the entropy term within the Soft Actor-Critic (SAC) algorithm. Traditional SAC implementations can exhibit instability due to unbounded entropy, leading to overly stochastic policies. By applying a sigmoid, the entropy is limited to a predefined range, preventing excessively high values that encourage indiscriminate exploration. This bounded entropy promotes a more focused exploration strategy, directing the agent towards potentially rewarding actions with greater efficiency and ultimately improving learning stability in offline reinforcement learning scenarios.
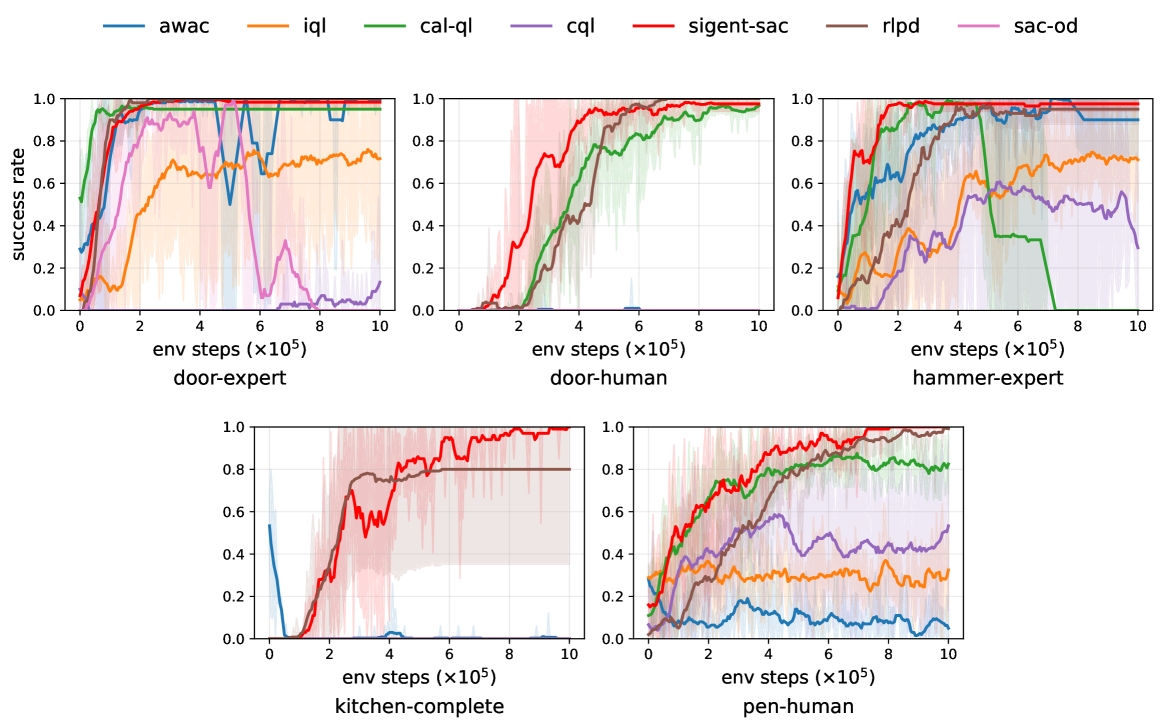
Integration of Sigmoid-Bounded Entropy with Gated Behavior Cloning enables successful completion of real-world robotic tasks utilizing data from a single demonstration. This methodology consistently achieves a 100% success rate across tested robotic applications. Performance metrics indicate a 40.9% average reduction in task completion time when compared to the original demonstration data provided, demonstrating a significant improvement in efficiency and operational speed. This outcome is achieved by leveraging the single demonstration to bootstrap learning, combined with the stability provided by entropy regularization.
Evaluations on the ball-to-goal task demonstrate SigEnt-SAC’s enhanced sample efficiency; the agent achieved an 88.46% reduction in the number of steps required for task completion compared to the provided demonstration dataset. This indicates a substantial improvement in learning from limited data, as the agent not only replicates the demonstrated behavior but actively optimizes it to achieve faster completion times. The metric directly quantifies the algorithm’s ability to extract maximal performance from a fixed dataset, exceeding the performance level present within the original demonstration.
