Author: Denis Avetisyan
A new diffusion model elegantly blends multiple images into cohesive scenes, achieving state-of-the-art performance in both image editing and complex composition tasks.
Skywork UniPic 3.0 leverages sequence modeling and a carefully curated dataset to achieve high-quality multi-image composition and single-image manipulation.
Achieving consistent, high-quality results remains a significant challenge in multi-image composition despite growing community interest in the task. This paper introduces ‘Skywork UniPic 3.0: Unified Multi-Image Composition via Sequence Modeling’, a novel framework that unifies single-image editing and multi-image composition through a sequence modeling paradigm. By leveraging a carefully curated dataset and efficient post-training techniques-including trajectory mapping and distribution matching-UniPic 3.0 achieves state-of-the-art performance, surpassing existing models like Nano-Banana and Seedream 4.0. Could this approach unlock new possibilities for creative image manipulation and generation, particularly in scenarios demanding complex scene synthesis?
The Illusion of Coherence: Why We Chase Seamless Synthesis
The pursuit of photorealistic image synthesis from disparate sources presents a formidable hurdle in computer vision. While algorithms excel at generating individual elements, seamlessly integrating them into a convincingly unified scene proves remarkably difficult. Current techniques frequently falter when tasked with establishing logical relationships-a chair inexplicably floating mid-air, or shadows defying light sources-exposing a critical gap between generating components and constructing a coherent whole. This challenge stems from the inherent complexity of visual information; real-world scenes aren’t simply collections of objects, but intricate arrangements governed by physical laws, contextual understanding, and subtle cues that demand a nuanced approach to image creation. Consequently, achieving truly believable imagery necessitates advancements beyond mere object recognition, requiring systems capable of infering scene structure and enforcing visual plausibility.
Current image composition techniques frequently falter when striving for believable and logically sound scenes. While capable of stitching together elements from various sources, these methods often produce outputs where objects clash in terms of lighting, scale, or even basic physical laws. A key issue lies in the difficulty of ensuring semantic consistency – that the relationships between objects make sense given their identities and the broader context. For instance, a system might place a shadow incorrectly, or depict a person’s hand passing through a solid object. Generating plausible interactions – like a natural-looking reflection or a convincing overlap between objects – proves particularly challenging, requiring a nuanced understanding of physics and spatial reasoning that remains elusive for many algorithms. These limitations highlight the need for more sophisticated approaches that move beyond simply combining images to genuinely understanding and synthesizing visual scenes.
Real-world visual scenes aren’t collections of isolated objects, but intricate webs of relationships – spatial arrangements, physical interactions, and semantic connections that define plausibility. Consequently, effectively composing coherent images requires more than simply stitching together elements; it necessitates a computational framework capable of discerning and synthesizing these complex relationships. Current approaches often falter because they treat composition as a surface-level problem, overlooking the underlying structure that governs how objects relate to one another and to the scene as a whole. A robust solution demands a system that can not only identify these relationships – such as support, containment, or occlusion – but also leverage them to generate visually consistent and believable imagery, mirroring the inherent complexity of natural environments.

UniPic 3.0: A Diffusion-Based Attempt at Control
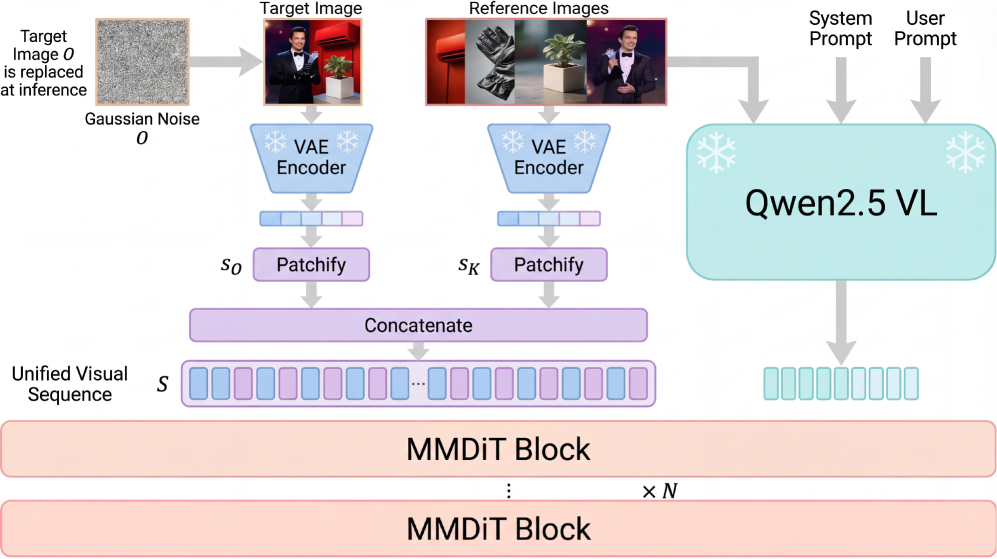
Skywork UniPic 3.0’s architecture integrates diffusion models – generative models that create data by reversing a diffusion process – with sequence modeling techniques. This combination allows the system to generate images conditioned on diverse inputs represented as sequential data. The diffusion model component is responsible for the image generation process, while the sequence modeling component processes and incorporates the input conditions, enabling control over the generated content. This hybrid approach differs from traditional diffusion models by providing a mechanism to effectively manage and utilize complex, multi-faceted input conditions, ultimately enhancing the controllability and flexibility of the image generation process.
