Author: Denis Avetisyan
A new analysis reveals that translating natural language into executable Python code, while comparable to SQL generation, demands greater logical completeness and highlights critical challenges in ambiguity resolution for large language models.
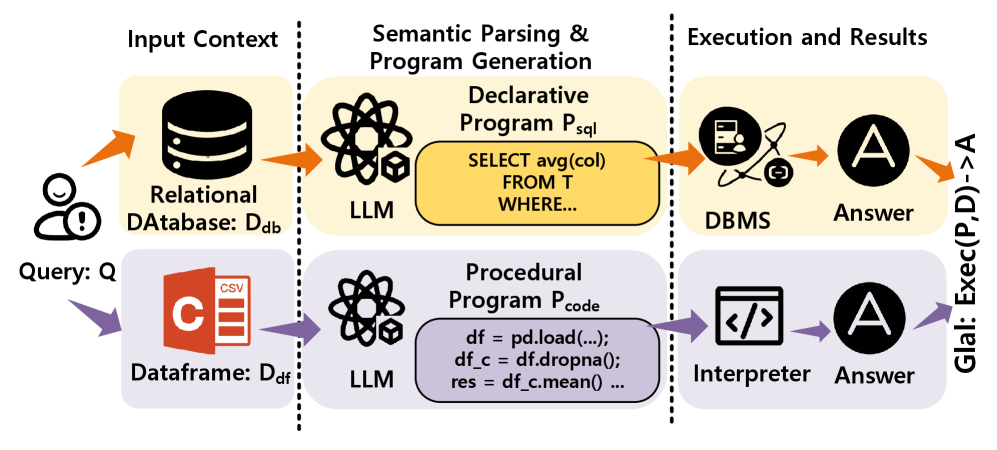
Benchmarking Text-to-Python against Text-to-SQL demonstrates the impact of explicit logic requirements and the benefits of context completion for both paradigms.
While Text-to-SQL remains the established paradigm for database interaction, increasingly complex analytical tasks demand the flexibility of general-purpose programming languages like Python. This need motivates ‘Benchmarking Text-to-Python against Text-to-SQL: The Impact of Explicit Logic and Ambiguity’, which introduces a new benchmark and reveals a fundamental divergence: Python’s reliance on explicit procedural logic makes it uniquely sensitive to underspecified user intent compared to SQL’s implicit behaviors. Our analysis demonstrates that performance gaps stem primarily from missing domain context, and that addressing this through logic completion enables Text-to-Python to achieve parity with Text-to-SQL. Does this suggest that grounding natural language in executable logical specifications is key to unlocking the full potential of Python as a foundation for robust analytical agents?
The Persistent Challenge of Natural Language Understanding
Even with the rapid evolution of Large Language Models, converting everyday language into precise, executable commands presents a persistent challenge. While LLMs demonstrate impressive abilities in generating human-like text, their capacity to reliably understand nuanced requests and translate them into functional instructions remains imperfect. The core issue isn’t simply a lack of vocabulary, but a difficulty in discerning the intended meaning behind ambiguous phrasing, implicit assumptions, and the vast background knowledge humans naturally employ. Consequently, systems relying on natural language input – from automated data analysis to robotic control – often require extensive error correction or operate within severely constrained domains, highlighting a crucial gap between linguistic fluency and true comprehension.
