Author: Denis Avetisyan
A new framework aims to improve the reliability of AI-powered research assistants by automatically verifying their work and adapting to failures.
This paper introduces DeepVerifier, a system for scaling verification at inference time, enabling self-evolving deep research agents with both closed-source and open-source language models.
Despite advances in automated reasoning, Deep Research Agents (DRAs) often struggle with reliability and self-correction-a limitation addressed in our work, ‘Inference-Time Scaling of Verification: Self-Evolving Deep Research Agents via Test-Time Rubric-Guided Verification’. We introduce DeepVerifier, a framework that enables DRAs to iteratively refine their outputs through test-time verification guided by a detailed, automatically-constructed failure taxonomy. This approach delivers performance gains-up to 11% accuracy on challenging benchmarks-by leveraging rubric-based feedback without requiring additional training, and is further enhanced with a curated dataset, DeepVerifier-4K, for open-source model fine-tuning. Can this paradigm of inference-time self-evolution unlock a new level of robustness and trustworthiness in autonomous knowledge discovery systems?
The Inevitable Errors of Automated Thought
Deep Research Agents (DRAs) represent a significant leap in automated knowledge discovery, leveraging the power of Large Language Models and Vision-Language Models to perform complex tasks previously requiring human intellect. However, this potential is tempered by a notable susceptibility to errors. While capable of synthesizing information and identifying patterns, DRAs can stumble in nuanced reasoning, misinterpret visual data, or fabricate details – particularly when confronted with ambiguous or incomplete information. This inherent fallibility doesn’t negate their value, but it underscores a critical challenge: ensuring the reliability of outputs is paramount to prevent the propagation of inaccuracies and maintain trust in these increasingly sophisticated systems. The promise of DRAs lies not just in their ability to process vast datasets, but in their capacity to do so accurately, a goal demanding innovative approaches to verification and error mitigation.
Assessing the outputs of Deep Research Agents (DRAs) presents a significant challenge due to the complexity of their tasks and the nuanced nature of knowledge itself. Conventional evaluation techniques, often relying on simple metric matching or human annotation of limited samples, frequently fail to capture subtle errors or inconsistencies that a DRA might introduce during information synthesis. This creates a critical bottleneck in automated knowledge discovery, as verifying the accuracy and reliability of DRA-generated insights requires substantial human effort – effectively negating the potential for true automation. The difficulty isn’t merely identifying incorrect statements, but also discerning whether a DRA has appropriately contextualized information, drawn valid inferences, or avoided subtle forms of bias – tasks demanding sophisticated reasoning that current automated methods struggle to replicate. Consequently, scaling DRA applications hinges on developing innovative evaluation strategies capable of moving beyond superficial checks and providing robust guarantees of output quality.
The practical deployment of Deep Research Agents (DRAs) hinges critically on their reliability, and without dependable verification methods, both trustworthiness and scalability remain significant obstacles. Current DRAs, while adept at processing information, can generate inaccuracies or confidently present unsubstantiated claims, effectively undermining the value of automated knowledge discovery. A lack of robust checks not only erodes confidence in DRA outputs – potentially leading to flawed decision-making – but also prevents these agents from handling increasingly complex tasks or expanding to larger datasets. Consequently, the ability to definitively assess the validity of DRA-generated insights is not merely a technical refinement, but a foundational requirement for realizing the full potential of this emerging technology and ensuring its responsible integration into critical workflows.
Shifting the Burden: Verification as the Easier Problem
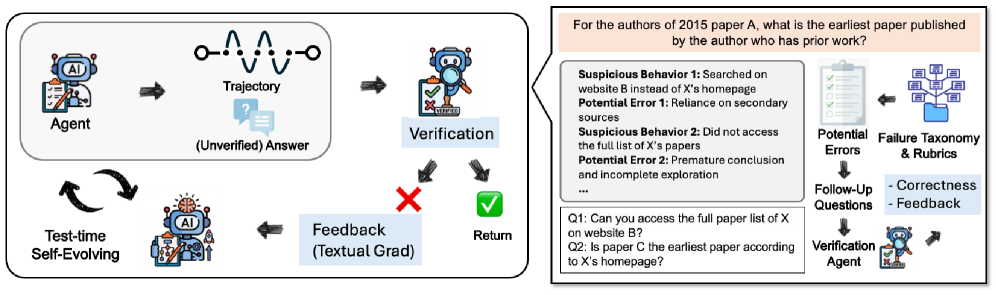
DeepVerifier implements an agentic pipeline for automated verification of outputs generated by a Decision-making Reasoning Agent (DRA). This approach is predicated on the observation that evaluating the correctness of a proposed solution – verification – generally requires less computational effort and complexity than generating that solution from scratch. The pipeline leverages this asymmetry by shifting the focus from complex generative modeling to a more tractable verification task, enabling efficient assessment of DRA performance and identification of potential errors. The agentic nature of the pipeline suggests a modular design where distinct agents are responsible for specific verification sub-tasks, potentially allowing for parallel processing and scalability.