Skywork UniPic 3.0 employs the MMDiT (Multimodal Deep Information Transformer) backbone for foundational feature extraction from various input modalities. This is coupled with the Qwen2.5-VL condition encoder, a vision-language model, to process and encode diverse input conditions – including text prompts, layout specifications, and reference images – into a unified embedding space. The Qwen2.5-VL encoder specifically translates visual and textual information into a shared latent representation, allowing the framework to effectively integrate these disparate conditions and guide the image generation process. This combined approach ensures that the system can accurately interpret and synthesize complex user inputs, resulting in images that adhere to the specified constraints and desired aesthetic.
The Skywork UniPic 3.0 framework achieves a unified scene representation by concatenating latent variables derived from various input conditions into a single sequential input for subsequent processing. This concatenation allows the system to model the relationships between different scene elements as dependencies within a sequence, effectively establishing a coherent understanding of the combined scene. This sequential representation is then processed using sequence modeling techniques, enabling the framework to generate outputs consistent with the integrated scene description, rather than treating each input condition in isolation.
The Usual Suspects: Distillation, Consistency, and a Dash of Magic
Skywork UniPic 3.0 leverages distribution matching as a knowledge distillation technique to transfer capabilities from a larger, more complex teacher model to a smaller, more efficient student model. This process focuses on aligning the output distributions of the student model with those of the teacher, rather than simply replicating the teacher’s parameters. By minimizing the divergence between these distributions, the student model learns to generate outputs that are statistically similar to the teacher, effectively inheriting its knowledge while requiring fewer computational resources. This is achieved through iterative refinement of the student model’s parameters based on the difference between its output distribution and the teacher’s, resulting in a compressed model capable of performing comparably to its larger counterpart.
Trajectory Mapping addresses the challenge of knowledge transfer from a teacher to a student diffusion model by explicitly modeling the noise-to-data trajectory. Traditional distillation methods often struggle with accurately replicating the complex mapping learned by larger models; however, Trajectory Mapping focuses on transferring this trajectory directly. This is achieved by learning a function that predicts the data point corresponding to a given noise level and time step, effectively replicating the teacher model’s denoising process. By accurately transferring this trajectory, the student model can achieve high-fidelity generation comparable to the teacher, despite having significantly fewer parameters, and is less susceptible to issues caused by discrepancies in the noise schedules of the teacher and student models.
Consistency Models (CMs) address training instability and complexity in generative models by reformulating the denoising score matching objective as a non-probabilistic, deterministic mapping from noisy data to the original data distribution. This is achieved through techniques like Flow Matching (FM) and TrigFlow, which define a continuous normalizing flow to model this mapping. FM utilizes a time-dependent vector field to guide the denoising process, while TrigFlow employs trigonometric functions to create a more stable and efficient flow. By framing the task as a deterministic process, CMs eliminate the need for Markovian assumptions and variational lower bounds, simplifying the training procedure and improving the robustness of the generative model.
Classifier-Free Guidance (CFG) enhances image quality during distribution matching by enabling control over the sampling process without requiring a separate classifier. Instead of training a dedicated classifier to guide generation, CFG leverages a single conditional diffusion model trained with both labeled and unlabeled data. During inference, the model is prompted with both the conditional input (e.g., text prompt) and a null input, and the difference between the resulting outputs is used to steer the generation towards more realistic and higher-quality images. This approach effectively adjusts the generation process based on the conditional information, improving sample fidelity and adherence to the desired characteristics without the computational overhead of a separate classifier.

The Illusion of Progress: Benchmarking in a Field of Smoke and Mirrors
A significant challenge in advancing multi-image composition lies in the lack of dedicated evaluation metrics; existing benchmarks often fall short when assessing models tasked with seamlessly blending multiple images, particularly those depicting human-object interactions (HOI). To address this, researchers have introduced MultiCom-Bench, a novel benchmark specifically engineered for rigorous evaluation of these models. This new standard moves beyond simple image quality assessments by focusing on the fidelity and coherence of composed scenes, with a strong emphasis on accurately representing relationships between people and objects within the generated imagery. By providing a targeted and challenging dataset, MultiCom-Bench aims to accelerate progress in the field and facilitate the development of more sophisticated and realistic image composition technologies.
Evaluations using the newly developed MultiCom-Bench benchmark reveal that Skywork UniPic 3.0 consistently achieves superior performance when compared to leading commercial multi-image composition systems. UniPic 3.0 attained an overall score of 0.7255, demonstrably exceeding the capabilities of both Nano-Banana and Seedream 4.0 in complex human-object interaction scenarios. This result highlights UniPic 3.0’s advanced ability to synthesize coherent and realistic imagery from multiple source images, suggesting a step forward in the field of generative models and their potential for applications requiring sophisticated image manipulation and creation.