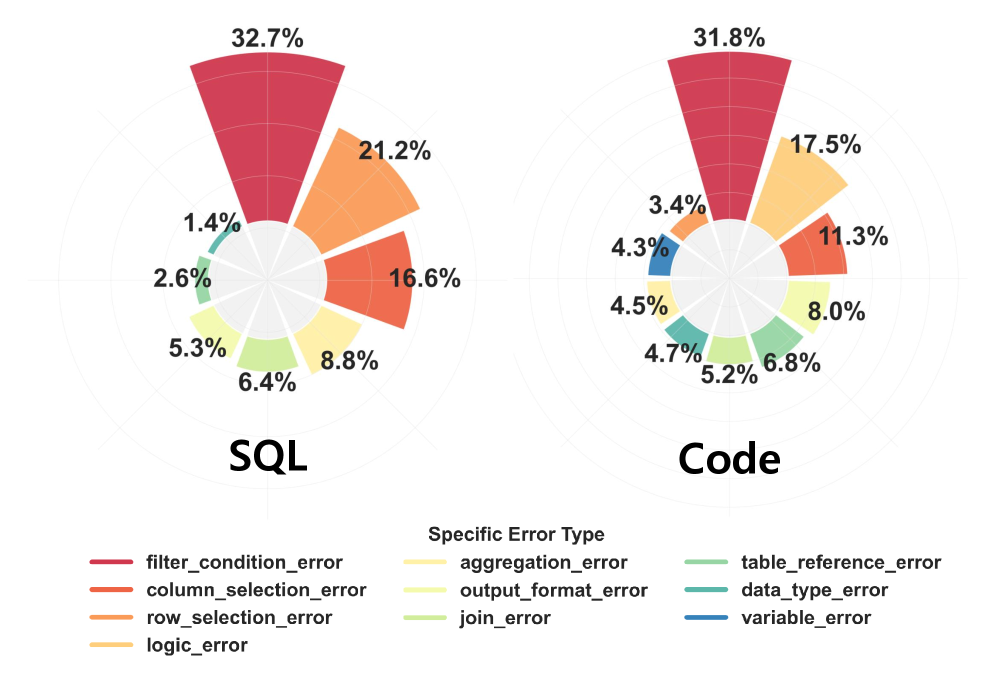
The inherent subtleties of human language often present obstacles for automated systems attempting to convert natural language into actionable code. Text-to-SQL and Text-to-Python programs, while increasingly sophisticated, frequently stumble when faced with ambiguous constraints or gaps in their knowledge base. A seemingly simple request, such as “Find the average salary,” requires the system to infer details – which employees, over what time period, and how to handle missing data – which are not explicitly stated. These implicit assumptions, easily understood by a human, become points of failure for machines lacking common sense reasoning or access to comprehensive contextual information. Consequently, inaccuracies arise not from flaws in the core programming, but from misinterpretations stemming from incomplete understanding, significantly limiting the reliability and practical application of these systems.
Closing the chasm between human communication and machine action necessitates more than simply processing words; it demands a nuanced comprehension of underlying intent. Current systems often stumble not because of linguistic errors, but because they fail to grasp the purpose behind a request – the implicit goals and contextual knowledge a human effortlessly employs. Achieving true natural language understanding, therefore, requires innovative approaches that move beyond pattern recognition to incorporate reasoning, common sense, and the ability to disambiguate based on real-world knowledge. This involves developing models capable of inferring unstated assumptions, resolving ambiguities through contextual awareness, and ultimately translating vague human directives into precise, executable instructions – a feat demanding a fundamental shift in how machines ‘understand’ language.
From Structured Data to Flexible File-Based Processing
Traditional Text-to-SQL systems function by converting natural language questions into SQL queries that can be executed against a relational database. This process fundamentally depends on Schema Linking, where the system identifies and connects the entities and attributes mentioned in the query to the corresponding tables and columns in the database schema. Accurate schema linking is critical; the system must correctly interpret the user’s intent and map it to the database structure to generate a valid and accurate SQL query. These systems typically achieve high performance and accuracy when dealing with well-defined and consistently structured data because the schema provides a clear and unambiguous definition of the data’s organization and relationships. The reliance on schema linking means these systems are less adaptable to unstructured or semi-structured data formats.
Unlike structured databases, real-world data frequently exists in file-based formats such as CSV, JSON, or TXT. Processing this data with natural language requires a transition from Text-to-SQL, which relies on predefined schemas, to Text-to-Python. This shift introduces the need for Explicit Procedural Logic; the system must generate Python code that explicitly defines the steps for file access, data parsing, and manipulation. This contrasts with SQL, where the database engine handles these processes implicitly based on the schema. Consequently, Text-to-Python systems must translate a natural language query into a sequence of Python commands that perform these procedural tasks before data analysis can occur.
Text-to-Python systems gain their analytical capability through integration with libraries such as Pandas, which allows for the creation and manipulation of DataFrames – tabular data structures optimized for processing and analysis. Performance metrics demonstrate that Text-to-Python can achieve results comparable to traditional Text-to-SQL approaches when provided with adequate contextual information; however, unlike schema-linked SQL queries, Text-to-Python relies on procedural logic and is therefore more susceptible to errors or failures when encountering incomplete or missing information regarding data formats, expected values, or required processing steps.