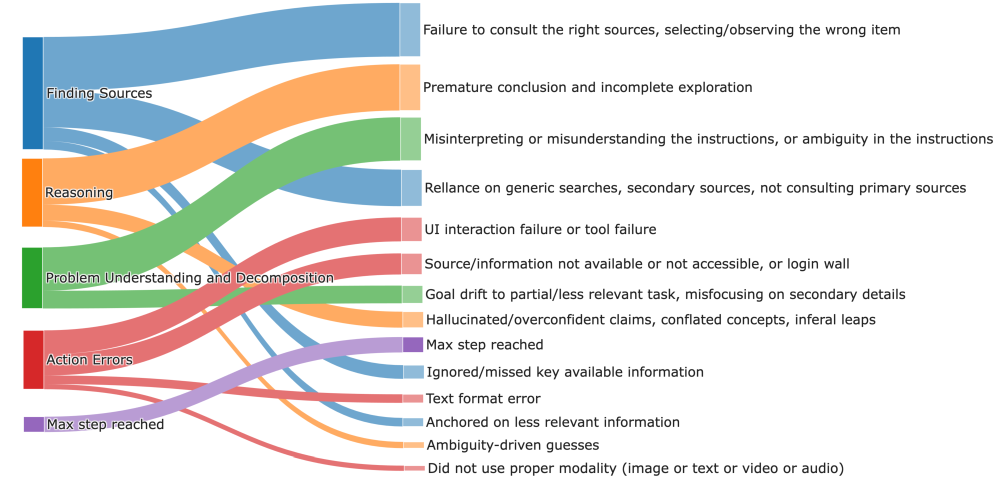
DeepVerifier utilizes a DRA Failure Taxonomy to systematically categorize common errors present in outputs generated by the DRA (Data Reasoning Agent). This taxonomy defines specific failure modes, such as factual inaccuracies, logical fallacies, and unsupported claims, enabling the system to pinpoint the type of error occurring. By classifying errors in this structured manner, DeepVerifier moves beyond simple binary correctness assessments and can provide targeted feedback to the DRA, indicating precisely where and how its reasoning failed. The taxonomy is not merely a labeling scheme; it serves as the foundation for rubrics-based rewards, directing the verification process towards identifying and characterizing these specific failure types.
Rubrics-based rewards in DeepVerifier utilize a pre-defined DRA Failure Taxonomy to assign scalar values to verification assessments. These rewards function as discriminative signals, providing granular feedback to the verification agent based on the identified error type and severity. Instead of a simple binary correctness judgment, the system evaluates outputs according to specific failure modes – such as factual inaccuracy, logical inconsistency, or lack of coherence – and assigns a reward value accordingly. This allows the verification agent to learn which error types are most critical and refine its assessment capabilities, leading to more effective and targeted feedback during the DRA training process. The reward magnitude is directly correlated to the significance of the identified failure, encouraging the agent to prioritize high-impact errors.
Data, Data Everywhere: Fueling the Verification Engine
The DeepVerifier-4K dataset is a curated collection of 4,000 prompt-response pairs specifically designed for supervised fine-tuning of the DeepVerifier verification model. Each pair consists of a user prompt and a corresponding response, meticulously evaluated and labeled to provide ground truth for training. This dataset’s construction prioritized diversity in prompt types and response complexity to enhance the model’s generalization capability. The prompts cover a range of topics and question formats, while the responses vary in length and factual accuracy, enabling the model to learn nuanced verification criteria. The dataset is formatted to facilitate efficient training and evaluation of the verification model, providing a robust foundation for improving its performance.
DeepVerifier-8B represents a substantial advancement over prior models due to supervised fine-tuning on the DeepVerifier-4K dataset. This process resulted in a measurable 5.5% increase in verification accuracy. The improvement is attributable to the model’s enhanced ability to discern nuanced differences in prompt-response pairs, moving beyond simple keyword matching to assess contextual relevance and logical consistency. Quantitative evaluation, conducted using a held-out test set, confirms the statistically significant performance gain achieved with DeepVerifier-8B compared to its predecessors.