Evaluations utilizing the MultiCom-Bench benchmark reveal a significant performance advantage for Skywork UniPic 3.0 in complex compositional scenarios. When tasked with combining two or three source images into a cohesive scene, UniPic 3.0 achieves a score of 0.8214, demonstrably exceeding the capabilities of leading commercial systems. This represents an improvement over both Seedream 4.0, which attained a score of 0.7997 in the same conditions, and Nano-Banana, which registered a score of 0.7982. These results highlight UniPic 3.0’s enhanced ability to synthesize realistic and semantically accurate imagery from multiple inputs, particularly in scenarios demanding intricate visual relationships and coherent scene construction.
Beyond its capabilities in multi-image composition, the UniPic 3.0 framework exhibits robust performance in single-image editing tasks, as evidenced by its scores on established benchmarks. Achieving 4.35 on ImgEdit-Bench and 7.55 on GEdit-Bench, UniPic 3.0 demonstrates a capacity for precise and nuanced image manipulation. These results indicate the framework isn’t solely focused on combining multiple sources, but also excels at refining and altering existing images with a high degree of fidelity and control, suggesting broad applicability in image enhancement and creative editing workflows.
The efficiency of UniPic 3.0 is particularly noteworthy, as the framework consistently produces high-fidelity images with remarkably few computational steps – only eight inference steps are required to achieve compelling results. This speed differentiates it from many contemporary multi-image composition models, which often demand significantly more processing to generate comparable outputs. Such efficiency not only reduces computational costs but also opens doors for real-time applications and interactive content creation, making complex image synthesis more accessible and practical across various platforms and devices. The ability to rapidly generate detailed, coherent scenes with minimal processing represents an advancement in the field of generative AI.
The framework demonstrably excels at synthesizing images from multiple input sources, producing outputs characterized by a high degree of realism, visual coherence, and semantic accuracy. This capability extends beyond simply combining images; the system intelligently interprets the relationships between objects and scenes, ensuring that the generated composite maintains logical consistency and believable interactions. Evaluations reveal a nuanced understanding of spatial arrangements, lighting conditions, and object properties, culminating in images that appear not merely assembled, but genuinely integrated. This achievement signifies a leap forward in multi-image composition, offering the potential to create complex visual narratives and immersive experiences with a level of fidelity previously unattainable.
The enhanced capabilities in multi-image composition, as demonstrated by frameworks like Skywork UniPic 3.0, are poised to significantly impact several rapidly evolving fields. Virtual reality experiences stand to gain from the seamless integration of diverse visual elements, creating more immersive and believable environments. Augmented reality applications will benefit from the ability to realistically composite virtual objects into real-world scenes, enhancing user interaction and information delivery. Perhaps most immediately, the content creation landscape will be transformed, empowering artists and designers with tools to generate complex and visually stunning imagery with greater efficiency and control, ultimately streamlining workflows and unlocking new creative possibilities.
The pursuit of seamless multi-image composition, as demonstrated by Skywork UniPic 3.0, feels predictably ambitious. It’s a carefully constructed system, leveraging sequence modeling and meticulously curated data – all in the service of generating plausible scenes. One anticipates the inevitable entropy. As Geoffrey Hinton once observed, “The best way to program an AI is to start with something really simple and then add features.” This elegantly captures the cycle; each added ‘feature’ introduces a new surface for production to exploit, a new corner case for the model to stumble upon. The framework achieves impressive results now, but it’s merely delaying the inevitable accrual of technical debt, a temporary reprieve before the next iteration of ‘better’ introduces a fresh set of challenges.
What’s Next?
Skywork UniPic 3.0 delivers a predictably impressive benchmark, stitching together images with a finesse that obscures the inevitable chaos of production. The sequence modeling approach, while elegant, simply shifts the problem. Now, instead of fixing blurry pixels, the challenge becomes maintaining coherence across sequences. Every added frame is another surface for failure, another opportunity for the model to invent details that never were. Data curation, noted as critical, will become an escalating arms race against the model’s capacity to hallucinate plausible but incorrect interactions.
The focus on human-object interaction is a useful constraint, but constraints are always temporary. The real test won’t be generating likely scenes, but handling the statistically improbable ones. Edge cases, as always, will be the quiet killers. Trajectory mapping is a step towards predictability, yet the world rarely moves along perfect curves. Expect the next iterations to grapple with adversarial examples designed to expose the inherent brittleness of even the most sophisticated diffusion models.
Ultimately, this work is a testament to what can be built, not what will endure. The question isn’t whether UniPic 3.0 is ‘state-of-the-art’ today, but how quickly it will become the baseline against which new failures are measured. Tests are, after all, a form of faith, not certainty.
Original article: https://arxiv.org/pdf/2601.15664.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-01-24 17:16