Assessing True Understanding: Beyond Simple Execution
Traditional metrics for evaluating Text-to-SQL and Text-to-Python systems, such as code compilation and successful program termination, are insufficient indicators of true performance. Execution Accuracy (EX) provides a more robust assessment by verifying that the generated code not only runs but also produces the correct output according to the input question and underlying data. This necessitates evaluating the semantic correctness of the generated code, moving beyond syntactic validation. EX is therefore a critical benchmark for comparing system performance and identifying areas where code generation needs improvement, as it directly correlates to the usability and reliability of these systems in real-world applications.
The BIRD (Benchmark for Instruction-following, Reasoning, and Data manipulation) benchmark offers a standardized evaluation methodology for Text-to-SQL and Text-to-Python systems, facilitating comparative performance analysis and pinpointing specific areas requiring improvement. This benchmark assesses Execution Accuracy (EX), which measures the correctness of code execution beyond simply verifying if the code runs without errors. As of recent evaluations, Qwen3-Max currently achieves an EX score of 63.43% on the BIRD benchmark, representing a marginal improvement over DeepSeek-R1’s score of 62.52%. These scores provide a quantitative basis for tracking progress and comparing the capabilities of different models in complex data manipulation tasks.
Data Consistency is a fundamental requirement for high Execution Accuracy in Text-to-SQL and Text-to-Python systems. This refers to the ability of the generated code to correctly identify, access, and manipulate the specific data intended by the natural language query. Failures in data consistency manifest as incorrect results, even if the code executes without errors; for instance, a query intending to aggregate sales for a specific product might instead aggregate data across all products due to improper filtering. Achieving data consistency necessitates accurate schema understanding, correct column name resolution, and appropriate handling of data types and relationships within the underlying database or data source. Consistent data interpretation is therefore a primary factor in evaluating the reliability and trustworthiness of these systems.
Augmenting Reasoning with Logic Completion
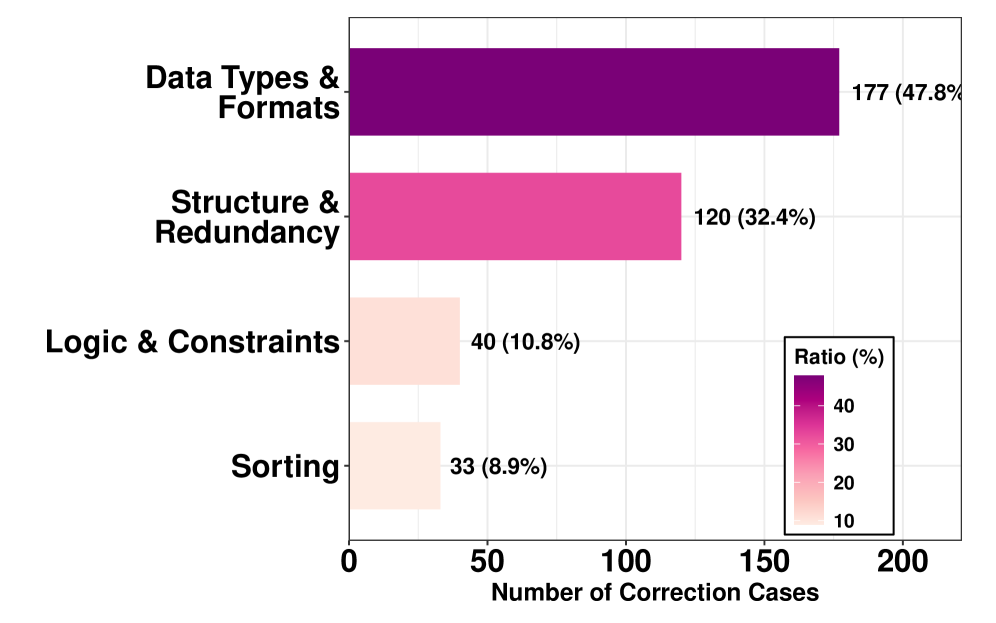
The Logic Completion Framework (LCF) represents a notable step forward in addressing a critical limitation of current Natural Language Interfaces: knowledge gaps. Many Text-to-SQL and Text-to-Python systems struggle when interpreting ambiguous requests or lacking specific domain expertise. LCF tackles this by proactively supplementing the system’s latent knowledge, effectively ‘completing the logic’ needed to accurately translate natural language into executable code. This isn’t simply about providing more data; it’s about enhancing the system’s reasoning capabilities, allowing it to infer missing information and generate more reliable instructions. The framework functions as a bridge, connecting user intent with precise code execution, and demonstrably improves performance across various models, suggesting a valuable pathway for building more robust and intuitive human-computer interactions.