DeepVerifier’s operational structure is predicated on a three-module system. The Decomposition Module initially breaks down complex input claims into a series of atomic statements. These statements are then processed by the Verification Module, which leverages external knowledge sources to assess the truthfulness of each atomic claim. Finally, the Judge Module synthesizes the individual verification results from the Verification Module to produce a holistic judgment regarding the original claim’s overall veracity. This modular design enables focused development and facilitates the identification and mitigation of errors within specific components of the verification process.
Putting It All Together: A Modest Improvement, Reliably Measured
DeepVerifier demonstrates a significant advancement in evaluating the outputs of Decision Reasoning Agents (DRAs) through comprehensive testing with the GAIA benchmark. This evaluation suite rigorously assesses DRA performance across a broad spectrum of cognitive tasks, including complex reasoning, multimodal data processing, and information retrieval via web browsing. Results indicate that integrating DeepVerifier into existing DRA systems yields a substantial improvement in overall accuracy, elevating performance from 52% to 59%. This gain highlights DeepVerifier’s capacity to reliably distinguish between correct and incorrect DRA outputs, ultimately bolstering the trustworthiness and efficacy of these increasingly complex AI systems.
DeepVerifier’s seamless integration with Cognitive Kernel-Pro demonstrates its adaptability and broad applicability within the dynamic field of decision-making AI. This compatibility isn’t merely technical; it highlights DeepVerifier’s design as a modular component readily incorporated into existing, state-of-the-art DRA frameworks without requiring substantial architectural modifications. By functioning harmoniously with Cognitive Kernel-Pro, DeepVerifier effectively validates the outputs of complex reasoning processes, enhancing the reliability and trustworthiness of these advanced AI systems. This collaborative potential underscores DeepVerifier’s value not as a standalone tool, but as a crucial enabler for building more robust and dependable DRA applications.
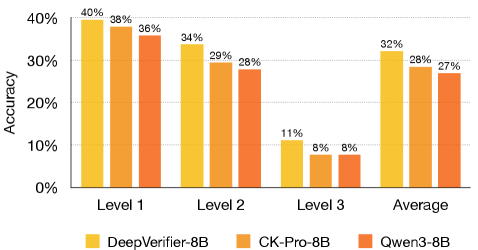
DeepVerifier’s performance during the crucial inference stage benefits significantly from the implementation of techniques like Test-Time Scaling and a Reflective Feedback Loop. These methods demonstrably enhance the system’s ability to validate outputs from complex reasoning systems, yielding up to an 8% improvement in accuracy when assessed against the GAIA dataset. Furthermore, benchmarks such as BrowseComp reveal accuracy gains ranging from 5.0% to 10.0% through the utilization of these techniques. The enhancements extend to more specialized tasks; evaluations on XBench-DeepSearch show a notable accuracy increase from 41.0% to 47.0%, coupled with substantial improvements in the F1 score-ranging from 12% to 48%-during meta-evaluation, indicating a robust and versatile validation capability.
The pursuit of robust Deep Research Agents, as outlined in this work, feels predictably circular. DeepVerifier attempts to instill reliability through automated feedback and test-time scaling, yet one suspects each layer of verification simply introduces a new class of failure. It’s a constant escalation, much like chasing performance gains with increasingly complex caching strategies. Ada Lovelace observed that “The Analytical Engine has no pretensions whatever to originate anything.” This feels acutely relevant; DeepVerifier doesn’t create trustworthiness, it attempts to meticulously detect its absence – a fundamentally reactive stance. The framework’s reliance on failure taxonomies simply formalizes the inevitable: production will always find a way to expose the limitations of even the most carefully constructed systems. Everything new is just the old thing with worse docs.
What’s Next?
The pursuit of self-verifying agents inevitably reveals a deeper truth: the bug tracker is merely a more sophisticated form of the oracle. This work, while presenting a method for automated failure analysis, doesn’t solve reliability-it externalizes the cost. The taxonomy of failures, however meticulously constructed, will always lag behind the ingenuity of production environments. The system will find novel ways to disappoint.
The scaling of verification at test-time, while promising, highlights the core issue: verification isn’t a feature, it’s a tax. Every automated check introduces latency, consumes resources, and generates false positives-a cost willingly borne in exchange for a marginal decrease in spectacular failures. The question isn’t whether DeepVerifier improves reliability, but whether the improvement justifies the added complexity.
The eventual fate of these ‘self-evolving’ agents is predictable. They will become another layer of abstraction, a new form of technical debt. The promise of automated feedback loops glosses over the fact that feedback, without human judgment, is simply noise. They don’t deploy-they let go.
Original article: https://arxiv.org/pdf/2601.15808.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-01-24 17:20