![SigEnt-SAC demonstrates consistent robustness to varying demonstration qualities-including [latex]\sigma=0.2[/latex] action and state noise, and 50% data drops-whereas Cal-QL experiences significant performance decline, particularly during the hammer task.](https://arxiv.org/html/2601.15761v1/x6.png)
The Synergistic Potential of Large Language Models and Reinforcement Learning
Reinforcement learning agents traditionally learn through trial and error, requiring vast amounts of data to navigate complex environments. However, integrating large language models introduces a powerful shortcut: semantic priors. These models, pre-trained on massive text datasets, possess an inherent understanding of language, concepts, and relationships – essentially, a wealth of pre-existing knowledge about the world. This knowledge isn’t simply added to the RL agent; rather, it constrains the search space, guiding exploration towards more promising actions and accelerating learning. By leveraging the LLM’s understanding of task descriptions, object affordances, and even common sense reasoning, the agent can begin with a more informed strategy, effectively reducing the need for random exploration and improving sample efficiency. This fusion allows agents to generalize more effectively to unseen scenarios, as the LLM provides a robust foundation for interpreting and responding to novel situations.
The integration of large language models into reinforcement learning extends beyond simple task completion, offering mechanisms to directly influence the learning process itself. These models aren’t merely providing data; they’re actively shaping the agent’s understanding of success. Through reward synthesis, LLMs can generate nuanced reward signals beyond basic metrics, encouraging behaviors aligned with human expectations or complex goals. Furthermore, preference learning allows agents to discern optimal actions by learning from LLM-articulated preferences, bypassing the need for explicitly defined reward functions. Crucially, LLMs also serve as powerful exploration guides, suggesting promising avenues for the agent to investigate, thereby accelerating learning and improving sample efficiency. This dynamic interplay enables the creation of agents that are not only proficient at solving tasks, but also demonstrate a level of adaptability and intelligence previously unattainable.
The convergence of large language models and reinforcement learning heralds a new era in artificial intelligence, fostering agents demonstrably more capable of tackling intricate challenges. By leveraging the contextual understanding and reasoning abilities of LLMs, these agents move beyond traditional trial-and-error learning, exhibiting enhanced generalization and adaptability. This synergistic approach allows for the creation of systems that not only master specific tasks but also exhibit a degree of common sense reasoning and the capacity to navigate unforeseen circumstances. Consequently, the potential applications span a broad spectrum, from robotics and game playing to complex decision-making processes in fields like finance and healthcare, promising a future where AI systems can operate with greater autonomy and intelligence.
The pursuit of robust robotic learning, as demonstrated in this work with SigEnt-SAC, necessitates a rigorous approach to algorithmic design. The framework’s emphasis on sample efficiency and conservative Q-learning echoes a fundamental tenet of mathematical elegance: achieving maximal results with minimal assumptions. As Ken Thompson aptly stated, “Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it.” This sentiment underscores the importance of provable correctness and simplicity; a needlessly complex algorithm, even if functionally achieving the desired outcome, lacks the inherent beauty and reliability of a solution built upon sound mathematical principles, much like the framework’s goal of generalizing from limited demonstrations.
What Lies Ahead?
The presented framework, while demonstrating a commendable advance in sample efficiency, merely addresses the symptoms of a deeper malaise within reinforcement learning. The reliance on a single demonstration, even when augmented with entropy regularization, exposes a fundamental fragility. True generality demands algorithms capable of distilling knowledge from imperfect, incomplete, and even contradictory data – a capacity currently absent. The sigmoid-bounded entropy offers a pragmatic constraint, but lacks the mathematical elegance of a solution derived from first principles. It works, yes, but what does it mean?
Future efforts should not focus solely on incremental improvements to existing actor-critic architectures. Instead, a re-evaluation of the underlying assumptions regarding reward function specification and state representation is necessary. The current paradigm, predicated on precisely defined objectives, proves inadequate for the messiness of real-world robotics. An algorithm that can infer the intent behind a demonstration, rather than simply mimic it, would represent a genuine leap forward. This demands a shift towards methods capable of building internal models of the environment, validated not by empirical performance, but by logical consistency.
Ultimately, the pursuit of robust and adaptable robotic intelligence requires a rejection of purely empirical approaches. The field must embrace a more rigorous, mathematically grounded methodology – one where elegance and provability are valued above all else. Only then can it escape the cycle of ad-hoc solutions and achieve a truly general intelligence, rather than a sophisticated pattern-matching engine.
Original article: https://arxiv.org/pdf/2601.15761.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-01-24 22:15