The Logic Completion Framework (LCF) addresses a critical limitation in current Natural Language Interfaces – the reliance on pre-existing knowledge. It actively bolsters a system’s understanding by supplying missing domain information, enabling it to decipher vague requests and construct dependable execution instructions. Empirical evidence demonstrates LCF’s effectiveness; integrating the framework with the Qwen3-7B model resulted in a substantial performance leap, from 53.19% to 71.19%. Further testing with the Qwen3-Max model revealed a consistent improvement of approximately 9 percentage points, showcasing LCF’s broad applicability and potential for markedly enhancing the precision of language-driven systems.
The Logic Completion Framework signals a considerable leap forward for Natural Language Interfaces, promising more seamless and effective communication between humans and computers. Recent studies demonstrate its capacity to bridge the gap in understanding ambiguous requests, culminating in performance levels that rival established systems; notably, the Qwen3-32B model, enhanced with this framework, attains an accuracy of 72.49%, a figure comparable to the performance of traditional SQL systems at 72.75%. This achievement suggests that LCF isn’t simply improving existing models, but fundamentally altering the trajectory of NLI research, potentially unlocking a future where interacting with machines feels truly intuitive and natural.
![The Logic Completion Framework (LCF) enhances semantic parsing by explicitly incorporating latent domain knowledge as logic clarifications, refining the probability estimation of a program [latex]P[/latex] given a query [latex]Q[/latex] and knowledge sources [latex]\mathcal{S}[/latex], [latex]\mathcal{K}[/latex].](https://arxiv.org/html/2601.15728v1/x5.png)
The study illuminates how systems, even those built upon sophisticated large language models, reveal their weaknesses at boundaries – specifically, when confronted with incomplete information. This echoes G.H. Hardy’s assertion: “A mathematician, like a painter or a poet, is a maker of patterns.” The elegance of a functional system, much like a beautiful mathematical proof, relies on a complete and logically sound foundation. The paper demonstrates that Text-to-Python, demanding explicit logic, suffers disproportionately from missing context, highlighting how the perceived strength of a system – its precision – becomes its vulnerability when faced with ambiguity. Addressing this through context completion isn’t merely patching a flaw, but strengthening the foundational pattern itself.
Future Directions
The observed sensitivity of Text-to-Python, stemming from its demand for explicit procedural logic, suggests a fundamental constraint on natural language interfaces to computation. The system isn’t merely translating intent; it’s reconstructing a complete, internally consistent algorithm from potentially incomplete input. Text-to-SQL, benefiting from the inherent structure of relational databases, enjoys a degree of implicit completion. Future work must therefore concentrate on methods for robust context completion – not simply filling in missing data, but inferring logical connections. The elegance of a solution will not reside in larger models, but in more insightful methods for disambiguation.
Scalability will not be achieved through brute force. A system that requires exponentially more parameters to handle increasing ambiguity is, by definition, fragile. A more promising avenue lies in developing architectures that prioritize structural integrity – systems that actively seek the simplest, most coherent interpretation, even if it necessitates questioning the initial prompt. This necessitates moving beyond purely generative models toward systems capable of active inquiry and hypothesis testing.
Ultimately, the challenge is not to build machines that answer questions, but machines that understand what is being asked – and, crucially, recognize what remains unsaid. The ecosystem of language and computation demands a holistic approach; patching one component will not fix a fundamentally flawed design. The true metric of success will be measured not in benchmark scores, but in the graceful handling of uncertainty.
Original article: https://arxiv.org/pdf/2601.15728.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-01-24 20:34